/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Недавно я принял участие в конкурсе, результатом которого является модель для распознавания болезни тропического растения Маниока. Это растение содержит ядовитую синильную кислоту, а после обработки становится важным продовольственным сырьем. На высокий урожай Маниоки рассчитывают более 800 млн. жителей Африки, но этот клубнеплод подвержен различным заболеваниям.
В странах, где выращивается маниока, фермеры обязаны обращаться к сельскохозяйственным экспертам для визуального осмотра и диагностики растений. Это трудно и дорого. Но сотовые телефоны с минимальными характеристиками фотоаппарата африканским фермерам доступны!
В нашем распоряжении набор данных из 21 тыс. размеченных изображений, собранных в ходе регулярного опроса в Уганде. Большинство изображений были получены от фермеров, фотографирующих свои сады.
Задача состоит в том, чтобы классифицировать каждое изображение маниоки по пяти категориям – четыре вида болезней или здоровое растение. С помощью разработанной модели фермеры смогут быстро идентифицировать больные растения, а, соответственно, успеют спасти посевы.
Приступим к реализации. Для выполнения задачи будет использован фреймворк машинного обучения для языка python – PyTorch. Используем его алгоритмы и дополнительные библиотеки для работы с изображениями.
import numpy as np
import pandas as pd
import json
from PIL import Image
import os
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
Определяем параметры для подготовки к обучению будущих моделей. Зададим число эпох, размер пакета, размер картинок и пути к тренировочным и тестовым данным.
BATCH = 32
EPOCHS = 40
LR = 0.001
IM_SIZE = 512
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#DEVICE = torch.device("cpu")
TRAIN_DIR = '../input/cassava-leaf-disease-classification/train_images/'
TEST_DIR = '../input/cassava-leaf-disease-classification/test_images/'
Загрузим словарь с возможными болезнями растений, также сформируем сет тестовых и тренировочных данных.
labels = json.load(open("../input/cassava-leaf-disease-classification/label_num_to_disease_map.json"))
print(labels)
train = pd.read_csv('../input/cassava-leaf-disease-classification/train.csv')
X_Train = train['image_id'].values
Y_Train = train['label'].values
X_Test = [name for name in (os.listdir(TEST_DIR))]
train.head()
Болезни растений и данные для тренировочного датасета выглядят следующим образом:
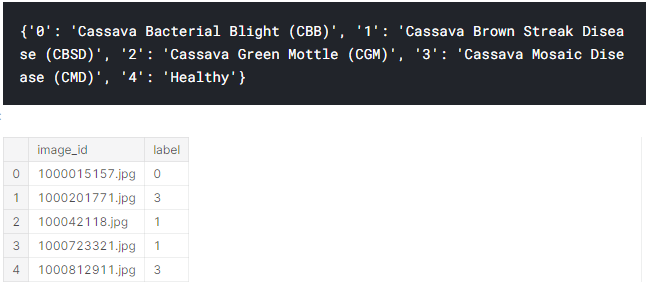
Создадим класс GetData, который наследуется от класса torch.utils.data.Dataset. Переопределим методы __len и __getitem, чтобы при вызове соответствующих методов мы получали объем выборки и пару значение-метка. Но для начала зададим параметры для обработчика фотографий – для тренировочных и тестовых данных.
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
Тогда класс выглядит следующим образом:
class GetData(Dataset):
def __init__(self, Dir, FNames, Labels, Transform):
self.dir = Dir
self.fnames = FNames
self.transform = Transform
self.lbs = Labels
def __len__(self):
return len(self.fnames)
def __getitem__(self, index):
x = Image.open(os.path.join(self.dir, self.fnames[index]))
if "train" in self.dir:
return self.transform(x), self.lbs[index]
elif "test" in self.dir:
return self.transform(x), self.fnames[index]
Подготовим данные при помощи класса GetData и передадим их в класс torch.utils.data.DataLoader, указывая размер подаваемых данных в модель за один раз.
trainset = GetData(TRAIN_DIR, X_Train, Y_Train, data_transforms['train'])
trainloader = DataLoader(trainset, batch_size=BATCH, shuffle=True, num_workers=4)
testset = GetData(TEST_DIR, X_Test, None, data_transforms['test'])
testloader = DataLoader(testset, batch_size=1, shuffle=False, num_workers=4)
Теперь можно приступать к написанию метода, который будет отвечать за обучение наших моделей. Переводим модель в режим обучения. Внутри тела внутреннего цикла будем перебирать пакеты, которые нам отдает итератор trainloader. Каждый батч перемещаем на то устройство, которое было указано в начале программы. Далее обнуляем градиент у оптимизатора, т.к. будет накопление градиента после каждой итерации (установлено по умолчанию в PyTorch). После этого делаем основные три действия: совершаем прямой проход по нейросети, считаем значение для функции потерь и на основе этого делаем градиентный шаг. Выводим значение функции потерь на тренировочной выборке.
def trainer(model, epochs)
for epoch in range(epochs):
tr_loss = 0.0
model = model.train()
for i, (images, labels) in enumerate(trainloader):
images = images.to(DEVICE)
labels = labels.to(DEVICE)
logits = model(images)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
tr_loss += loss.detach().item()
model.eval()
print('Epoch: %d | Loss: %.4f'%(epoch, tr_loss / i))
Для обучения возьмём три модели: ResNet34, ResNet50 и ResNext50_32x4d. Настроим линейное преобразование входящих данных, указываем устройство, выбранное в начале. Используем перекрестную энтропию для классификации фотографий и оптимизатор Adam.
Настройки для ResNet34:
resnet34 = torchvision.models.resnet34()
_final_fc = resnet34.fc.in_features
resnet34.fc = nn.Linear(_final_fc, 5, bias=True)
resnet34 = resnet34.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(resnet34.parameters(), lr=LR, weight_decay=1e-5)
trainer(resnet34, EPOCHS)
Настройки для ResNet50:
resnet50 = torchvision.models.resnet50()
_final_fc = resnet50.fc.in_features
resnet50.fc = nn.Linear(_final_fc, 5, bias=True)
resnet50 = resnet50.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(resnet50.parameters(), lr=LR, weight_decay=1e-5)
trainer(resnet50, EPOCHS)
Настройки для ResNext50_32x4d:
resnext50_32x4d = torchvision.models.resnext50_32x4d()
_final_fc = resnext50_32x4d.fc.in_features
resnext50_32x4d.fc = nn.Linear(_final_fc, 5, bias=True)
resnext50_32x4d = resnext50_32x4d.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(resnext50_32x4d.parameters(), lr=LR, weight_decay=1e-5)
trainer(resnext50_32x4d, EPOCHS)
После обучения моделей, приступаем к тестированию моделей. Тут главный вопрос: «А зачем три модели?». Три модели используются для усреднения полученных значений после обучения для более точного предсказания моделью диагноза маниоки.
Перебираем тестовый датасет и каждую запись отправляем в обученную модель. После складываем все три построенные матрицы и делим их на 3 для получения усредненных значений и на основе этого делаем вывод о том, какой диагноз ставить маниоке, и добавляем в общий список для итогового датафрейма, который будет собран в csv-файл.
s_ls = []
with torch.no_grad():
for image, fname in testloader:
image = image.to(DEVICE)
logits_resnext50_32x4d = resnext50_32x4d(image)
logits_resnet50 = resnet50(image)
logits_resnet34 = resnet34(image)
logits = (logits_resnext50_32x4d + logits_resnet50 + logits_resnet34) / 3
ps = torch.exp(logits)
_, top_class = ps.topk(1, dim=1)
for pred in top_class:
s_ls.append([fname[0], pred.item()])
sub = pd.DataFrame.from_records(s_ls, columns=['image_id', 'label'])
sub.to_csv("submission.csv", index=False)
По окончанию работы, формируем csv-файл, в котором будут указаны имена фотографий маниоки и её диагноз.
В заключении стоит отметить, что задача выполнена успешно, поскольку точность классификации, основываясь на результатах конкурса, превысила 80%. Это делает результаты проделанной работы значимыми. Благодаря данному алгоритму фермеры смогут снизить свои потери и в автоматическом режиме начать выявление болезней.
Так же, этот алгоритм можно использовать не только для данной задачи, но, в целом и для других задач computer vision, визуальной классификации, встречающихся повсеместно в современном мире и, не без исключений, в аудите.