/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Рутинные задачи часто связаны с прочтением разного вида документов, многие из них растянуты на несколько страниц, хотя суть каждого можно было бы изложить коротко, используя всего несколько предложений. Особенную боль составляет прочтение текстов юридического или строгого канцелярского стиля, когда используется много нагруженных предложений. К таким текстам очень удобно иметь краткие содержания.
Задача создания краткой аннотации текстов решается двумя способами:
- Абстрактивный подход – генерация нового текста, на основе полученной информации
- Экстрактивный подход – использование слов/словосочетаний, ранее использованных в текстах
Преимущество экстрактивного подхода заключается в том, что вероятность получить грамматически не верный текст снижается, если документ написан грамотным автором. Модель не создает новых предложений, только отбирает существующие.
Основной минус такого подхода – разметка. Если ваши тексты написаны по принципу пирамиды Минто, то вам скорее всего повезло, разметку можно провести механически, выделив первое или несколько первых предложений в качестве референсного саммари.

В этой статье мы рассмотрим экстрактивный подход, и как его можно воплотить при помощи модифицированного трансформера – BERTSum.
В чем отличие BERTSum от простого BERT’a?
На самом деле, решение сводится к задаче бинарной классификации, должно ли то или иное предложение войти в итоговый вывод или нет. Вся разница заключается в том, как происходит кодировка и размер batch для обучения.
При разметке данных для BERT используются два служебных токена:
- [CLS] – разделитель для классифицируемых объектов
- [SEP] – разделитель между токенами
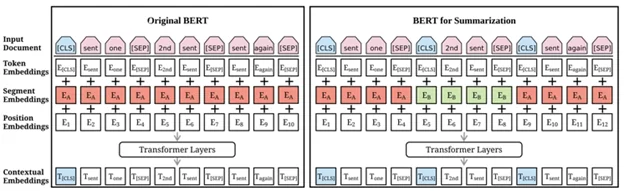
Таким образом, если мы решаем задачу классификации текстов, то при разметке нам необходимо отделить предложения друг от друга и поставить токен классификации в начале текста.
Если же мы решаем задачу классификации предложений, то помимо отделения предложений друг от друга токеном [SEP] необходимо у каждого проставить токен [CLS].
#HOWTOCODE:
В нашей задаче мы столкнулись с длинными текстами документов, тем не менее внутри каждого из них можно было выделить блок, который по структуре соответствовал пирамиде, поэтому в качестве разметки мы использовали 1-3 исходных предложения в зависимости от длины текста.
Мы отобрали те блоки, которые написаны подходящим образом под наши критерии, разметили их механически, а затем сделали shuffle предложений – перемешали, чтобы классификатор не запомнил, что всегда нужно брать только первые предложения. Этот шаг нужен был для того, чтобы потом можно было использовать эту модель для документа целиком, передавая модели на вход блоки предложений.
Итак, перейдем к описанию кода, в качестве фреймворка мы будем использовать PyTorch.
Начнем с импорта библиотек:
import torch
from torch.optim import Adam
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from transformers import BertTokenizer, BertConfig
from transformers import AdamW, BertForSequenceClassification
Далее необходимо проверить доступно ли GPU, тренировка будет происходить при помощи графического процессора:
if torch.cuda.is_available():
device = torch.device("cuda", 1)
print('GPU avaliable')
else:
device = torch.device("cpu")
print("GPU Unavaliable")
Если вывод показал, что GPU недоступен, проверьте настройки и версию CUDA.
Далее с репозитория DeepPavlov необходимо скачать версию русского трансформера: Ru-BERT.
Затем пропишем пути до конфигов и исходников:
spec = importlib.util.spec_from_file_location('BertTokenizer', '/data/bert_data/transformers/transformers/tokenization_bert.py')
Path_pretrained = {
'vocab': '/data/bert_data/rubert_cased_L-12_H-768_A-12_v1/vocab.txt',
'json': '/data/bert_data/rubert_cased_L-12_H-768_A-12_v1/bert_config.json',
'bin': '/data/bert_data/rubert_cased_L-12_H-768_A-12_v1/pytorch_model.bin',
}
И иницициализируем токенизатор:
tokenizer = BertTokenizer.from_pretrained(Path_pretrained['vocab'], do_lower_case=True)Для того, чтобы разбить текст на предложения мы использовали модуль ru_sent_tokenizer. Более подробно с ним можно познакомиться тут.
Далее каждому предложению мы присвоим два служебных токена, о которых говорили выше, чтобы BERT смог ориентироваться на объекты классификации:
df['sentenized'] = df['sentenized'].map(lambda x: "[CLS] " + x + " [SEP]")Далее необходимо закодировать каждое предложение из текста в последовательность символов.
tokenized_texts = [tokenizer.tokenize(sent) for sent in df['sentenized'].to_list()]
df['tokenized'] = tokenized_texts_train
df = df['tokenized'].map(lambda x: [tokenizer.convert_tokens_to_ids(y) for y in x])
В чем особенность кодировки, которую использует BERT: в трансформере используется принцип кодировки BPE. У Александра Дьяконова есть замечательная статья, поясняющая принцип работы токенизации. Основное преимущество такого подхода заключается в том, что не остаются так называемые OOV-токены (out of vocabulary).
Определим параметры инициализации модели, переместим расчеты на GPU и настроим оптимизатор.
torch.cuda.empty_cache()
model = BertForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=Path_pretrained['json'],
state_dict=torch.load(Path_pretrained['bin']),
num_labels=2
)
model.to(device)
model.config.output_attentions = True
param_optimizer = list(model.named_parameters())
no_decay = ["LayerNorm", "layer_norm", "bias"]
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.00}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=1e-5)
Далее идет блок тренировки самой модели. На вход каждый раз мы подаем только один текст, в котором модель должна определить предложения для использования в кратком содержании. Чтобы унифицировать вход, можно использовать токен [PAD] и привести все тексты к единой длине по предложениям.
def pad_sequences(arr, len_, dtype=np.long):
arr = np.array(arr, dtype=dtype)
if arr.shape[0] >= len_:
return arr[:len_]
return np.concatenate((arr, np.zeros(len_ - arr.shape[0], dtype=dtype)))
В нашем случае такой подход показал результат хуже, по сравнению с тем, что мы разбили выборку на бины по n предложений. Так в первой группе оказались тексты по 3 предложения, во второй по 5, в третьей по 7 и так далее.
Код тренировки и валидации модели, вместе с сохранением, а также инференсом можно посмотреть по ссылке.
Оценка алгоритма:
Оценка качества отобранного текста обычно производится при помощи ROUGE-метрики.
ROUGE – оценка качества проведенной суммаризации, отдающая приоритет на полноте. Идейно метрика показывает, насколько сгенерированный реферат покрывает оригинальный текст.
Для ее оценки вам необходимо иметь референсное саммари, написанное экспертом в области, для которой проводилось аннотирование текстов. Также важно учитывать, что никакой критерий информативности в метрику не заложен, а это значит, что, даже избежав грамматических ошибок, текст может получиться не связный. Поэтому рекомендуется отдавать на вычитку экспертам результаты работы моделей для классификации информативен текст или нет.
Вывод:
Среди подходов экстрактивной суммаризации BERT дает самый настраиваемый результат, есть возможность передать модели тренировочные данные. Иными словами, мы можем влиять на вывод, чего нельзя сделать в TextRank, LexRank.
Несмотря на то, что BERTSum в плане экстрактивной суммаризации является SOTA решением, очень важно уделить внимание исходным данным и разметке. Экстрактивная суммаризация хороший подход, если вы можете провести разметку текстов, если ваши тексты обладают структурой, которую вы можете парсить. В противном случае использовать этот метод достаточно затратно по ресурсам (долго и дорого), также процесс очень субъективный, каждый эксперт будет создавать свой набор предложений для аннотирования. Более того, надо рассчитывать на то, что человека никак нельзя исключить из pipeline задачи, так как он должен оценивать итоговую информативность текстов.