/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Отчёт – это особая форма представления данных. Он позволяет пользователю познакомиться с отобранными, агрегированными и особо оформленными данными. На сегодняшний день формирование и представление отчетов все еще является актуальной формой доведения до пользователя информации.
В этой статье рассматривается один из способов автоматического формирования отчета в формате файла MS WORD, начиная от непосредственного запроса к данным БД MSSQL и заканчивая его оформлением. В качестве инструментария используется python и модуль docx.
Для начала ознакомимся с используемыми данными. В БД имеются 3 таблицы с данными о товарах, покупателях и продажах.
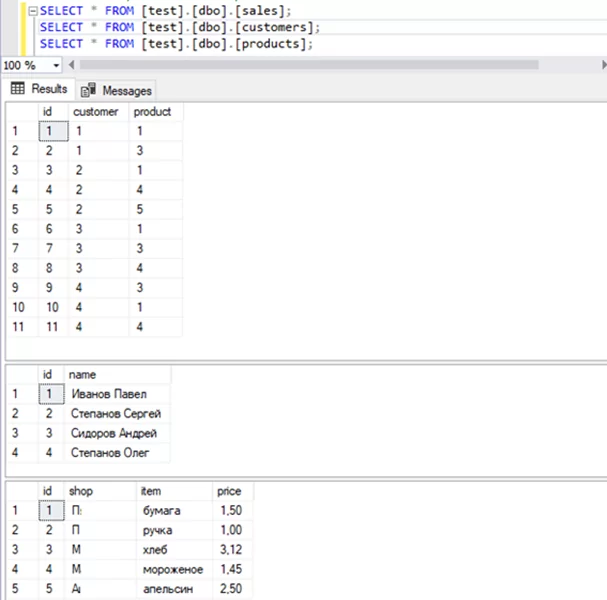
Для начала нам понадобится импортировать в код необходимые модули:
from docx import Document
import pandas as pd
import pandas.io.sql as psql
import matplotlib.pyplot as plt
from io import BytesIO
import pyodbc
Создаем соединение и формируем запрос. На данном этапе пользователю следует определиться с составом запрашиваемых запросом данных исходя из имеющейся задачи, т.е. на каком этапе производятся расчеты, агрегирование и/или фильтрация данных. В нашем случае будут запрашиваться данные всех продаж с привязкой к ФИО покупателя и данным о товаре. Обработка данных будет производится с помощью модуля pandas.
cnxn = pyodbc.connect("Driver={SQL Server Native Client 11.0};"
"Server=S1;"
"Database=test;"
"uid=sa;pwd=pass;"
"Trusted_Connection=yes;")
cursor = cnxn.cursor()
sql = '''select
c.name
,p.*
from [dbo].[sales] s
join [dbo].[customers] c
on c.id = s.customer
join [dbo].[product] p
on s.product = p.id'''
Полученные данные отправляем в dataframe, закрываем соединение
df = psql.read_sql_query(sql,cnxn)
cnxn.close()
del df['id'] # ненужный столбец df
Следующий этап – непосредственно создание документа.
document = Document() # создается объект
# добавляем первый заголовок
document.add_heading('Отчет о продажах', 0)
# добавляем простой текст с переменными из
# данных таблицы (названия магазинов)
shop_list = ', '.join(df['shop'].unique().tolist())
p = document.add_paragraph('Отчет о продажах в магазинах: ')
# к тексту добавим сам список, выделяем жирным шрифтом
p.add_run(shop_list).bold = True
Формируем таблицу о всех продажах – аналог входных данных запроса.
document.add_heading('Общие продажи', level=1) # заголовок
rows, columns = df.shape # размеры dataframe
table = document.add_table(rows=1, cols=columns) # создаем таблицу
table.style = "Colorful List Accent 1" # определяем стиль
# формируем заголовки таблицы
hdr_cells = table.rows[0].cells
for i in range(columns):
hdr_cells[i].text = list(df.columns.values)[i]
# заполняем данными из dataframe
for row in range(rows):
row_cells = table.add_row().cells
row_data = df.iloc[row].tolist()
for column in range(columns):
row_cells[column].text = str(row_data[column])
На выходе получается следующий документ.

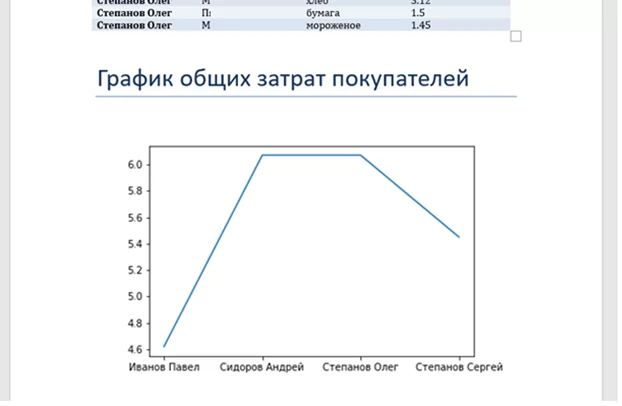
Какой же отчет бывает без графиков. Для примера, создадим график затрат в разрезе клиентов.
# заголовок
document.add_heading(' ', 0)
document.add_heading('График общих затрат покупателей', 0)
# пустой объект, куда будет помещен plot
memfile = BytesIO()
fig = plt.figure()
# данные для графика: клиенты и суммы затрат
plt.plot(df.groupby('name')['price'].sum())
fig.savefig(memfile)
document.add_picture(memfile) # размещение в документе
document.save('demo.docx') # публикация в файловой системе
На выходе получаем.
Это далеко не все возможности модуля docx, позволяющие произвести верстку документа «на лету» с использованием данных, взятых непосредственно из БД и агрегированных с помощью Python. Более подробную информацию о верстке, использовании стилей, вставке объектов и т.п. можно ознакомится на сайте разработчиков https://python-docx.readthedocs.io.