/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 16 мин.
Новейший метод для ускорения кода в PyTorch 2.0 – torch.compile(), который позволяет JIT-компилировать код PyTorch в оптимизированные ядра, требуя минимальных изменений кода. JIT-компиляция (Just-In-Time compilation) — это процесс, при котором код на высокоуровневом языке преобразуется в код на низкоуровневом языке, который может быть быстрее и эффективнее исполнен процессором или графическим ускорителем. torch.compile() использует TorchDynamo и заданный бэкенд для JIT-компиляции кода PyTorch.
Разработчики PyTorch заявляют, что torch.compile() может дать прирост производительности до 50% по сравнению с обычным кодом PyTorch. Для проверки этого заявления мы проведем ряд экспериментов на разных моделях и данных, выясним, есть ли реальная выгода от использования torch.compile().
Введение
Глубокое обучение – это одна из самых перспективных и динамичных областей искусственного интеллекта, которая применяется во многих сферах — от компьютерного зрения до обработки естественного языка. Для того чтобы реализовывать сложные и эффективные модели глубокого обучения, необходимы специализированные инструменты, которые облегчают процесс разработки и обучения нейронных сетей. Одним из таких инструментов является
PyTorch – один из самых популярных и мощных фреймворков для глубокого обучения, который позволяет создавать и обучать различные нейронные сети с помощью Python. Однако, как и любой другой фреймворк, PyTorch имеет свои ограничения и недостатки, особенно в плане производительности и эффективности кода. Для того чтобы ускорить выполнение кода в PyTorch и сделать его более оптимизированным, разработчики PyTorch представили новый метод – torch.compile().
Для того чтобы понять, как работает torch.compile() рассмотрим основные его компоненты, которые отвечают за различные аспекты JIT-компиляции кода PyTorch:
- TorchDynamo – это динамический компилятор, который анализирует код PyTorch и определяет, какие части кода могут быть скомпилированы в оптимизированные ядра. Отслеживает изменения в коде и перекомпилирует его при необходимости.
- AOT AutoGrad – это система автоматического дифференцирования, которая позволяет вычислять градиенты для скомпилированных ядер. Генерирует код для обратного распространения ошибки во время компиляции, а не во время исполнения, что ускоряет процесс обучения нейронных сетей.
- PrimTorch – это набор примитивных операций, которые используются для построения скомпилированных ядер. Включает в себя базовые математические и логические операции, а также операции над тензорами, такие как сложение, умножение, свертка и т.д.
- TorchInductor – это бэкенд для JIT-компиляции кода PyTorch в оптимизированные ядра для разных устройств. Поддерживает разные бэкенды и адаптирует код PyTorch к специфике каждого устройства.
Далее подробнее рассмотрим, как работают компоненты TorchDynamo и TorchInductor и как они взаимодействуют друг с другом, чтобы обеспечить JIT-компиляцию кода PyTorch.
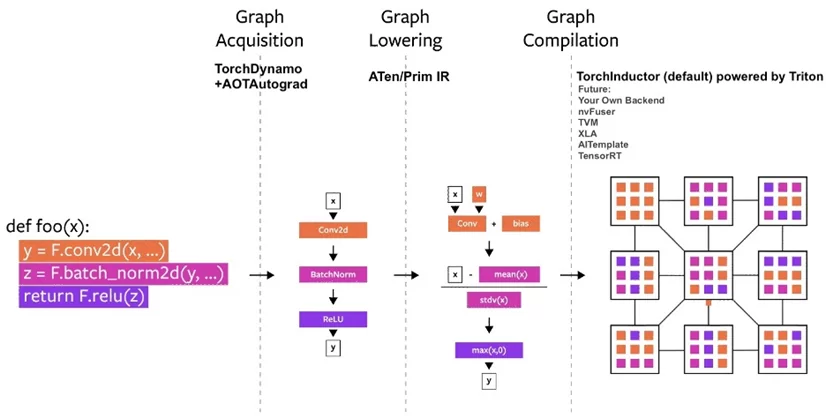
Иллюстрация взаимодействия компонентов torch.compile()
Параметры
Теперь, когда мы знаем, какие компоненты составляют torch.compile() рассмотрим, как мы можем использовать этот метод для оптимизации нашего кода PyTorch. Для этого необходимо знать, какие параметры принимает torch.compile() и как они влияют на процесс JIT-компиляции кода PyTorch. Рассмотрим эти параметры подробнее.
torch.compile() имеет следующие параметры:
• model (Callable) – это модуль/функция, которую нужно оптимизировать;
• fullgraph (bool) – это флаг, который указывает, можно ли разделить модель на несколько подграфов;
• dynamic (bool) – это флаг, который указывает, нужно ли использовать динамическое отслеживание формы;
• backend (str или Callable) – это бэкенд, который будет использоваться для оптимизации;
• mode (str) – это режим оптимизации, который может быть «default», «reduce-overhead» или «max-autotune»;
• options (dict) – это словарь параметров, которые будут переданы в бэкенд;
• disable (bool) – это флаг, который указывает, нужно ли отключить torch.compile() для тестирования
Теперь, когда мы знаем, какие параметры принимает torch.compile(), давайте посмотрим, как он влияет на скорость работы нашего кода PyTorch.
Сравнение скорости работы кода с torch.compile() и без
Для того чтобы сравнить скорость работы кода с torch.compile() и без, будем использовать три разные модели сверточных нейронных сетей: ResNet18, ResNet50 и ResNet101. Эти модели имеют разное количество слоев: 18, 50 и 101 соответственно. Обучение и тестирование моделей будет проводиться на наборе данных CIFAR10, который состоит из 60000 изображений размером 32х32 в 10 классах. Для каждой модели будет измеряться время обучения и тестирования с использованием torch.compile() и без.

Иллюстрация набора данных CIFAR10
Код для тестирования модели ResNet18
# импорт библиотек
import torch
import torchvision.models as models
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import time
# Подключение cuda, если доступно
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Загрузка модели ResNet-18 из библиотеки torchvision
resnet18 = models.resnet18(pretrained=True).to(device)
# Оптимизация модели с помощью torch.compile()
opt_resnet18 = torch.compile(resnet18)
resnet18.train()
opt_resnet18.train()
next(resnet18.parameters()).is_cuda
# Функция потерь
criterion = torch.nn.CrossEntropyLoss()
# Оптимизатор
optimizer = torch.optim.Adam(resnet18.parameters(), lr=0.001)
opt_optimizer = torch.optim.Adam(opt_resnet18.parameters(), lr=0.001)
# Загрузка датасета
transform = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224),
transforms.ToTensor()])
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainset = torch.utils.data.Subset(trainset, range(num_samples))
# Функция для обучения моделей
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True)
def train_model(model, optimizer, criterion, trainloader, device):
start = time.time()
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"\rEpoch: {epoch + 1}, Iteration: {i + 1}, Loss: {running_loss / (i + 1)}", end="")
print()
end = time.time()
print(f"Training time: {end - start} seconds")
# Вызов функций
train_model(resnet18, optimizer, criterion, trainloader, device)
train_model(opt_resnet18, opt_optimizer, criterion, trainloader, device)
Для того чтобы получить чистые и справедливые результаты эксперимента, мы перезапускаем ядро перед запуском обучения каждой модели. Это позволяет избежать влияния кэша, памяти и других факторов на скорость работы кода PyTorch.
Результаты
Для экспериментов были проведены тесты на двух разных конфигурациях, которые предоставляют разные уровни производительности и возможности для кода PyTorch.
Первая конфигурация – GPU T4 c архитектурой Turing. Вторая конфигурация – GPU A100 с архитектурой Ampere.
С помощью функции torch.compile() удалось ускорить работу модели ResNet50примерно на 5%. Эта функция позволяет компилировать модель во время выполнения и оптимизировать ее для конкретного устройства. Для модели Resnet18 эффект от компиляции был незначительным. Результаты производительности для различных размеров батчей представлены на рисунках ниже.
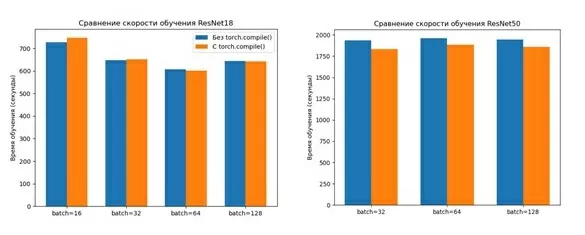
На GPU T4 компиляция модели дает небольшой прирост скорости, но не слишком значительный. Интересно, как будет работать код на более мощном GPU A100? Сможет ли функция torch.compile() показать свои преимущества на таком устройстве? Рассмотрим результаты тестов на GPU A100 и сравним их с GPU T4.
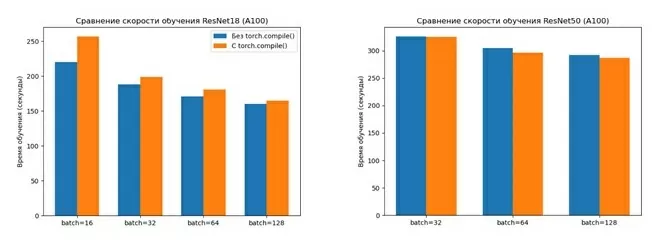
Результаты выполнения кода на A100
Как мы видим из графиков, на GPU A100 компиляция модели не дает существенного ускорения, а для ResNet18, наоборот, время выполнения кода увеличивается при использовании torch.compile. Это может быть связано с тем, что ResNet18 является достаточно простой моделью и не требует сложных оптимизаций.
Для более детального изучения влияния torch.compile() на скорость выполнения было замерено время каждой эпохи отдельно для модели ResNet101. Оказалось, что при использовании torch.compile() первая эпоха занимает в 2-3 раза больше времени, чем без него.
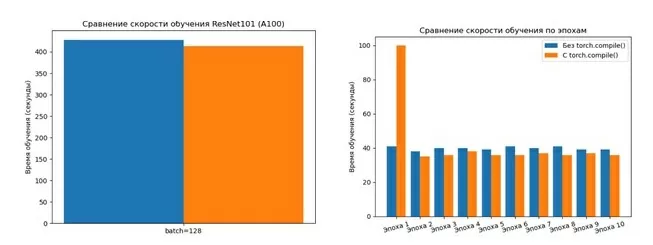
Скорость выполнения кода на каждой эпохе
Это объясняется тем, что torch.compile() требует некоторого времени для JIT-компиляции кода PyTorch в первый раз, когда он вызывается. Это приводит к увеличению времени выполнения на первой эпохе. Однако после того, как код скомпилирован, он может быть повторно использован на последующих эпохах без дополнительных затрат. Это приводит к уменьшению времени выполнения на последующих эпохах по сравнению с моделью без torch.compile(). Таким образом, torch.compile() может быть выгодным для долгосрочных задач обучения или вывода, где JIT-компиляция окупается ускорением выполнения.
Для проверки этого предположения мы увеличили количество эпох до 100 и посмотрели на среднее время выполнения за все эпохи.
В результате эксперимента было обнаружено, что первая эпоха с torch.compile() выполняется более чем в 2 раза медленнее. Остальные эпохи выполняются на 8-9% быстрее.
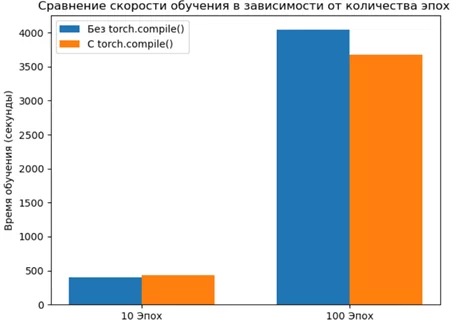
Различия в скорости обучения на 10 и 100 эпохах
На GPU A100 на 100 эпохах удалось достичь ускорения выполнения кода на ~10%
Кроме того, были проведены тесты с нейросетью VGG16, которая имеет больше слоев и параметров, чем ResNet18 и ResNet101. По результатам тестов получено ускорение на 8% при использовании torch.compile() на GPU T4.
Разработчики заявляют что их тесты показали прирост в скорости на open-source моделях Higginface, TIMM, TorchBench, как показано на рисунке ниже, ссылка на официальный ресурс:
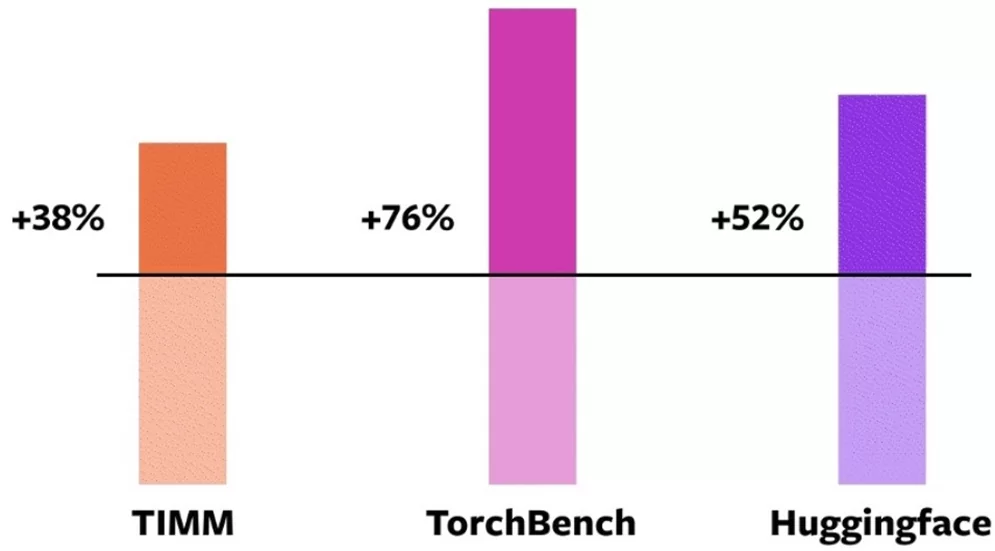
Мы же решили провести тесты на более распространённых архитектурах: ResNet, VGG. При прогоне на инференс этих моделей прироста в скорости не наблюдалось или же вовсе скомпилированные модели показывали замедление при запуске на GPU T4. Однако при запуске на кластере с GPU A100 инференс этих моделей оказался невозможен и крашился с ошибкой. К слову, на неё жалуются и другие пользователи в разделе issues репозитория.
Для этого есть несколько причин:
- На официальном сайте разработчики указывают, что компилятор compile пока ещё находится в бета-версии.
- Зависимость от “железа”. Например, у GPU настольного класса, таких как NVIDIA 3090, ускорение ниже, чем на GPU серверного класса, таких как A100, хотя архитектуры обоих графических ускорителей одинаковые.
- Разработчики также указывают на то, что среди 163 моделей с открытым исходным кодом (46 от HuggingFace Transformers, 61 из TIMM, 56 из TorchBench) torch.compile() работает в 93% случаев, т.е. ваша модель может просто не поддерживать torch.compile.
В то же время скомпилированная версия YOLOv7 отработала успешно на обеих конфигурациях, и даже наблюдался прирост скорости, хоть и не существенный. Это связано с тем, что YOLOv7 — более тяжёлая архитектура, и возможностей для оптимизации также больше.
Выводы по результатам тестов
Мы обнаружили, что torch.compile() показывает лучшие результаты, когда:
- Батч большой. Большие батчи позволяют уменьшить количество вызовов функции torch.compile() и увеличить количество данных, обрабатываемых за один вызов. Это снижает накладные расходы на компиляцию и улучшает эффективность кода.
- Модель сложная и имеет много параметров. Сложные модели требуют больше вычислений и памяти, что может приводить к узким местам в производительности. Компиляция модели позволяет оптимизировать код для конкретного устройства и сократить время выполнения операций, таких как матричное умножение, свертки и активации.
- GPU полностью занят. Полная загрузка GPU означает, что он не тратит время на ожидание данных или команд. Компиляция модели позволяет лучше использовать ресурсы GPU, такие как ядра, память и пропускную способность. Это повышает параллелизм и скорость выполнения кода.
- Эпох много. Много эпох означает, что модель обучается или выводит на большом количестве данных. Компиляция модели позволяет повторно использовать скомпилированный код на всех эпохах без дополнительных затрат. Это сокращает общее время выполнения кода и ускоряет достижение желаемого результата.
Мы убедились, что compile— мощный инструмент для оптимизации PyTorch модели и его использование ускоряет обучение. Одна из основных причин – это использование графов. Анализируя эти графы, вы можете обнаружить участки, где модель может быть оптимизирована (например, когда данные проходят через различные слои и в некоторых участках требуется большой объём памяти для вычислений), а также внести изменения, чтобы улучшить конечный результат. Далее остановимся подробно на графовых вычислениях, за счёт чего и получается это ускорение.
Графовые вычисления в PyTorch 2.0
Один из главных вопросов- почему мы должны использовать torch.compile() вместо уже существующих решений компилятора PyTorch, таких как TorchScript или FX Tracing? Выше мы увидели, как с помощью compile возможно ускорить время обучения, за счёт чего это происходит?
Прежде всего, преимущество torch.compile() заключается в его способности обрабатывать код на Python с минимальными изменениями в существующем коде.
TorchScript может обрабатывать поток управления, зависящий от данных, но это решение сопряжено с собственным набором проблем. А именно, TorchScript может потребовать значительных изменений кода и вызвать ошибки при использовании неподдерживаемого Python кода.
В то время как в compile подход основан на функции CPython, известной как Frame Evaluation API, которая может безопасно и правильно захватывать графы в 99% случаев без дополнительных накладных расходов. Другие предыдущие решения компилятора, такие как TorchScript и FX Tracing, нуждаются в помощи для захвата графов даже в 50% случаев, и это тоже с дополнительными накладными расходами.
Далее более подробно разберём TorchDynamo и TorchInductor — одними из главных нововведений в новой версии PyTorch.
TorchDynamo
TorchDynamo — это новейшее компиляторное решение PyTorch, которое использует компиляцию JIT (Just In Time) для преобразования обычной программы Python в FX Graph. FX Graph — это промежуточное представление вашего кода, которое можно дополнительно скомпилировать и оптимизировать. TorchDynamo переписывает байт-код на Python, чтобы извлекать последовательности операций PyTorch в FX Graph, который затем своевременно компилируется с помощью настраиваемого бэкенда, чтобы получить лучшее из обоих миров — удобство использования и производительность.
TorchDynamo позволяет легко экспериментировать с различными бэкендами компилятора с помощью однострочного декоратора torch._dynamo.optimize().
@torch._dynamo.optimize('inductor')
def foo(x):
...
TorchDynamo следует сочетать с бэкенд частью, которая может эффективно преобразовывать FX Graph в быстрый машинный код, чтобы ускорить программы на PyTorch 2.0. Однако многое теряется при экспорте FX Graph в различные существующие бэкенд части. Некоторые из них имеют принципиально отличные от PyTorch модели выполнения, а другие оптимизированы только для инференса, а не для обучения. Поэтому важно выбрать правильный бэкенд, исходя из вашей задачи.
Код для создания FX Graph:
1. Происходит сохранение оптимизированного FX Graph, который получаем с помощью compile.
# Объявление функции
def fn(x, y):
a = torch.sin(x)
b = torch.cos(y)
return a + b
# Использование compile для отрисовки оптимизированного графа
new_fn = torch.compile(fn, backend='inductor',
options = {'trace.graph_diagram': True,
'trace.enabled': True})
# Входные данные
input_tensor = torch.randn(10000, requires_grad=True).to('cuda:0')
# Подача данных на вход в модель
out = new_fn(input_tensor, input_tensor).sum().backward()
# Импорт библиотек для визуализации графов
from torch.fx import passes, _symbolic_trace
model = _symbolic_trace(fn)
2. Выгружаем не оптимизированный FX Graph для возможности их сравнения
# Выгрузка не оптимизированного графа в файл с расширением .svg
g = passes.graph_drawer.FxGraphDrawer(model, 'fn')
with open('unoptimized_graph.svg', 'wb') as f:
f.write(g.get_dot_graph().create_svg())Результатом является код FX IR и графическая диаграмма, показывающая функцию: sin(x) + cos(y)

TorchInductor
Для введения в TorchInductor лучше всего будет процитировать разработчиков данного бэкенда: «У этого выбора есть свои плюсы и минусы, но мы обнаружили, что этот выбор значительно увеличивает скорость и продуктивность разработчиков.
Мы потратили большую часть нашего времени на то, чтобы убедиться, что основная инфраструктура способна поддерживать подавляющее большинство PyTorch, в том числе: представления, косвенные записи, косвенные чтения, объединение/сокращения, условное выполнение, горизонтальное/вертикальное слияние. До сих пор мы не тратили слишком много времени на оптимизацию какого-либо одного шаблона и сосредоточились на общих оптимизациях с широкими преимуществами». То есть данный бэкенд наиболее универсальный, именно поэтому используется в compile по умолчанию.
TorchInductor — это новый бэкенд компилятор, которая компилирует FX графы, сгенерированные TorchDynamo, в оптимизированные ядра C++/Triton.
Когда мы используем torch.compile и GPU, то включается в работу Triton. Если же CPU, то уже C++/OpenMP. Всё это происходит автоматически.
Triton— это новый язык программирования, который обеспечивает гораздо более высокую производительность, чем CUDA, но с возможностью превзойти производительность высокооптимизированных библиотек, таких как cuDNN, с помощью чистого и простого кода. Triton поддерживает графические процессоры NVIDIA и быстро набирает популярность в качестве замены написанных вручную ядер CUDA.
C++/OpenMP — широко распространённая спецификация для написания параллельных ядер. OpenMP обеспечивает модель параллельного выполнения с разделением работы и обеспечивает поддержку процессоров. C++ также является интересной целью, поскольку это язык с высокой степенью переносимости, который может обеспечивать экспорт на более «экзотические» периферийные устройства и аппаратные архитектуры.
Цепочка последовательности действий PyTorch при выборе CPU и GPU в compile:
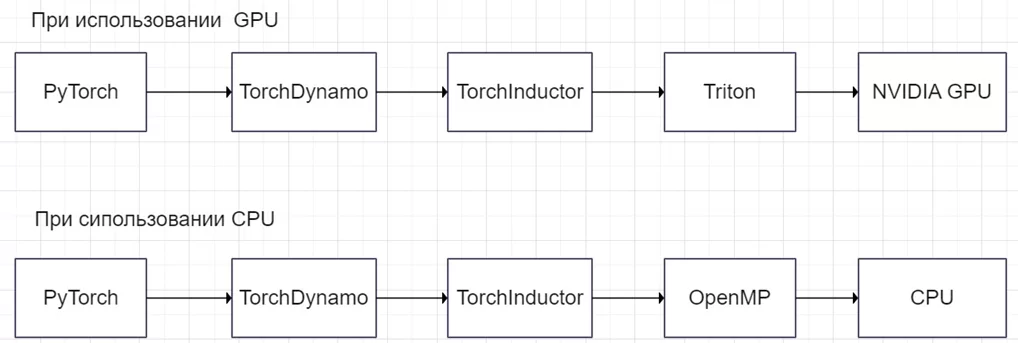
Ранее мы подробно разобрали за счёт чего compile позволяет ускорить обучение нейронной сети. Однако если мы используем CPU, то с помощью oneDNN Graph возможно уменьшить время на инференсе. Остановимся на нем более подробно.
oneDNN Граф
oneDNNграфовый API добавляет в oneDNN настраиваемый API, чтобы расширить возможности оптимизации генерации кода на оборудовании Intel® AI. oneDNN автоматически распознает деления графа, которые должны быть ускорены слиянием. Слияния концентрируются на объединении ресурсоемких вычислительных процессов, таких как свёртка, матричное умножение и их соседние операции, и тем самым может значительно повысить производительность инференса. oneDNN Граф получает граф модели и идентифицирует кандидатов для слияния операторов с учётом формы ввода примера. Модель должна быть JIT-трассирована с использованием примера входных данных. Затем ускорение будет наблюдаться после пары итераций прогрева для входных данных той же формы, что и примерный ввод.
oneDNN фокусируется на оптимизации графов, связанных с оператором.
Если вы планируете использовать обученную нейронную сеть, например, на компьютере или даже в мобильных устройствах, автомобиле, роботах, то с помощью oneDNN графа возможно ускорить время выполнения модели.
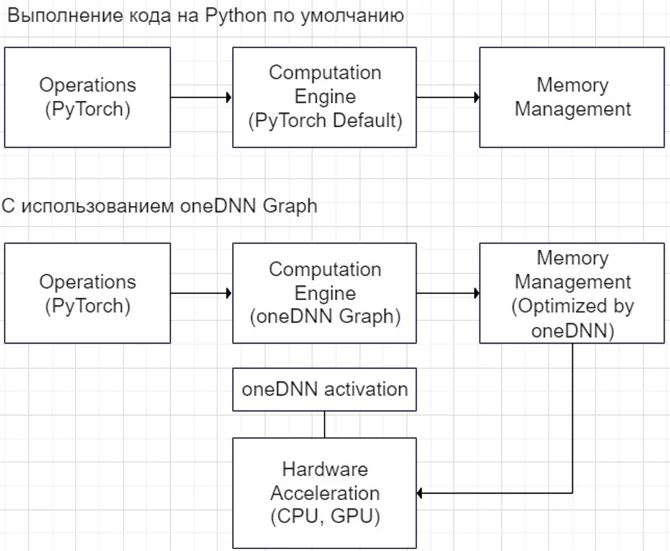
К сожалению, в настоящее время можно оптимизировать только для инференса и поддерживаются только типы данных `BFloat16` и `Float32`.
Примеры фрагментов кода, которые будут рассмотрены далее, предназначены для resnet50, но их вполне можно расширить для использования oneDNN Graph с пользовательскими моделями.
Для использования oneDNNGraph API требуется всего одна дополнительная строка кода для логического вывода с помощью
# Для активации oneDNN Graph требуется всего одна строчка кода
torch.jit.enable_onednn_fusion(True)
# Размер тестовых данных должен быть такого же размера как и ожидает модель
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testset = torch.utils.data.Subset(testset, range(num_samples))
sample_input = [testset[0][0]]
# Использование "resnet50" модели из модуля torchvision продемонстрировано в качестве примера,
# но в действительности, она может быть легко заменена на любую другую
model = getattr(torchvision.models, 'resnet50').eval()
# Трассировка модели с тестовыми данными на входе
traced_model = torch.jit.trace(model, sample_input)
# Вызов torch.jit.freeze
traced_model = torch.jit.freeze(traced_model)
После JIT-трассировки модели с входным образцом её можно использовать для вывода после пары прогонов прогрева.
with torch.inference_mode():
# Несколько прогонов для "прогрева"
traced_model(*sample_input)
traced_model(*sample_input)
# изменение в скорости будут заметны после нескольких прогонов
traced_model(*sample_input)
Хотя JIT слияние для oneDNN Graph также поддерживает вывод с типом данных `BFloat16`, преимущество в производительности с oneDNN Graph проявляется только на машинах с архитектурой набора инструкций AVX512_BF16 (ISA).
Следующие фрагменты кода служат примером использования типа данных `BFloat16` для инференса с помощью oneDNN Graph:
# Режим AMP для JIT включён по умолчанию и отличается от своего аналога "eager mode"
torch._C._jit_set_autocast_mode(False)
with torch.inference_mode(), torch.cpu.amp.autocast_mode(cache_enabled=False, dtype=torch.bfloat16):
model = torch.jit.trace(model, (sample_input))
model = torch.jit.freeze(model)
model(sample_input)
model(sample_input)
model(sample_input)
Заключение
В данной публикации мы разобрали нововведения в PyTorch 2.0 и более подробно разобрали новый компилятор моделей torch.compile, а также провели тесты. На инференсе прирост в скорости наблюдается не таким высоким, как при обучении, но это связано с тем, что в качестве примера мы использовали не очень сложные модели, в то время как заявляют разработчики, особенный прирост должен наблюдаться на тяжёлых сетях по типу трансформеров и на современных архитектурах. В среднем на моделях с архитектурами ResNet и VGG ускорение примерно на уровне 10%.