/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
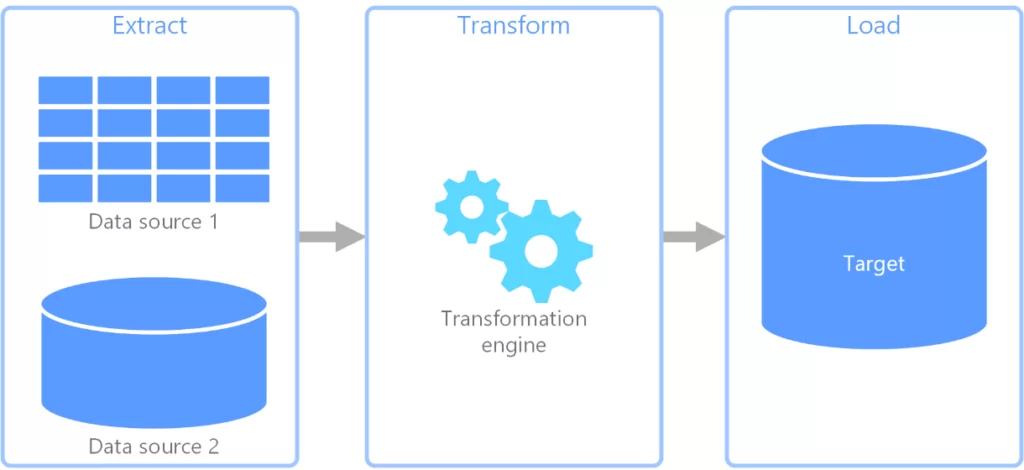
При проведении проверок и реализации проектов/спринтов повсеместно встречаются ситуации, когда аналитикам и IT-специалистам при выполнении задач требуется получить информацию из различных источников данных. Часто эти данные передаются из одного источника в другой с целью их компоновки и агрегации. В IT этот процесс носит название ETL (от англ. Extract, Transform, Load – извлечение, преобразование и загрузка). Как видно из названия, этот процесс состоит из 3 этапов:
- Извлечение данных из исходного источника данных (будь то табличные файлы, или информация с базы данных);
- Преобразование и очистка извлеченных данных;
- Загрузка данных в целевой источник данных.
Несмотря на то, что в настоящее время существует множество инструментов для организации ETL-процесса, я, как IT-специалист, часто сталкиваюсь с ситуациями, когда организовать такой процесс надо в сжатые сроки. В таких случаях, конечно, проще выполнить решение этой задачи «на коленке» с помощью Python.
Самый распространенный вариант такого решения:
- Загрузить данные из исходного источника (пусть это будет БД) с помощью библиотек (pymssql, cx_Oracle, pyodbc)
- Поместить в промежуточную структуру в памяти компьютера, например, pandas.dataframe
- Загрузить данные из этой структуры в нужную БД (приёмник).
Звучит просто? Я тоже считал это решение простым и оптимальным.
Пока мне однажды не потребовалось передать 10 ГБ данных из одной БД в другую.

Учитывая, что в целом у многих библиотек для Python отмечается такая проблема, как неоптимизированная работа с памятью – а это приводит к тому, что при хранении большого объема данных память быстро забивается и ваш компьютер зависает. Вариант решения этой проблемы представлен ниже.
Для начала настроим соединения с источниками данных.
# Библиотеки для работы с БД
import cx_Oracle
import pyodbc
#Oracle – соединение (источник)
v_tns=cx_Oracle.makedsn('hostname', '8000', service_name='service_name') # создаем строку подключения
try:
v_conn_ora=cx_Oracle.connect(user='user', password='password', dsn=v_tns)
v_cur_ora=v_conn_ora.cursor()
except cx_Oracle.DatabaseError as info:
print("Logon Error:", info)
#MS SQL – соединение (приемник)
v_conn_ms=pyodbc.connect("Driver={ODBC Driver 11 for SQL Server}; server=server_name; Trusted_Connection=yes;")
v_cur_ms=v_conn_ms.cursor()
После этого напишем SQL-запросы на SELECT и INSERT, с помощью которых библиотеки будут работать с данными.
--Запрос на выбор данных из исходной таблицы
SELECT
FIELD1,
FIELD2,
FIELD3
FROM TABLE
-- Запрос на вставку полученных данных в новую таблицу
INSERT INTO NEW_TABLE
(
FIELD1,
FIELD2,
FIELD3
)
VALUES(?, ?, ?)
Отмечу, что у библиотек для работы с данными есть разные варианты загрузки результатов запросов в память:
- Загрузить все строки результата запроса сразу;
- Загрузить некоторое количество строк результата запроса;
- Загрузить одну строку результата запроса.
В данном случае нас интересует вариант построчной загрузки из БД-источника и записи в БД-приёмник, т.к. в таком случае приложение не будет расходовать память на хранение большого объема данных. Реализация ETL-процесса с использованием построчной загрузки и записи (метод fetchone() ) представлена ниже:
v_cur_ora.execute(query_select) # выполняем запрос на SELECT
while True:
row = v_cur_ora.fetchone() # выгружаем одну строку из источника
if row == None:
break
v_cur_ms.execute(query_insert, (row[0], row[1], row[2])) # загружаем выгруженную строку в приемник
v_conn_ms.commit() # фиксируем изменения
Также следует отметить, что похожую реализацию ETL-процесса можно сделать с помощью загрузки/записи нескольких строк с помощью метода fetchmany(). Это позволит немного ускорить ETL-процесс и найти разумный компромисс между скоростью и расходом памяти.
v_cur_ora.execute(query_select) # выполняем запрос на SELECT
while True:
rows = v_cur_ora.fetchmany(5) # выгружаем 5 строк из источника
if not rows:
break
for row in rows:
v_cur_ms.execute(query_insert, (row[0], row[1], row[2]))
v_conn_ms.commit() # фиксируем изменения
Вот так с помощью маленькой хитрости можно отказаться от хранения всего объема передаваемых данных и добиться стабильной работы скрипта и компьютера, что поможет Вам сохранить свое время.
Удачи в работе!