/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В школе каждый из нас сталкивался с пересказом текста: читаешь главу из 10 страниц, а дальше у тебя есть 5 минут, чтобы коротко изложить классу и учителю, что важного ты узнал из прочитанного. Невозможно выучить текст, как стихотворение, поэтому переработав прочитанную информацию, каждый из нас старался ее обобщить. То же самое в некотором приближении может повторить и модель машинного обучения.
Суммаризация — задача обобщения текста одним или несколькими предложениями. Существует два общепринятых подхода:
- Экстрактивная: используются предложения из самого же текста
- Абстрактивная: модель составляет из слов, которые встретились в тексте, обобщенное предложение/ предложения
Зачем решать задачу суммаризации в принципе? Для экономии времени и иных ресурсов. В каждой компании пачками копятся служебные записки/отчеты/акты и подобные многостраничные документы. Так или иначе многие из них попадают на чтение руководству, которое чаще всего нуждается в выжимке, а не в подробном описании произошедшего, однако выжимка из облака тегов слишком коротка для понимания.
Метрики для оценки качества:
Как оценить, насколько хорошо или плохо решена задача? Для этого используется ROUGE метрика.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation/ Оценка реферирования, ориентированная на полноту).
Метрика показывает, насколько сгенерированный реферат покрывает оригинальный текст. В случае учета юниграм (отдельных слов), полнота рассчитывается следующим образом:

Существует несколько разновидностей метрик ROUGE, к ним можно отнести метрику ROUGE-1, которая основана на совпадении отдельных слов в оригинальном и сгенерированном тексте. ROUGE-2 учитывает совпадение словосочетаний из двух слов (биграмм). ROUGE-L – оценивает самую длинную последовательность совпавших слов.
Однако до сих пор задача нуждается в человеческой оценке «читаемости» текста. Модель может использовать тот же набор слов, что и в референсном саммари, но не связать их грамматически, и в таком случае результат не будет информативным и полезным.
Про обучающие данные:
Чтобы генерировать связный текст, нужны данные, и здесь правило «больше — лучше» не исключение. В зарубежной практике собраны большие датасеты на гигабайты данных для решения этой задачи: CNN, GigaWord, XSum и прочие. От простых моделей (RNN) из-за большого объема обучающей выборки, зарубежное сообщество перешло к обучению BERT, GPT-2, PEGASUS, ProphetNet и другие, демонстрируя результаты, сопоставимые с теми, что может произвести человек.
В практике с русским языком дела обстоят немного иначе, в открытом доступе есть всего два новостных датасета РИА Новости и Lenta.ru, на которых русскоязычное сообщество может опробовать подходы для суммаризации. Очень рекомендуем ознакомиться с этими статьями, эти работы доказывают, что на данных русского языка можно и нужно учиться обобщать тексты.
Так где же взять данные для обучения модели?
Первый вопрос, с которого начинается работа – это поиск релевантных данных для обучения. Разметка таких текстовых данных — это очень дорогой и субъективный труд. Каждый человек по-разному воспринимает текст, а от степени его усталости и концентрации зависит качество короткого пересказа. Так как направление нашей работы связано с аудитом, мы работаем с текстами аудиторских проверок, где каждое нарушение, согласно стандартам, выделяется в отдельный абзац, у которого, в свою очередь, есть заголовок. Обычно заголовок и первое предложение абзаца отражают суть нарушения, поэтому мы решили его использовать как эталон, к которому должна стремиться модель при генерации собственного текста.

Люди уже попытались обобщить текст, так зачем нам повторно привлекать ресурсы на разметку? Но по итогу, как уже отмечалось ранее, не все topic-sentences, которые должны отражать суть нарушений ее реально отражают, виной тому шаблоны, канцеляризмы и человеческий фактор, это неизбежно влияет на вывод модели.
Фреймворк и использованные инструменты
Каждое нарушение вместе с заголовком мы разбили на предложения при помощи rusenttokenizer от DeepPavlov, прописав в настройках свойственные для наших текстов сокращения и аббревиатуры. Затем взяли первое или несколько первых предложений (в зависимости от длины текста), как референсное саммари. Мы не проводили никакой препроцессинг, кроме чистки пунктуации, потому что иначе сгенерированные тексты не получаются связными, лемматизация и стемминг не позволили бы сохранить число и падеж.
Далее мы использовали фреймворк AllenNLP и архитектуру PGN (Pointer Generator Network). Сам Фреймворк работает на базе PyTorch и достаточно логичен, все проблемы, с которыми мы столкнулись при обучении, подняты и решены в issues на одноименном гитхабе. Из чего состоит архитектура модели:
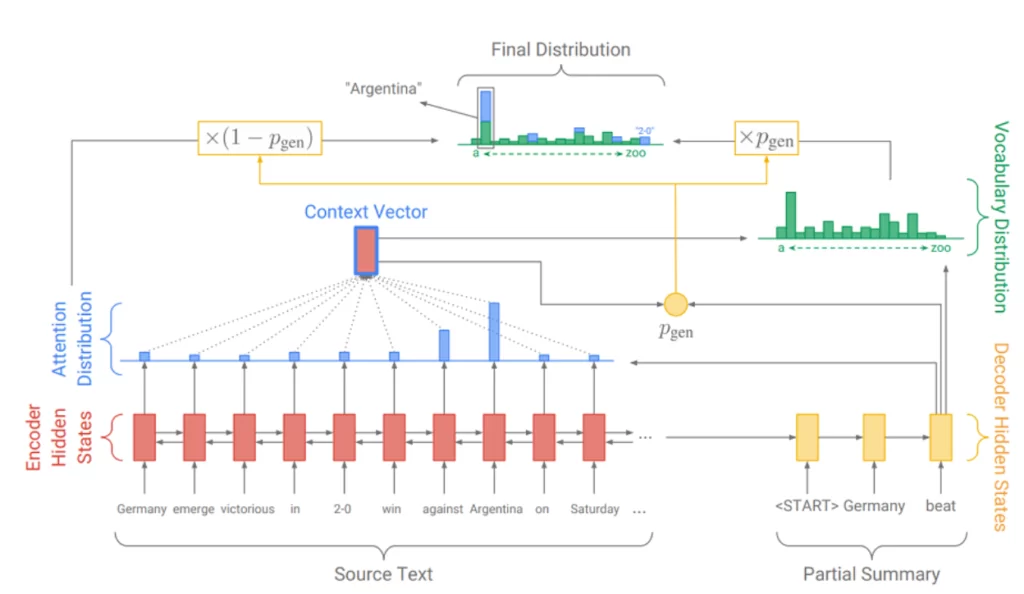
Архитектура основана на системе encoder-decoder с использованием attention mechanism. Модель создает читаемые тексты, так как использует два подхода одновременно, оперируя параметром P(gen). Чем больше значение к 1, тем выше вероятность, что модель использует слово из своего словаря, используя абстрактивную генерацию, чем ближе к 0, тем больше вероятность, что модель выдаст слово из текста, опираясь на распределение внимания. Более подробно про модели генерации текстов на основе seq2seq можно прочитать в статье.
Пайплайн нашего обучения
Все начинается с оформления модуля, который будет для определенного датасета формировать загрузку данных в стандартизованном формате из csv: все достаточно просто, мы хардкодим столбец, в котором содержится эталонное краткое содержание, и столбец с основным текстом.
Важное ограничение, что модели не могут принимать большие последовательности (более 512-800 токенов) на вход.
Для архитектуры PGN мы написали конфиг, в котором указали особенности тренировки: размер батча, шаг при обучении, количество тренировочных эпох и размер используемого словаря, а также указали, по какому принципу необходимо отделять слова друг от друга: можно использовать просто пробел или spacy, мы воспользовались модулем, который входит в состав библиотеки natasha – razdel.
Далее собрали словарь токенов и опорных токенов при помощи AllenNLP. После составлено словаря мы запустили тренировку. В параметрах можно задать early-stoping и предостеречь модель от переобучения.
Посмотреть код нашей реализации можно в репозитории.
Результаты
Результаты получились разные, есть тексты, в которых сгенерированный текст обобщил по крайней мере не хуже, чем у человека. Как, например, текст ниже (Ref – саммари, написанное человеком, Hyp – саммари, сгенерированное моделью):
Ref: Оплата фактически не предоставленных клининговых услуг
Hyp: Нерациональные расходы организации по договорам клининговых услуг
Прямого повторения текста из исходного нет, модель естественным образом подобрала падеж, склонение, число, саммари получилось грамматически читаемым.
Конечно, модель пишет не все саммари. Так есть неудачные примеры с задвоением слов, чему виной используемый вариант распределения внимания. Бывают случаи, когда прогнозируемое краткое содержание не отражает суть совсем, тут может быть причиной целая комбинация факторов, начиная с некачественной обучающей выборки.

Вывод:
Более сложные алгоритмы суммаризации более гибкие для настройки, у Вас есть возможность посредством обучающей выборки показать алгоритму эталонные примеры, на которые он должен ориентироваться. Если же использовать LexRank/TextRank, которые намного быстрее и проще, возможность показать, что Вы ожидаете на выходе, отсутствует. Как говорил великий: «С большой силой приходит большая ответственность». И если использовать простые методы экстрактивной суммаризации, предложения будут повторять грамматику автора, с абстрактивной — Вы рискуете получить несвязный текст.