/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Всем хорошо известно, что нейронные сети (НС) и, в частности, модели компьютерного зрения хорошо справляются с конкретными задачами, но зачастую не могут быть использованы в задачах, которым они не обучались. К примеру, модель, которая хорошо работает с информацией о продуктах питания, может не справляться с анализом снимков спутника.
CLIP – модель от OpenAI претендует на то, чтобы закрыть этот пробел.
Что подразумевается под классификацией? Имеется набор примеров, каждому из которых соответствует категория. Количество категорий ограничено. Модель обучается различать «кошек» и «собак», но при добавлении нового класса «дельфин» нам придется добавить примеры с изображением дельфинов и обучить модель заново, а хорошо работающей моделью признаем ту, которая верно определит на изображении дельфина. Однако CLIP устроен иначе и результатом будет вероятность того, что это изображение соответствует категории «кошек», «собак» или «дельфинов».
Предлагаю рассмотреть, как можно использовать CLIP для классификации фотографий людей. В моем примере представлена классификация известных людей. Вы их, конечно, узнаете, но для примера я изменю имена. Установим и запустим CLIP от PyTorch:
import subprocess
CUDA_version = [s for s in subprocess.check_output(["nvcc", "--version"]).decode("UTF-8").split(", ") if s.startswith("release")][0].split(" ")[-1]
print("CUDA version:", CUDA_version)
if CUDA_version == "10.0":
torch_version_suffix = "+cu100"
elif CUDA_version == "10.1":
torch_version_suffix = "+cu101"
elif CUDA_version == "10.2":
torch_version_suffix = ""
else:
torch_version_suffix = "+cu110"
!pip install torch==1.7.1{torch_version_suffix} torchvision==0.8.2{torch_version_suffix} -f https://download.pytorch.org/whl/torch_stable.html ftfy regex
import numpy as np
import torch
print("Torch version:", torch.__version__)
!pip install gdown
Скопируем репозитории CLIP:
!git clone https://github.com/openai/CLIP.git
import sys
from pathlib import Path
clip_dir = Path(".").absolute() / "CLIP"
sys.path.append(str(clip_dir))
print(f"CLIP dir is: {clip_dir}")
import clip
Установим предобученную модель:
import os
device = "cuda" if torch.cuda.is_available() else "cpu"
model, transform = clip.load("ViT-B/32", device=device)
print(f"Model dir: {os.path.expanduser('~/.cache/clip')}")
Подготовим исходные данные. Для примера я взяла фотографии трех известных людей (2 женщины, 1 мужчина), по 4 — 6 изображений каждого из них. Фотографии хранятся в папках с именами Виктор, Тамара и Ирина.
!gdown https://ссылка_на_архив_clip
!unzip clip_people.zip; rm clip_people.zip
Downloading...
From: https://ссылка_на_архив_clip
To: /content/clip_people.zip
3.07MB [00:00, 62.4MB/s]
Archive: clip_people.zip
creating: clip_people/
creating: clip_people/Viktor/
extracting: clip_people/Viktor/1.jpg
extracting: clip_people/Viktor/2.jpg
extracting: clip_people/Viktor/3.jpg
extracting: clip_people/Viktor/4.jpg
extracting: clip_people/Viktor/5.jpg
extracting: clip_people/Viktor/6.jpg
creating: clip_people/Tamara/
extracting: clip_people/Tamara/1.jpg
extracting: clip_people/Tamara/2.jpg
extracting: clip_people/Tamara/3.jpg
extracting: clip_people/Tamara/4.jpg
extracting: clip_people/Tamara/5.jpg
extracting: clip_people/Tamara/6.jpg
creating: clip_people/Irina/
extracting: clip_people/Irina/1.jpg
extracting: clip_people/Irina/2.jpg
extracting: clip_people/Irina/3.jpg
extracting: clip_people/Irina/4.jpg
Для классификации изображений определим классы, которые могут быть представлены в виде текста, описывающего изображение. Например, «это изображение артиста». В этом случае артист и есть метка класса. Изображения, которые я хочу протестировать, хранятся в папках с именами классов:
import os
# images we want to test are stored in folders with class names
class_names = sorted(os.listdir('./clip_people/'))
class_to_idx = {class_names[i]: i for i in range(len(class_names))}
class_names
['Viktor', 'Tamara', 'Irina']
class_captions = [f"An image depicting a {x}" for x in class_names]
class_captions
['An image depicting a Viktor',
'An image depicting a Tamara',
'An image depicting a Irina']
Далее токенизируем текст и вычисляем вложения из токенов
text_input = clip.tokenize(class_captions).to(device)
print(f"Tokens shape: {text_input.shape}")
with torch.no_grad():
text_features = model.encode_text(text_input).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
print(f"Text features shape: {text_features.shape}")
Для корректного отображения изображений воспользуемся набором данных ImageFolder от PyTorch и нормализуем снимки:
image_mean = torch.tensor([0.48145466, 0.4578275, 0.40821073]).to('cpu')
image_std = torch.tensor([0.26862954, 0.26130258, 0.27577711]).to('cpu')
def denormalize_image(image: torch.Tensor) -> torch.Tensor:
image *= image_std[:, None, None]
image += image_mean[:, None, None]
return image
import matplotlib.pyplot as plt
from PIL import Image
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
dataset = ImageFolder(root="./clip_people", transform=transform)
data_batches = DataLoader(dataset, batch_size=len(dataset), shuffle=False)
Выведем все изображения из набора данных:
plt.figure(figsize=(10, 10))
for idx, (image, label_idx) in enumerate(dataset):
cur_class = class_names[label_idx]
plt.subplot(4, 4, idx+1)
plt.imshow(denormalize_image(image).permute(1, 2, 0))
plt.title(f"{cur_class}")
plt.xticks([])
plt.yticks([])
plt.tight_layout()

Выполняем классификацию с помощью готовых меток. Считаем все изображения и истинные метки:
image_input, y_true = next(iter(data_batches))
image_input = image_input.to(device)
with torch.no_grad():
image_features = model.encode_image(image_input).float()
def show_results(image_features, text_features, class_names):
# depends on global var dataset
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
k = np.min([len(class_names), 5])
# top_probs, top_labels = text_probs.cpu().topk(k, dim=-1)
text_probs = text_probs.cpu()
plt.figure(figsize=(26, 16))
for i, (image, label_idx) in enumerate(dataset):
plt.subplot(4, 8, 2 * i + 1)
plt.imshow(denormalize_image(image).permute(1, 2, 0))
plt.axis("off")
plt.subplot(4, 8, 2 * i + 2)
y = np.arange(k)
plt.grid()
plt.barh(y, text_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
# plt.yticks(y, [class_names[index] for index in top_labels[i].numpy()])
plt.yticks(y, class_names)
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()
show_results(image_features, text_features, class_names)
Вы можете заметить, что CLIP не очень хорошо справился с этими метками – правильно распознаны только 5 изображений из 16. Возможно, дело в незнакомых CLIP именах. Давайте поэкспериментируем и посмотрим, как это повлияет на результаты. Я изменю метки на более распространенные иностранные имена.
class_names = ['John', 'Kate', 'Jessica']
class_captions = [f"An image depicting a {x}" for x in class_names]
text_input = clip.tokenize(class_captions).to(device)
with torch.no_grad():
text_features = model.encode_text(text_input).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
show_results(image_features, text_features, class_names)

У этого эксперимента результат лучше предыдущего – 13 из 16 изображений распознаны верно.
Проведем еще один эксперимент – классифицируем мужчин и женщин.
class_names = ['male', 'female']
class_captions = [f"An image depicting a {x}" for x in class_names]
text_input = clip.tokenize(class_captions).to(device)
with torch.no_grad():
text_features = model.encode_text(text_input).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
show_results(image_features, text_features, class_names)
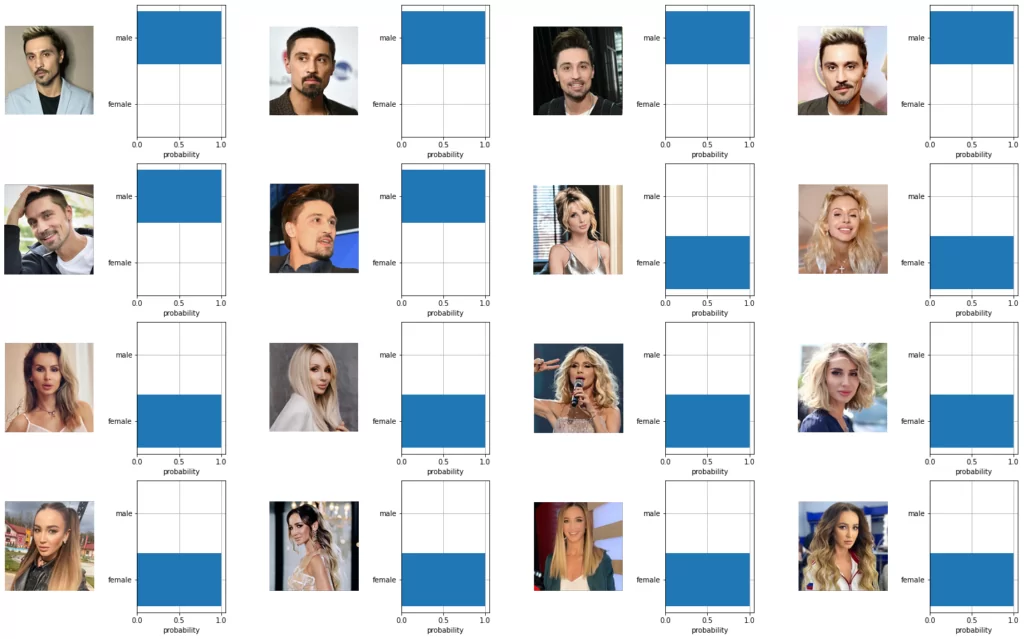
Результат этого эксперимента еще лучше – все 16 изображений распознаны правильно. Кроме уже продемонстрированных экспериментов по распознаванию людей и классификации по их полу, CLIP поможет определить вероятность присутствия различных предметов на изображениях (микрофон, гарнитура, украшения, очки и т.д.), а также их количество. На мой взгляд, это важная особенность CLIP может найти свое применение в практической деятельности аудитора: различить пустые страницы, схемы, диаграммы, технические чертежи; установить есть ли на изображении человека ключи, бейдж, медицинская маска и еще другие детали, распознавание которых в ручную отняло бы слишком много трудовых ресурсов.