/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 13 мин.
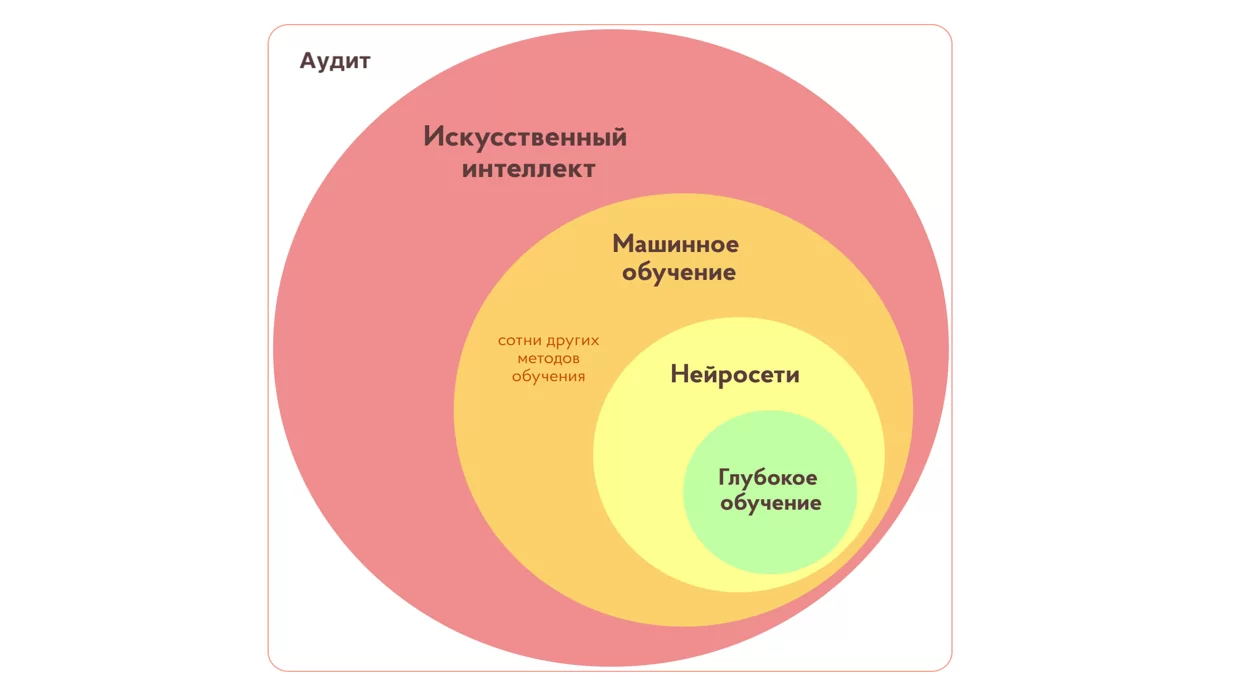
Введение в аудит и машинное обучение
Аудит является неотъемлемой частью бизнес-практики, обеспечивая независимую оценку финансовой отчетности и процессов в организации. Аудиторы полагаются на опыт и статистическую выборку для ручной проверки сотен документов и свидетельств, определения сильных сторон и углубленного анализа организационных процедур и транзакций. Однако этот ручной процесс превратил аудит в трудоемкую и ресурсоемкую деятельность.
В этом контексте машинное обучение (ML) играет все более важную роль. Машинное обучение — это ветвь искусственного интеллекта, которая помогает компьютерам “учиться” на импортируемых больших объемах данных и алгоритмов, чтобы делать прогнозы, выявлять паттерны и принимать решения без явного программирования. Оно оказывает всё больше влияния на область анализа данных и аналитики веб-сайтов, и открывает новые возможности для улучшения эффективности, точности и надежности процессов аудита. В настоящее время почти каждая крупная технологическая компания внедряет ML (машинное обучение) в область аудита. Вот, например, как ML применяется в Facebook https://www.geeksforgeeks.org/5-mind-blowing-ways-facebook-uses-machine-learning/ и Amazon https://www.geeksforgeeks.org/how-amazon-uses-machine-learning/.
Применение машинного обучения в аудите
ML может быть использован в различных аспектах аудита, включая анализ данных, обнаружение мошенничества, прогнозирование рисков и оптимизацию процессов. Алгоритмы машинного обучения могут обрабатывать и анализировать огромные объемы данных, выявлять скрытые зависимости и выделять аномалии, что помогает аудиторам принимать более обоснованные и точные решения. Далее мы рассмотрим различные типы задач машинного обучения, которые могут быть применены в аудите.
Задача классификации
В качестве примера проанализируемуем данные, взятые с сайта Kaggle. Возьмём на сайте подходящий для аудита пример, а именно Audit Data, датасет содержащий набор данных для классификации мошеннических фирм.
# Импортируем библиотеки
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Считываем данные
df = pd.read_csv('audit_data.csv')
df.head()

df.info()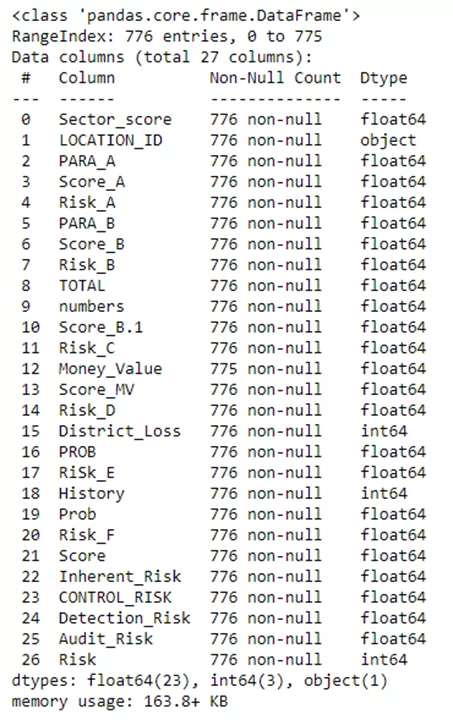
# Создаем компию датафрейма
df_ml = df.copy()
# Заполняем пустые значения медианными
df_ml.Money_Value.fillna(value = df_ml.Money_Value.median(), inplace=True)
df_ml['LOCATION_ID'].unique()

Так как в столбце имеются строковые значения, нужно его перекодировать.
location_dummies = pd.get_dummies(df_ml['LOCATION_ID'], prefix='location')
df_ml = pd.concat([df_ml, location_dummies], axis=1)
df_ml = df_ml.drop('LOCATION_ID', axis=1)
X = df_ml.drop(columns = 'Risk')
y = df_ml.Risk
# Создаем тренировочную и тестовую выборку
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7,stratify = y, shuffle=True, random_state=42)
# Импортируем модели
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import svm
from sklearn import metrics
# Обучим модели и сравним их показатели на тестовой выборке
models = {
"Logistic Regression": LogisticRegression(solver= 'liblinear', random_state=42),
"Decision Tree": DecisionTreeClassifier(),
"Random Forest": RandomForestClassifier(n_estimators=100, random_state=0),
"GB": GradientBoostingClassifier()
}
model_list=[]
accuracy_list=[]
recall_list=[]
precision_list=[]
specificity_list=[]
f1_score_list=[]
for i in range(len(list(models))):
model=list(models.values())[i]
model.fit(X_train,y_train)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
score = round(model.score(X_test, y_test), 4)
tn, fp, fn, tp = metrics.confusion_matrix(y_test, y_test_pred).ravel()
recall = round(tp/(tp+fn), 3)
precision = round(tp/(tp+fp), 3)
specificity =round(tn/(tn+fp),3)
f1_score = round(2*precision*recall/(precision + recall), 3)
print(list(models.keys())[i])
model_list.append(list(models.keys())[i])
print('Model performance for Test set')
print("- Accuracy: {}".format(score))
print("- Recall: {}".format(recall))
print("- Precision: {}".format(precision))
print("- Specificity: {}".format(specificity))
print("- f1_score: {}".format(f1_score))
accuracy_list.append(score)
recall_list.append(recall)
precision_list.append(precision)
specificity_list.append(specificity)
f1_score_list.append(f1_score)
print('='*35)
print('\n')
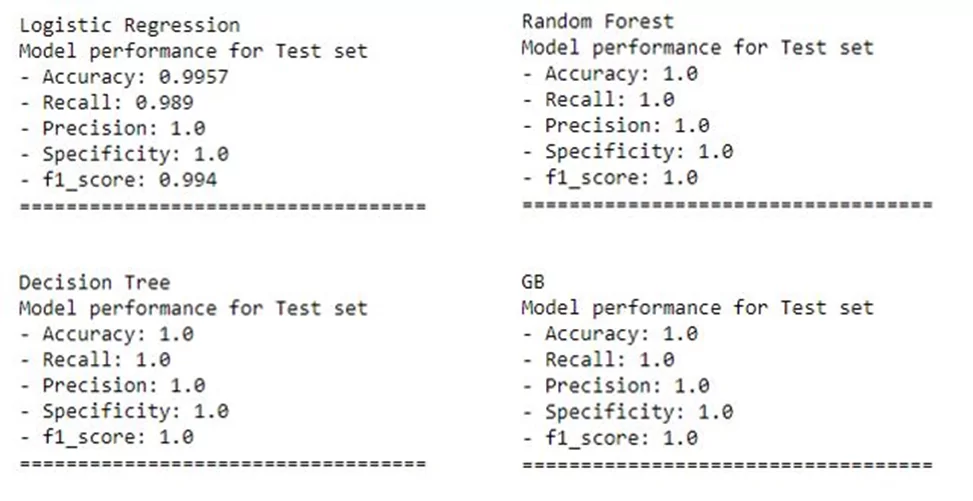
А теперь разберём что сейчас произошло. Мы только что решили стандартную задачу классификации, обучили наши модели на исторических данных и теперь можем передавать им новые данные по фирмам, тогда наши модели предскажут, являются ли эти фирмы мошенническими. Мы использовали и сравнили несколько моделей, а именно:
- логистическая регрессия, предсказывающая вероятность принадлежности к определенному классу;
- решающие деревья, представляющие собой древовидную структуру решений, где каждый узел представляет тест на признак, а каждое ответвление соответствует возможному значению этого признака;
- случайный лес, представляющий собой несколько моделей решающих деревьев, где каждое дерево обучается на случайной предвыборке данных, а предсказание получается путем усреднения предсказаний всех деревьев;
- градиентный бустинг – ансамбль моделей, где новые модели добавляются последовательно и корректируют ошибки предыдущих моделей.
В итоге мы получили следующие показатели.
- Accuracy (точность): Это показатель, который измеряет долю правильно классифицированных образцов по отношению ко всем образцам. Формула для вычисления accuracy выглядит так: accuracy = (TP + TN) / (TP + TN + FP + FN), где TP (True Positive) – количество правильно предсказанных положительных классов, TN (True Negative) – количество правильно предсказанных отрицательных классов, FP (False Positive) – количество неправильно предсказанных положительных классов и FN (False Negative) – количество неправильно предсказанных отрицательных классов.
- Precision (точность): Это показатель, который измеряет долю правильно предсказанных положительных классов относительно всех классифицированных положительных образцов. Формула для вычисления precision выглядит так: precision = TP / (TP + FP).
- Recall (полнота): Это показатель, который измеряет долю правильно предсказанных положительных классов относительно всех фактически положительных образцов. Формула для вычисления recall выглядит так: recall = TP / (TP + FN).
- Specificity (специфичность): Это показатель, который измеряет долю правильно предсказанных отрицательных классов относительно всех фактически отрицательных образцов. Формула для вычисления specificity выглядит так: specificity = TN / (TN + FP).
- F1 score: Это гармоническое среднее между precision и recall. F1 score является показателем, который учитывает и точность, и полноту модели. Он предоставляет баланс между этими двумя метриками. F1 score вычисляется по следующей формуле: F1 score = 2 * (precision * recall) / (precision + recall).
Они являются важными для оценки производительности модели классификации и помогают понять, насколько хорошо модель справляется с предсказанием классов. В зависимости от задачи и контекста, некоторые показатели могут быть более важными, чем другие.
Представим полученные данные в виде таблицы.
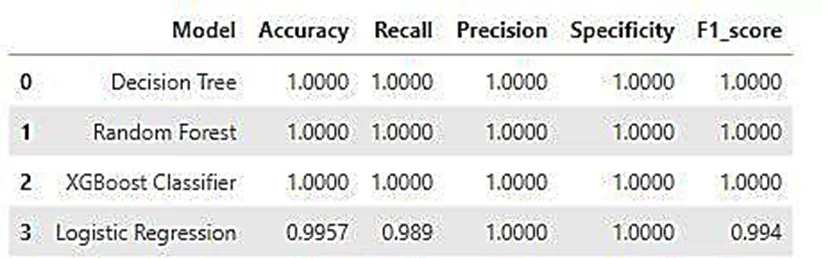
Как мы можем заметить, в нашем примере модель логистической регрессии показала себя хуже, чем другие модели.
Задача регрессии
В аудите могут использоваться и другие типы задач машинного обучения. Рассмотрим задачу регрессии, её отличие от задачи классификации заключается в том, что её цель предсказать числовое значение, а не категориальное.
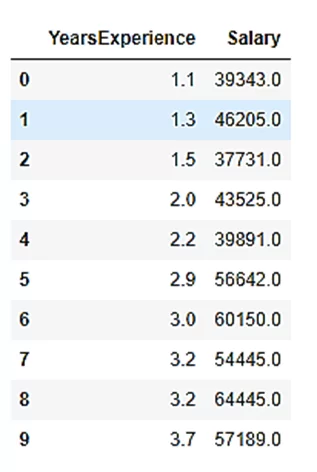
Итак с Kaggle возьмем датасет Salary Prediction Data, в нём содержится информация об опыте работы сотрудника и его зарплате. Обучим на его данных модель регрессии.
# Считываем данные
df = pd.read_csv('Salary_Data.csv')
df.head(10)
target = 'Salary'
X = df.loc[:,df.columns!=target]
y = df.loc[:,df.columns==target]
# Создаем тренировочную и тестовую выборку
x_train, x_test, y_train, y_test= train_test_split(X, y, test_size= .2, random_state=0)
# Импортируем и обучаем модель
from sklearn.linear_model import LinearRegression
lr= LinearRegression()
lr.fit(x_train, y_train)
y_pred= lr.predict(x_test)
x_pred= lr.predict(x_train)
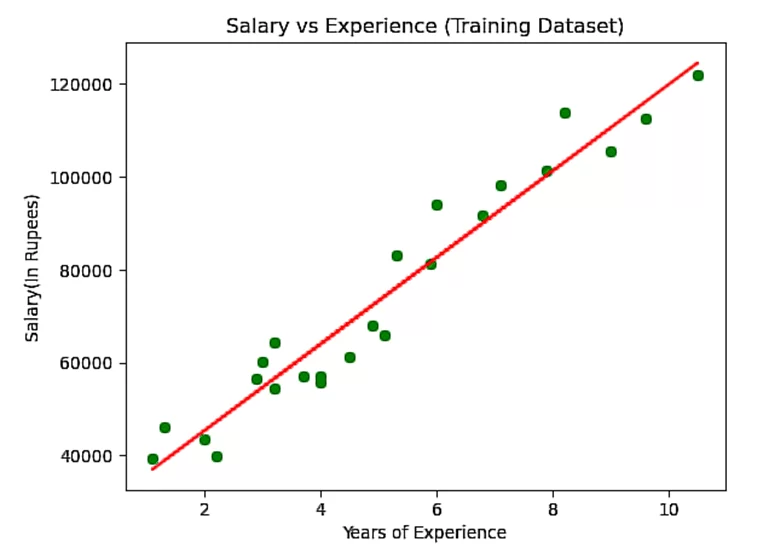
# Отрисовываем графики зависимости зарплаты от опыта работы
import matplotlib.pyplot as mtp
mtp.scatter(x_train, y_train, color="green")
mtp.plot(x_train, x_pred, color="red")
mtp.title("Salary vs Experience (Training Dataset)")
mtp.xlabel("Years of Experience")
mtp.ylabel("Salary(In Rupees)")
mtp.show()
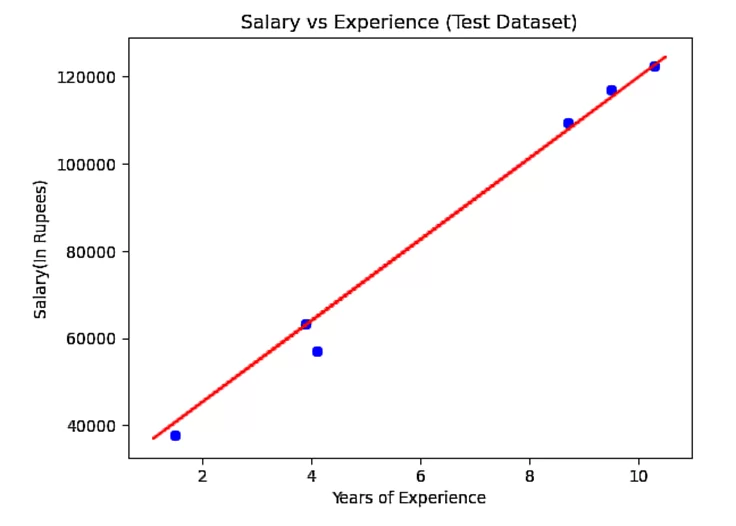
mtp.scatter(x_test, y_test, color="blue")
mtp.plot(x_train, x_pred, color="red")
mtp.title("Salary vs Experience (Test Dataset)")
mtp.xlabel("Years of Experience")
mtp.ylabel("Salary(In Rupees)")
mtp.show()
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
regressor = LinearRegression()
regressor.fit(x_train,y_train)
r2_score = regressor.score(x_test,y_test)
r2_score = r2_score*100
predict = lr.predict(x_test)
mse = mean_squared_error(predict,y_test, squared=False)
mae = mean_absolute_error(predict,y_test)
У модели регрессии так же свои метрики.
- Mean Squared Error, MSE (Среднеквадратичная ошибка): это наиболее распространенная метрика для задач регрессии. MSE измеряет среднюю квадратичную разницу между предсказанными значениями и фактическими значениями целевой переменной. Чем меньше значение MSE, тем лучше производительность модели.
- MeanAbsoluteError, MAE (Средняя абсолютная ошибка): MAE измеряет среднюю абсолютную разницу между предсказанными значениями и фактическими значениями целевой переменной. MAE также предоставляет информацию о средней величине ошибки модели.
- Coefficient of Determination, R^2 (Коэффициент детерминации): R^2 измеряет пропорцию дисперсии зависимой переменной, которая может быть объяснена моделью. Значение R^2 находится в диапазоне от 0 до 1, где 1 означает, что модель идеально объясняет вариацию данных, а 0 означает, что модель не объясняет вариацию данных лучше, чем простое среднее значение.
В нашем случае значения будут следующие:
R^2= 98.8169515729126 %
MAE= 2446.1723690465064
MSE= 3580.979237321345
Данная модель может в дальнейшем применяться для предсказания заработной платы сотрудника в зависимости от его стажа, но модель может работать и с более комплексными датасетами, содержали гораздо больше информации.
Задача кластеризации.
Рассмотрим еще один тип задач машинного обучения, с которым может столкнуться аудитор, а именно задачу кластеризации, ведь может быть такое, что в работе нужно будет выявить группы, схожие по каким-либо характеристикам. Возвращаемся на Kaggle и берем датафрейм Credit Card Dataset, , содержащий набор данных о кредитных картах и характеристиках клиентов, таких как пол, возраст, занятость, семейное положение и истории использования кредитной карты. Наша задача выявить группы клиентов схожего поведения и создать сегментацию на основе этих характеристик. Это может помочь аудиторам лучше понять своих клиентов и улучшить стратегии организации.
# Считываем данные
df=pd.read_csv('CC GENERAL.csv')
df.head()

df.info()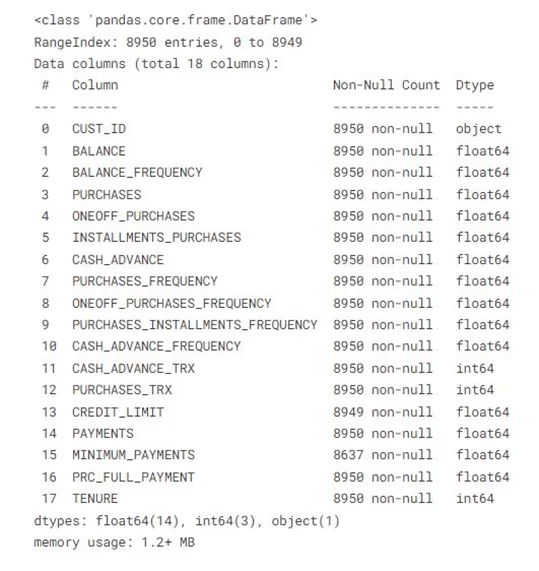
df.isnull().sum()
# Заполняем нулевые значения средними
df['MINIMUM_PAYMENTS']=df['MINIMUM_PAYMENTS'].fillna(df['MINIMUM_PAYMENTS'].mean())
from sklearn.cluster import KMeans
wcss=[]
for k in range(1,11):
kmeans=KMeans(n_clusters=k, init='k-means++', random_state=0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
# Для выбора оптимального количества кластеров используем метод “локтя”
plt.plot(range(1,11), wcss)
plt.title('The elbow method')
plt.xlabel('Number of Clusters')
plt.ylabel('WCSS')
plt.show()
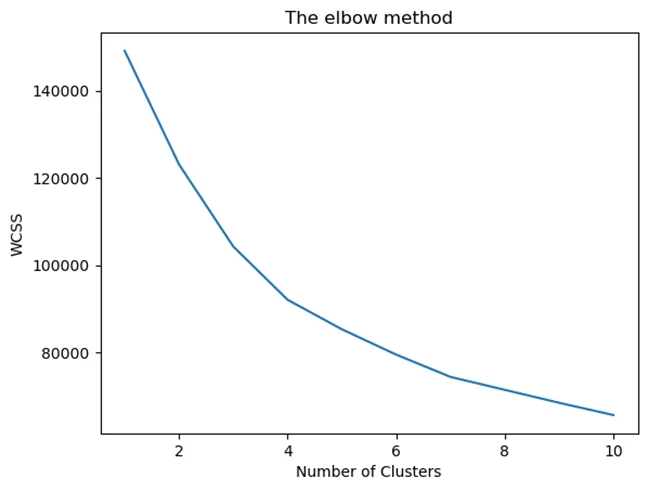
# Выберем количество кластеров равное 4
kmeans=KMeans(n_clusters=4, init='k-means++', random_state=0)
y_kmeans=kmeans.fit_predict(X)
cdf['cluster']=y_kmeans
cdf1=cdf[cdf.cluster==0]
cdf2=cdf[cdf.cluster==1]
cdf3=cdf[cdf.cluster==2]
cdf4=cdf[cdf.cluster==3]
plt.figure(figsize=(10,10))
plt.scatter(cdf1['PURCHASES'], cdf1["PAYMENTS"], color='green')
plt.scatter(cdf2['PURCHASES'], cdf2["PAYMENTS"], color='red')
plt.scatter(cdf3['PURCHASES'], cdf3["PAYMENTS"], color='orange')
plt.scatter(cdf4['PURCHASES'], cdf4["PAYMENTS"], color='blue')
plt.xlabel("Purchases")
plt.ylabel("Payments")
plt.legend()
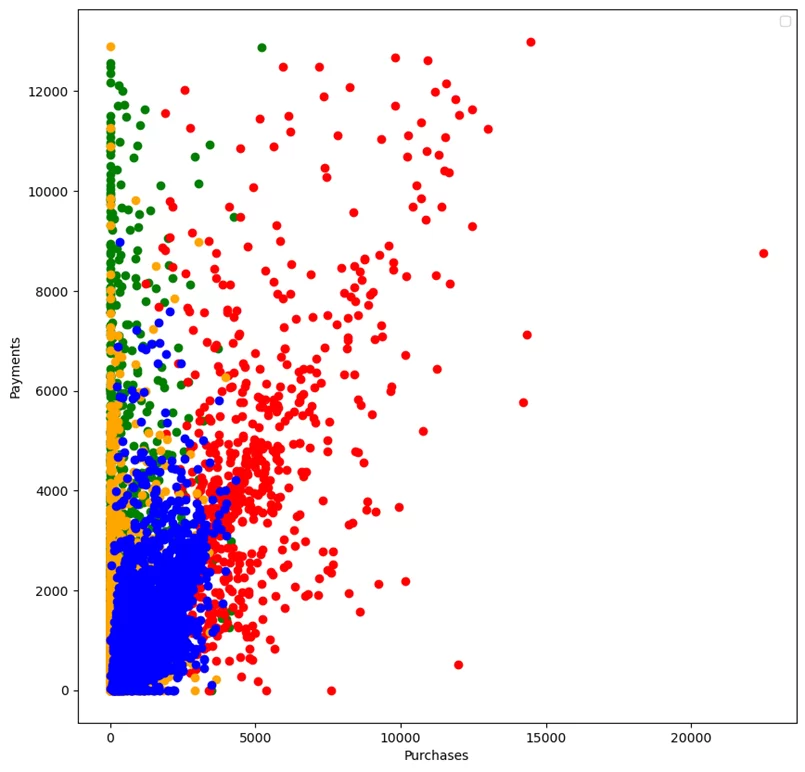
Как видно на рисунке наша модель разделила клиентов на 4 кластера. В аудите такое разделение может быть использовано для выявления необычных групп или кластеров клиентов, которые могут иметь потенциальные риски.
Использование компьютерного зрения
Компьютерное зрение открывает новые возможности для повышения точности аудиторской работы, её облегчения, а также повышения эффективности. Аудиторы используют компьютерное зрение для анализа фото, видео с камер, оно может помочь в определении типа документа, извлечении из него какой-либо информации, проверить на соответствие определенным стандартам.
Рассмотрим следующий пример: возьмем с Kaggle датасет Handwritten Signature Identification, в нём содержится набор изображений подписей, предоставленных различными людьми. Перед нами стоит задача верификации и идентификации подписей. То есть нам следует проверить является ли подпись подлинной для конкретного человека, а также нужно определить кто является автором подписи.
# Импортируем библиотеки
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import pathlib
import cv2
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import warnings
warnings.filterwarnings('ignore')
os.environ["KMP_WARNINGS"] = "FALSE"
TRAIN_PATH = pathlib.Path("Train")
VAL_PATH = pathlib.Path("Test")
img = cv2.imread("Train/PersonA/Copy of personA_1.png")
plt.imshow(img)
img.shape
num_classes = 5 # имеется 5 человек: A,B,C,D,E
img_height = 224
img_width = 224
from tensorflow.keras.applications import MobileNetV3Large
from tensorflow.keras.applications.mobilenet import preprocess_input
from tensorflow.keras.preprocessing import image
Загрузим данные с помощью DataGen и выполним некоторую предварительную обработку данных
BATCH_SIZE = 32
IMAGE_SIZE = (img_height, img_width)
train_data_generator = image.ImageDataGenerator(
horizontal_flip=True,
preprocessing_function=preprocess_input
)
test_data_generator = image.ImageDataGenerator(
preprocessing_function=preprocess_input)
train_generator = train_data_generator.flow_from_directory
(directory= TRAIN_PATH,
target_size=IMAGE_SIZE,
color_mode= 'rgb',
class_mode= 'categocal',
batch_size= BATCH_SIZE)
val_generator = test_data_generator.flow_from_directory
(directory= VAL_PATH,
target_size=IMAGE_SIZE,
color_mode= 'rgb',
class_mode= 'categorical',
batch_size= BATCH_SIZE)
Мы будем использовать модель MobileNetv3, предварительно обученную на ImageNet, в качестве задачи трансферного обучения с оптимизатором Adam.
base = MobileNetV3Large(weights='imagenet', include_top=False)
base.trainable = False
model = Sequential([
base,
layers.GlobalAveragePooling2D(),
layers.Dense(256, activation='relu'),
layers.Dropout(0.1),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes, activation = 'softmax')
])
model.compile(
optimizer="adam",
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Начинаем обучение на 10 эпохах
Эпоха (Epoch) – количество повторений циклов обучения для всей выборки данных
# Импортируем библиотеку time, чтобы измерить время обучения модели
import time
start = time.time()
history = model.fit_generator(train_generator, valida-tion_data=val_generator, epochs=10)
print("Total time: ", time.time() - start, "seconds")

Визуализация потерь и точности.
Точность – процент правильных предсказаний модели.
Потери – расхождение между предсказанными и истинными значениями.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.style.use('ggplot')
# Отрисовываем график изменения точности
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
# Отрисовываем график изменения потерь
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
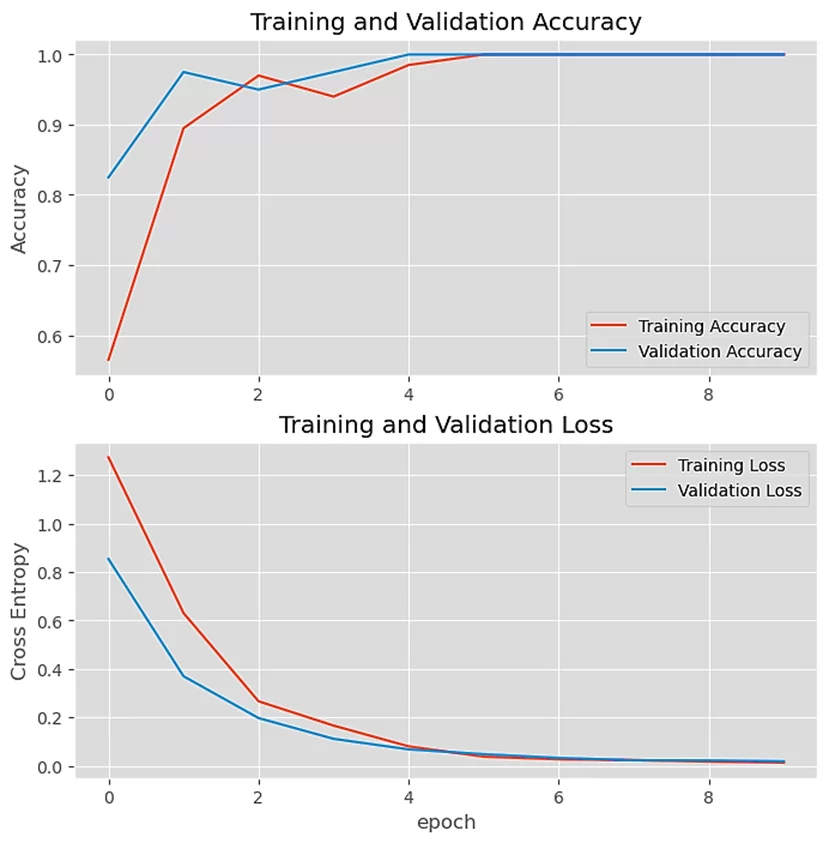
model.save('MobileNetV3Large.h5')На данных графиках мы можем видеть, как изменяется точность и потери в зависимости от количества эпох, на их основании можно сделать вывод, что после обучения на 8 эпохах наша модель работает с максимальной точностью и минимальными потерями.
Протестируем модель на случайном изображении из тестового набора.
from keras.preprocessing import image
from tensorflow.keras.utils import load_img
# Загружаем изображение
img = load_img("/kaggle/input/signature-verification-and-identification/Test/PersonE/Copy of personE_22.png",target_size=(224,224))
img = np.asarray(img)
plt.imshow(img)
img = np.expand_dims(img, axis=0)
img= preprocess_input(img)
output = saved_model.predict(img)
print(output)
if np.argmax(output) == 0 :
print("PersonA")
elif np.argmax(output) == 1 :
print("PersonB")
elif np.argmax(output) == 2 :
print("PersonC")
elif np.argmax(output) == 3 :
print("PersonD")
elif np.argmax(output) == 4 :
print("PersonE")
Результат:
1/1 [==============================] - 1s 1s/step
[[4.0784580e-06 1.9883872e-04 1.6808448e-05 5.4550100e-08 9.9978024e-01]]
PersonE
В итоге наша модель определила чья это подпись, что наглядно демонстрирует как компьютерное зрение может применяться в аудите.
Преимущества и риски, связанные с машинным обучением
Применение машинного обучения в аудите может иметь следующие преимущества:
- Автоматизация и повышение эффективности: машинное обучение позволяет автоматизировать рутинные задачи аудита, такие как анализ больших объемов данных, обнаружение аномалий и классификация транзакций. Это может значительно ускорить процесс аудита и освободить аудиторов от монотонных задач.
- Улучшение точности и качества: машинное обучение позволяет анализировать данные с точностью и скоростью, недоступными для человека. Алгоритмы машинного обучения могут обнаруживать скрытые закономерности и зависимости в данных, что способствует выявлению потенциальных ошибок, мошенничества и неправильных действий.
- Улучшенное прогнозирование и предсказание: машинное обучение может помочь в прогнозировании будущих тенденций, рисков и результатов аудита на основе исторических данных и моделей. Это позволяет аудиторам принимать основанные на данных решения и предупреждать о потенциальных проблемах или рисках заранее.
Тем не менее, применение машинного обучения в аудите также сопряжено с некоторыми рисками:
- Неправильные результаты: некорректное обучение моделей машинного обучения или использование неподходящих алгоритмов может привести к неверным результатам и выводам. Неправильные предсказания или классификация могут повлечь за собой неправильные решения и потенциальные упущения в аудите.
- Неадекватные данные: качество и надежность результатов машинного обучения зависит от доступности и качества данных. Недостаточные или искаженные данные могут привести к неправильным выводам и искажению результатов анализа.
- Сложность интерпретации: некоторые модели машинного обучения, такие как нейронные сети или ансамбли моделей, могут быть сложными для интерпретации и объяснения результатов. Это может создать трудности в объяснении выводов аудиторской работы и прозрачности процесса.
- Зависимость от технической экспертизы: применение машинного обучения требует наличия специалистов по данным и машинному обучению в аудиторских командах. Недостаток необходимых знаний и навыков может ограничить возможности использования машинного обучения в аудите.
В целом, применение машинного обучения в аудите может представлять значительные преимущества, но требует осторожного подхода, правильного подбора моделей и алгоритмов, а также надлежащего учета рисков и нюансов, связанных с данными и интерпретацией результатов.
Итог
Подытожить можно так: ML – довольно перспективное направление, которое может значительно улучшить эффективность и точность аудиторской работы, но важно подходить к использованию ML с осторожностью, учитывая особенности каждой конкретной ситуации.