/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Иногда цвет отражает какое-либо решение/ результат. Красный – плохо, зеленый – все в порядке. Анализируя отчеты с подобными цветовыми индикаторами – «светофорами», аудиторам приходилось просматривать каждый документ вручную. Но объемы информации растут в колоссальном темпе, и ручная обработка уже не позволяет полно оценить тот или иной вопрос, когда требуется проверить тысячи файлов. Какая технология позволит преобразовать значение светофора в текст?
В качестве входных данных использовались вручную размеченные изображения индикаторов из отчетов. Индикатор обычно представляет из себя трехсекционный блок с акцентом на свой цвет. Ситуацию осложняло то, что не существует единого подхода к оформлению и ориентации данных маркеров:
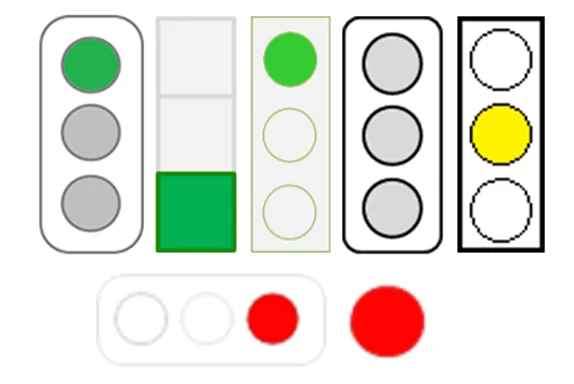
 Кроме того, анализируемые отчеты наполнены иными графическими объектами, и необходимо в автоматическом режиме отличать светофоры от других изображений. Поэтому для решения задачи нами были апробированы алгоритмы архитектуры сверточной нейронной сети (CNN), результаты которой позволили преобразовать каждый отчет в структурированную таблицу и интерпретировать ее значения.
Кроме того, анализируемые отчеты наполнены иными графическими объектами, и необходимо в автоматическом режиме отличать светофоры от других изображений. Поэтому для решения задачи нами были апробированы алгоритмы архитектуры сверточной нейронной сети (CNN), результаты которой позволили преобразовать каждый отчет в структурированную таблицу и интерпретировать ее значения.
Сначала предстояло определить архитектуру для будущей сети. Чтобы избежать переобучения ввиду небольшого числа признаков анализируемых светофоров, было принято решение остановиться на относительно простой архитектуре:
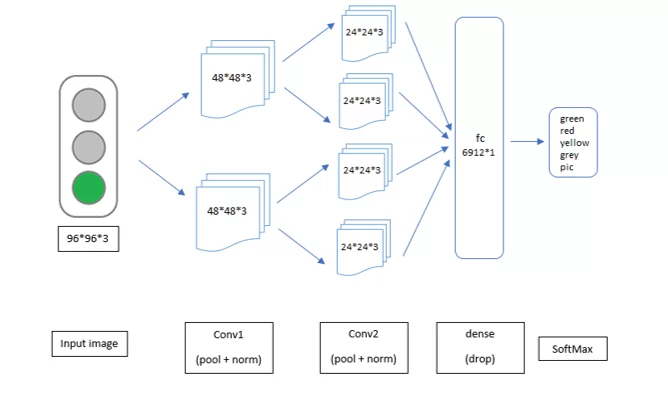
Эта же нейронная сеть, но на языке Python с применением фреймворка torch будет иметь следующий вид:
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.layer1 = Sequential(
Conv2d(3, 6, kernel_size=5, stride=1, padding=2),
BatchNorm2d(6),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2))
self.layer2 = Sequential(
Conv2d(6, 12, kernel_size=5, stride=1, padding=2),
BatchNorm2d(12),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2))
self.drop_out = Dropout()
self.dense = Sequential(
Linear(6912, 21),
ReLU(inplace=True),
Linear(21, 5),
ReLU(inplace=True),
Softmax())
self.fc = Linear(6912, 5)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0), -1)
x = self.drop_out(x)
x = self.dense(x)
return x
model = Net()
model.to(DEVICE)
Определившись с архитектурой, требовалось подготовить данные. Из части отчетов были извлечены все изображения и вручную рассортированы на 4 класса: зеленый, желтый, красный и серый. Дополнительно, из прочих изображений, был сформирован пятый класс, чтобы модель могла научиться отличать наши цветовые индикаторы от других объектов, таких как, например, графики или диаграммы.
Имеющееся количество экземпляров светофоров было искусственно дополнено путем вращения исходных изображений на 90 градусов с помощью библиотеки PIL:
for root, dir, files in os.walk(image_education_path):
for filename in files:
filename = filename.split('.')
filepath = os.path.join(root, '.'.join(filename))
img = Image.open(filepath)
for i in range(3):
img = img.rotate(90, expand=True)
img.save(os.path.join(root, filename[0] + '_{}.'.format(i+1) + filename[1]))
Данный способ аугментации позволил в 4 раза увеличить размеченный набор данных, что в конечном счете повлияло на итоговую точность модели и сэкономило время для дополнительной разметки.
Для тренировки и оценки качества полученные изображения были разделены на 2 части – train и test в соотношении 4:1. Эти данные были представлены в виде тензоров и поданы на вход сети.
train_x, test_x, train_y, test_y = train_test_split(train_img, y, test_size = 0.2, random_state=42)
train_x = np.array(train_x)
train_y = np.array(train_y)
train_x = train_x.reshape(len(train_x), 3, 96, 96)
train_x = torch.from_numpy(train_x).to(DEVICE)
train_y = torch.from_numpy(train_y).long().to(DEVICE)
Обучение проходило в течении 250 эпох. По завершению модель показала результат равный 98% как по точности, так и по полноте, что делает возможным ее использование для анализа цвета в исследуемых отчетах.
optimizer = Adam(model.parameters(), lr=0.07)
criterion = CrossEntropyLoss()
def train(epoch):
model.train()
x_train, y_train = Variable(train_x), Variable(train_y)
x_val, y_val = Variable(test_x), Variable(test_y)
optimizer.zero_grad()
output_train, output_val = model(x_train), model(x_val)
loss_train, loss_val = criterion(output_train, y_train), criterion(output_val, y_val)
train_losses.append(loss_train.item())
val_losses.append(loss_val.item())
loss_train.backward()
optimizer.step()
print('Epoch:',epoch+1, '\tloss: val =', loss_val.item(), 'train =', loss_train.item())
for epoch in range(n_epochs):
train(epoch)
for i in range(len(test_y)):
predict = (model(test_x[i].reshape(1, 3, 96, 96)))[0].cpu().detach().numpy()
print(test_y[i].item(), predict.argmax(axis=0))
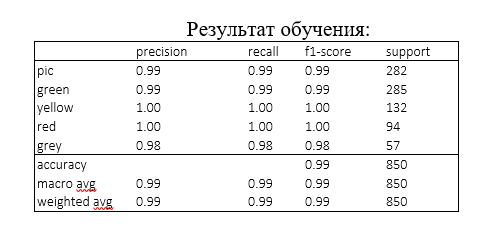
Стоит отметить, что подобных результатов удалось достичь не сразу. На первых этапах обучения сеть ошибалась. Существенное повышение качества модели произошло после того, как все имеющиеся изображения были приведены в единый вид — квадрат 96*96.
def make_square(img_path, max_size=96):
img = Image.open(img_path)
koef = max_size / max(img.size)
img = img.convert('RGB').resize((int(img.size[0] * koef), int(img.size[1] * koef)), Image.ANTIALIAS)
new_img = Image.new('RGB', (max_size, max_size), (255, 255, 255))
x, y = (new_img.size[0] - img.size[0]) // 2, (new_img.size[1] - img.size[1]) // 2
y = new_img.paste(img, (x, y))
return np.array(new_img).astype('float32')
Применение CNN позволило нам получить структурированную информацию и провести аналитику одним аудитором, что сократило время и трудозатраты на анализ большого объема данных.