/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В прошлом посте (ссылка) я измеряла опоссумов линейной регрессией, предсказывала размеры тела по остальным метрикам. А что, если необходимо не предсказать значение, а разбить на классы? Например, мальчик или девочка, место ловли опоссума или популяцию.
В таком случае необходимо произвести классификацию. Предлагаю воспользоваться логистической регрессией. Отличие от линейной в том, что не производится предсказание значения числовой переменной. Результатом является вероятность возникновения события. Оценка вероятности происходит путем сравнения события с логистической кривой.
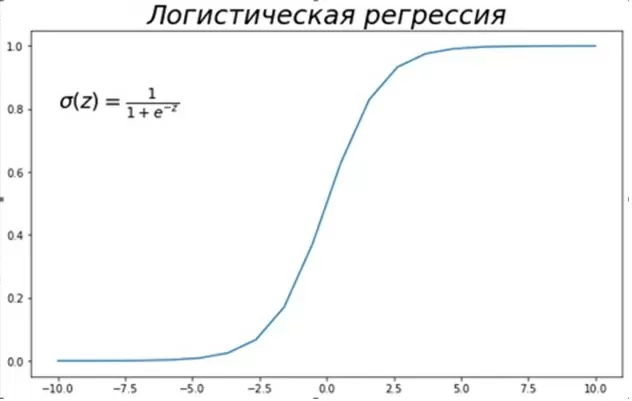
Значением логистической регрессии является вероятность (значения от 0 до 1) того, что событие наступит событие для конкретного объекта. Не вдаваясь в математику, в логистической регрессии есть коэффициенты — β₀, β₁,…βd. Для того, чтобы разделить объекты, необходимо пространство признаков значений разделить линейной границей на области, соответствующие 2 классам. Это возможно при β₀ + β₁x1+…+βdxd =0.
Предлагаю использовать уже знакомый нам датасет про опоссумов. Датасет содержит данные измерения различных частей тела каждого опоссума, популяцию и место ловли (от Южной Виктории до центрального Квинсленда).
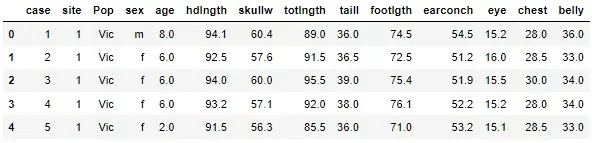
Загружу датасет с Kaggle и произведу предобработку данных как в прошлой публикации – бинаризирую данные и проверю на Nan. Для построения логистической регрессии буду использовать библиотеку sklearn.
Весь код размещен здесь. В этот раз я предлагаю не удалять Nan, а заменить их средними значениями по столбцу. Для начала нужно понять, в каких столбцах встречаются пропущенные значения, а затем найти их строки.
df_possum.isna().any()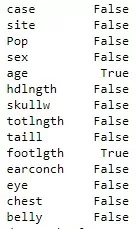
Видно, что Nan есть в возрасте и длине ног. Заменю их средними значениями:
df_possum.age.fillna(df_possum['age'].mean(), inplace=True)
df_possum.footlgth.fillna(df_possum['footlgth'].mean(), inplace=True)
Для начала предлагаю классификацию на 2 класса, а именно предсказать пол опоссума на основе данных его тела. Предобработанные данные выглядит так:
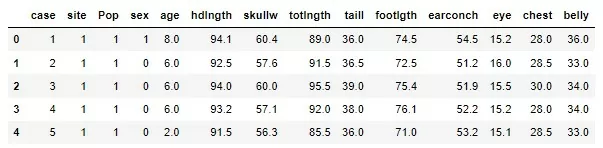
Какие данные из всего датасета необходимы? Логично, что case – номер наблюдения, site – номер места, где был пойман опоссум, pop – популяция и age – возраст не влияют на пол, соответственно, их нужно удалить перед дальнейшим анализом.
df_possum_sex = df_possum.drop(['case', 'Pop', 'age', 'site'], axis=1)
df_possum_sex.head()
Получаю датасет для определения пола с помощью логистической регрессии:
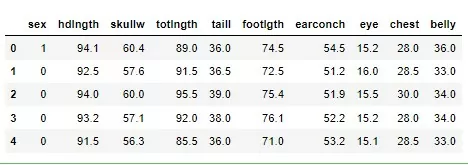
Отбираю зависимую переменную (у) и независимые переменные (Х):
X = df_possum_sex.iloc[:, 1:]
y = df_possum_sex['sex']Так как логистическая регрессия чувствительна к масштабируемости данных, понадобится нормализация данных.
X = (X - X.mean(axis=0)) / (X.std(axis=0, ddof=1))Получаю нормализованные данные:
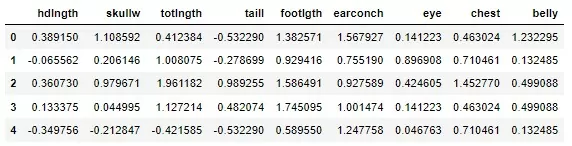
Делю выборку на тренировочную и тестовую
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size = 0.7, random_state = 777, stratify=y)Теперь обучу логистическую модель и посмотрю на её предсказательные качества с помощью метрик
logreg_model = LogisticRegression()
logreg_model.fit(X_train, y_train)
Precision: 0.7
Recall: 0.7777777777777778
F - мера 0.7368421052631577
Предлагаю вспомнить, что означает каждая из метрик:
Precision (positive predictive value):
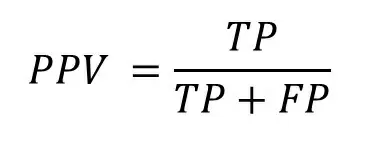
− точность — доля объектов, названных классификатором положительными и при этом действительно являющимися положительными.
Recall (true Positive Rate):
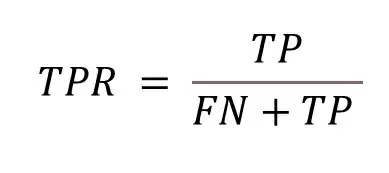
– чувствительность или полнота — доля положительных объектов, которые алгоритм определил из всех положительных объектов.
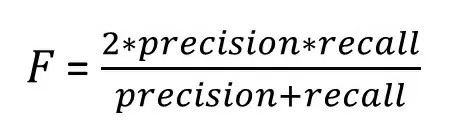
− F-мера — среднее между чувствительностью и точностью. F-мера − хорошая формальная оценка качества модели (классификатора). Она сводит к одному числу две других основополагающих метрики: precision и recall.
Я получила средние результаты, судя по метрикам. Можно ли их улучшить?
Можно. Для защиты от переобучения используют регуляризацию (о ней можно почитать в статье). Она не позволяет модели сильно переобучаться, вводя штрафы за слишком сложную модель. У регуляризации есть параметры, которые можно подобрать для улучшения качества классификации. С помощью функции GridSearchCV из библиотеки sklearn, она позволяет отбирать лучшие параметры для заданной модели – проводить кросс валидацию.
logreg_model = LogisticRegression(penalty='l2')
grid_cv = GridSearchCV(logreg_model, param_grid={'C':np.arange(0.01, 1, 0.01)}, cv=10, n_jobs=-1)
grid_cv.fit(X_train, y_train)
opt_C = grid_cv.best_estimator_.C
Обучу модель с лучшим параметром С и посмотрю на ошибки:
best_logreg_model = LogisticRegression(penalty='l2', C=opt_C)
best_logreg_model.fit(X_train, y_train)
print(f'Precision: {metrics.precision_score(y_test, y_predicted)}')
print(f'Recall: {metrics.recall_score(y_test, y_predicted)}')
print(f'F - мера {metrics.f1_score(y_test, y_predicted)}')
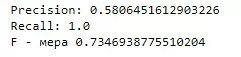
Они не улучшились, а можно даже сказать, что стали хуже. Но у этой функции есть ещё один интересный параметр – cv. Он определяет стратегию разбиения датасета при кросс-валидации (об этом подробнее в следующем посте).
Default cv = 5, увеличу этот параметр до 10, время на кросс-валидацию также увеличится. Затем обучу модели на полученном лучшем значении и посмотрю на ошибки.
grid_cv = GridSearchCV(logreg_model, param_grid={'C': np.arange(0.01, 1, 0.01)}, cv=10, n_jobs=-1)Остальной код такой же как в посте выше
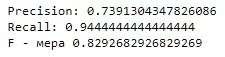
Показатели заметно улучшились, то есть удалось сделать более качественную модель.
Теперь попробую узнать, а где поймали опоссума на основе всех данных. У меня уже есть предобработанный датасет. Для дальнейшего анализа не нужен только столбец с номером наблюдения (case), удаляю его и отберу Х и у, а также нормализую данные.

Разделю выборку на тестовую и тренировочную. С помощью GridSearchCV опять получу лучший параметр и обучу модель. Необходимо посмотреть на F – ошибку:
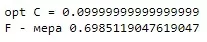
Получено невысокое значение F — меры. В чем может быть причина? Нужно посмотреть на баланс классов с помощью гистограммы из Seaborn
import seaborn as sns
sns.histplot(data=df_possum,x="site",discrete=True, hue="site")
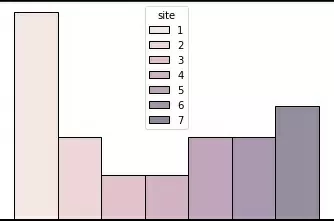
Видно, что разделение по классам неравномерное, очень много из класса 1 и мало в 3 и 4. В идеале необходимо увеличить выборку за счет классов 2 – 7, чтобы классы были более сбалансированные.
А вот видов всего 2 класса – Victoria и другие. Попробую по такому же алгоритму определить популяцию.
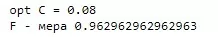
Получила прекрасно обученную модель. Классы достаточно сбалансированы:
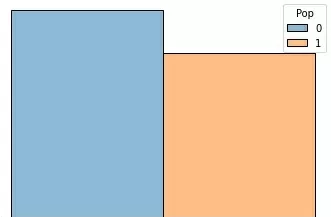
Таким образом, построена регрессионная модель, которая классифицирует 3 различных признака. Видно, что на маленьких датасетах лучше классификация на бинарном разделении классов, на мульти классах она тоже работает, но чем сбалансирование класс, тем и классификация лучше.