/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Славянские языки, в том числе и русский, считаются довольно сложными для обработки. В основном, из-за богатой системы окончаний, свободного порядка слов и других морфологических и синтаксических явлений. Распознавание именованных сущностей (далее, NER) представляется трудной задачей для славянских языков, где синтаксические зависимости часто маркируются морфологическими чертами, нежели определенным порядком словоформ. Поэтому NER сложен для этих языков в сравнении с германскими или романскими языками.
NER – популярная задача в сфере обработки естественного языка. Она заключается в распознавании именованных сущностей в тексте и определение их типов. Например,

Здесь выделены следующие NER классы:
[27 октябля] – DATE
[Highland Center] – ORG
[Лос – Анджелес] – LOC
[Калифорния] – LOC
[США] – LOC
За много лет подходы к NER для русского языка претерпели множество изменений. От rule-based тенденции, предложенной в 2004 году (Popov et al., 2004) до современных state-of-the-art решений с использованием encoder-decoder архитектуры и трансформеров. Появилось множество NLP библиотек, стремящихся к универсальности и простоте. На протяжении истории развития обработки языка, NLP инструментарии поддерживали несколько «основных» языков, но позже эта тенденция сместилась в сторону мультиязыковой обработки текста. Один из таких инструментариев – spaCy (бесплатная опенсоурс библиотека для усовершенствованной обработки естественного языка), который включает в себя предобученные модели для 18 разных языков. Для большинства задач spaCy (Honnibal & Montani, 2017) использует сверточные нейронные сети, но для NER используются transition-based подходы.
Зимой 2021 года у spaCy вышла новая версия – 3: появилась русская модель и возможность выбора стандартной модели для обучения в зависимости от наличия GPU. Для задачи NER для русского языка spaCy предлагает tok2vec и Multilingual BERT. Также, пользователь может самостоятельно выбрать предобученную модель из списка на HuggingFace.
Попробуем натренировать NER на собственном датасете с использованием двух предложенных моделей. BSNLP Shared Task дает возможность загрузить тренировочные данные с аннотацией для нескольких славянских языков. Загрузим данные 2021 года. Они представлены в виде файлов с текстом и соответствующих лейблов следующего вида:
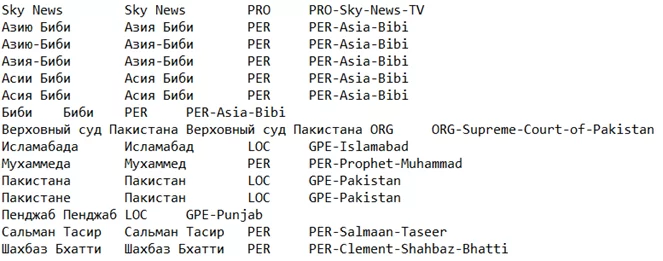
Последний столбец нас не интересует, так как он относится к части задания Entity Matching, первый столбец – словоформа в тексте, второй – лемма, третий – именованная сущность. Чтобы работать с этими данными в spaCy, нужно привести их в специальный бинарный формат. Более подробней о нём – здесь.
Data Processing
Сначала находим нужную сущность из файлов с лейблами в тексте и записываем формат [index.start(), index.end(), label] в список, где index – индекс буквы в тексте, а label – аннотированная сущность. Затем очищаем полученный список от возможных пересечений индексов. Далее, с помощью встроенных функций spaCy приводим наш список в следующий формат: [«O», «O», «U-LOC», «O»], а потом кладем тексты и полученные тэги в привычный для spaCy doc.
def make_docs(folder, doc_list):
nlp = spaCy.load('ru_core_news_lg')
"""
this function takes a list of texts and annotations
and transforms them in spaCy documents
folder: folder consisting .txt and .out files (for this function to work
you should have the same folder name in ../annotated directory )
doc_list: list of documents for appending
"""
out='out'
for filename in os.listdir('data/bsnlp2021_train_r1/raw/{folder}/ru'.format(folder=folder)):
df = pd.read_csv('data/bsnlp2021_train_r1/annotated/{folder}/ru/{filename}{out}'.format(folder=folder, filename=filename[:-3], out='out'), skiprows=1, header=None, sep='\t', encoding='utf8', error_bad_lines=False, engine='python')
f = open('data/bsnlp2021_train_r1/raw/{folder}/ru/{filename}'.format(folder=folder,filename=filename), "r", encoding='utf8')
list_words=df.iloc[:,0].tolist()
labels = df.iloc[:,2].tolist()
text = f.read()
entities=[]
for n in range(len(list_words)):
for m in re.finditer(list_words[n].strip(), text):
entities.append([m.start(), m.end(), labels[n]])
for f in range(len(entities)):
if len(entities[f])==3:
for s in range(f+1, len(entities)):
if len(entities[s])==3 and len(entities[f])==3:
if entities[f][0]==entities[s][0] or entities[f][1]==entities[s][1]:
if (entities[f][1]-entities[f][0]) >= (entities[s][1]-entities[s][0]):
entities.pop(s)
entities.insert(s, (''))
else:
entities.pop(f)
entities.insert(f, (''))
if len(entities[s])==3 and len(entities[f])==3:
if entities[f][0] in range(entities[s][0]+1, entities[s][1]):
entities.pop(f)
entities.insert(f, (''))
elif entities[s][0] in range(entities[f][0]+1, entities[f][1]):
entities.pop(s)
entities.insert(s, (''))
entities_cleared = [i for i in entities if len(i)==3]
doc = nlp(text)
tags = offsets_to_biluo_tags(doc, entities_cleared)
#assert tags == ["O", "O", "U-LOC", "O"]
entities_x = biluo_tags_to_spans(doc, tags)
doc.ents = entities_x
doc_list.append(doc)
Можно сделать это и другим, более оптимальным способом. Главное – привести данные в doc формат, требующийся для дальнейшей работы во фреймворке.
Далее, (опционально) добавляем функцию, которая поможет нам разделить файлы на нужные пропорции для обучающего, тестового и валидационного наборов данных:
def split_docs(folder1, folder2, folder3, split_train, split_dev, folder4):
"""
this function saves data from the folders to the list of
spaCy documents considering training and development set
proportions
"""
train_docs = []
dev_docs = []
test_docs = []
train_entities = 0
dev_entities = 0
test_entities = 0
total_entities = 0
data=[]
utils.make_docs(folder1, data)
utils.make_docs(folder2, data)
utils.make_docs(folder3, data)
utils.make_docs(folder4, test_docs)
# count the total number of entities
for doc in data:
total_entities += len(doc.ents)
# shuffle the gold docs
random.seed(27)
random.shuffle(data)
dev_ratio = split_dev / 100
cur_train_ratio = -1
cur_dev_ratio = -1
for doc in data:
num_entities = len(doc.ents)
if cur_dev_ratio < dev_ratio:
dev_docs.append(doc)
dev_entities += num_entities
cur_dev_ratio = dev_entities / total_entities
else:
train_docs.append(doc)
train_entities += num_entities
cur_train_ratio = train_entities / total_entities
print("{} train entities in {} docs ({} %)".format(str(train_entities), str(len(train_docs)), str(int(cur_train_ratio*100))))
print("{} dev entities in {} docs ({} %)".format(str(dev_entities), str(len(dev_docs)), str(int(cur_dev_ratio*100))))
return train_docs, dev_docs, test_docs
Данная функция шафлит тексты и делит их на обучающие и тестовые сеты с использованием заданных пропорций. Например, 80 и 20, 70 и 30 процентов и т.д. Так как доступ к тестовым данным Shared Task’а требуется получать отдельно, используем три имеющихся тематики для обучающих и тестовых сетов и одну в качестве валидационного.
Наконец, сохраняем данные в бинарный формат spaCy:
def save_data(train_docs, dev_docs, test_docs, train_file, dev_file, test_file):
DocBin(docs=train_docs).to_disk(train_file)
DocBin(docs=dev_docs).to_disk(dev_file)
DocBin(docs=test_docs).to_disk(test_file)
Model Training
Приступим к тренировке модели. Тренировать мы будем две разные архитектуры: tok2vec и bert-base-multilingual-uncased, предложенные по умолчанию spaCy в зависимости от наличия GPU.
Тут можно подробней изучить архитектуру tok2vec. Вкратце, эта архитектура с использованием RNN и attention.
Про архитектуру трансформера можно узнать из известной статьи “Attention is all you need” (Vaswani et al., 2017). Здесь мы имеем предобученный на разных языках (в том числе и русском) Multilingual BERT, который нужно дообучить (fine-tune) на конкретный таск – в нашем случае – NER. Подробнее о том, что такое pre-training, fine-tuning и о том, как они реализованы в BERT архитектуре, можно прочесть здесь: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (Devlin et al., 2019).
Чтобы получить конфигурационный файл, необходимый для тренировки, переходим по ссылке и выбираем нужные параметры: язык, таск, наличие GPU. SpaCy сгенерирует необходимый начальный конфиг. Далее, используем следующую команду, чтобы заполнить оставшиеся параметры, необходимые для начала тренировки:
$ python -m spacy init fill-config base_config.cfg config.cfg Максимальная длина последовательности токенов, которые можно «положить» в Multilingual BERT – 512. Учитывая факт, что BERT генерирует «свои» токены из исходного текста (количество слов в изначальной последовательности не равняется количеству элементов, полученных с помощью токенайзера BERT) важно, чтобы последовательность не превышала 250-300 слов. К сожалению, несколько текстов имеют бо́льшую последовательность, но для простоты не будем делить их – BERT просто «отрежет» лишнюю часть.
Также, перед тем как приступить к обучению модели, spaCy советует проверить данные на наличие проблем, таких как неправильные аннотации, пересечение индексов, отсутствие конечных и начальных тэгов и т.д. Для этого используем:
$ python -m spacy debug data config.cfgВсе готово для начала тренировки. Начинаем:
$ python -m spacy train config.cfg --output ./output --paths.train ./train.spacy --paths.dev ./dev.spacyЕсли необходимо использовать архитектуру трансформера, а GPU у вас нет, то мы советуем этот туториал – он поможет настроить GPU в Google Colab’е для тренировки модели spaCy.
Для того, чтобы улучшить результат tok2vec модели, spaCy рекомендует:
- изменять гиперпараметры (это делается внутри конфиг файла):
Рекомендуем попробовать несколько вариантов и выбрать лучший.
- -использовать предобучение:
def collecting_jsonl(folder, text_list):
"""
this function takes raw texts from the folder and
returns a list of json-formatted elements for creating
pre-training corpus.
folder: folder with .txt files
text_list: list of texts for appending
"""
for filename in os.listdir('data/bsnlp2021_train_r1/raw/{folder}/ru'.format(folder=folder)):
f = open('data/bsnlp2021_train_r1/raw/{folder}/ru/{filename}'.format(filename=filename, folder=folder), "r", encoding='utf8')
text=f.read()
tempDict = {}
tempDict["text"]= text
text_list.append(tempDict)
text_list=[]
for i in args[0]:
print(i)
collecting_jsonl(i,text_list)
srsly.write_jsonl("pretrain_corpus.jsonl", text_list)
- использовать обученные вектора:
Для русского языка spaCy предлагает несколько вариантов векторов в зависимости от величины корпуса. Информацию об этом так же можно найти на официальном сайте библиотеки. Мы используем «ru_core_news_lg».
Results
- Вот такие результаты мы выявили при оценивании tok2vec модели:
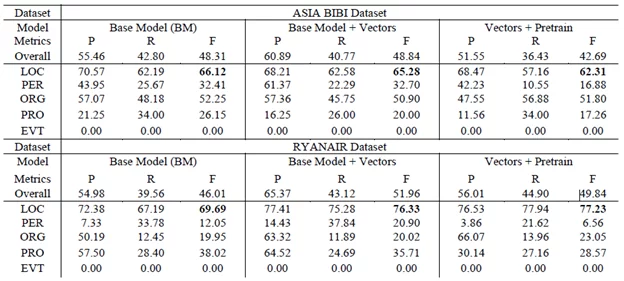
В качестве валидационных данных (которые модель ранее не видела) были взяты Ryanair и Asia Bibi тематики. Лучший F—score: 0.52 на модели с использованием обученных векторов.
- Multilingual BERT ожидаемо показал лучший результат:
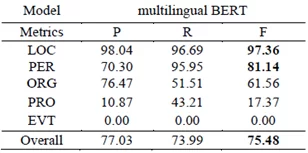
В качестве тестовых данных был использован топик Ryanair. F—score: 0.755
Для сравнения, в 2019 году на очень похожем датасете с использованием BERT архитектуры и дополнительных верхних слоев CRF (условных случайных полей) и NCRF (нейронных условных случайных полей) участниками BSNLP Shared Task были получены следующие результаты:
F-score: 0.9 (Tsygankova et al., 2019; Arkhipov et al., 2019)
F-score: 0.81 (Moreno et al., 2019)
В отличие от участников выше, мы использовали только русский язык, а не весь перечень языков, предложенных в задании – данных для тренировки у нас, соответственно, было меньше.
Conclusion
Мы рассмотрели и протестировали две стандартные модели, предложенные нам фреймворком spaCy для русского языка: tok2vec и Multilingual BERT. К сожалению, нам не удалось в полной мере сравнить наш результат с лучшими подходами участников прошлого соревнования.
Сразу отметим, что цель данного исследования заключалась не в получении лучшего результата, а в изучении фреймворка spaCy. Проанализировав работы участников 2019 и 2021 года BSNLP Shared Task, представляем потенциальные подходы к улучшению результата:
- Использовать в качестве тренировочных данных весь датасет славянских языков
- Дополнить имеющиеся данные различными корпусами (например, википедия, корпус новостей и т.д.)
- Предобработать данные, исключив или унифицировав «спорные моменты»
- Использовать другие предобученные модели (RuBERT, SBERT и т.д.)
- Экспериментировать с архитектурой модели (использовать дополнительные CRF слои, объединять параметры внутри слоев и т.д.)