/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
На этапе загрузки небольших объемов данных в Python не возникает проблем в части сохранения информации. Чаще всего данные загружают в DataFrame с помощью библиотеки pandas, после чего их обрабатывают. Но когда объем входных данных занимает несколько десятков Гигабайт, скорость вставки строк в DataFrame постепенно падает. Особенно эта проблема ощутима, если необходимо построчно обрабатывать информацию, например, когда данные из файла .csv требуют дополнительной обработки (применение регулярных выражений для выбора нужных данных, расчеты и т.д.). Рассмотрим на примере эту ситуацию и перейдем к одному из способов решения возникающей проблемы.
Сгенерируем 10 тыс. различных строк вставляя каждую в DataFrame и зафиксируем общее время выполнения.
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
columns = ['iter', 'first_col', 'second_col', 'text']
dataframe_test = pd.DataFrame(columns = columns)
start_test = datetime.now()
for itr in range(1, 10001):
first_col = itr * 1000
second_col = itr * 10000
text = 'TEST ' * 10
dataframe_test = dataframe_test.append(dict(zip(columns, [itr, first_col, second_col, text])), ignore_index = True)
end_test = datetime.now()
print('Время выполнения: %s' % str(end_test - start_test))
На выполнение данного действия потребовалось 33.86 сек (на разных ПК время выполнения может отличаться, как в этом примере так и в последующих). Попробуем изменить алгоритм вставки данных. Вместо использования метода append для вставки в DataFrame создаем массив, в который будут записаны значения из входных строк в виде массива. В итоге получим массив из массивов вида [[…],[…],[…]], который можно легко превратить в DataFrame.
columns = ['iter', 'first_col', 'second_col', 'text']
test_array = []
start_test = datetime.now()
for itr in range(1, 10001):
first_col = itr * 1000
second_col = itr * 10000
text = 'TEST ' * 10
test_array.append([itr, first_col, second_col, text])
array_test = pd.DataFrame(data = test_array, columns = columns)
end_test = datetime.now()
print('Время выполнения: %s' % str(end_test - start_test))
На выполнение данного действия потребовалось 0.031 сек. При этом перечень значений в итоговом DataFrame точно такой же, как и в предыдущем примере. В итоге время получения необходимого DataFrame значительно сократилось.
Чаще необходимо загружать в DataFrame несколько строк, например, в случае загрузки данных из базы данных. Попробуем ускорить загрузку данных с сервера при помощи указанного ранее способа, но уже для нескольких строк. Для этого создадим в MS SQL Server таблицу и заполним ее данными.
create table [SANDBOX].[dbo].[test_table]
(
[iter] int
,[first_col] bigint
,[second_col] bigint
,[text] varchar(50)
)
declare @itr_len int = 10000
declare @itr int = 1
declare @first_col bigint
declare @second_col bigint
declare @text as varchar(50)
while @itr_len >= @itr
begin
set @first_col = @itr * 1000
set @second_col = @itr * 10000
set @text = REPLICATE('TEST ', 10)
insert into [SANDBOX].[dbo].[test_table] ([iter], [first_col], [second_col], [text]) values (@itr, @first_col, @second_col, @text)
set @itr = @itr + 1
end
Из полученной таблицы загрузим все значения 300 раз, чтобы проверить, зависит ли изменение времени вставки в DataFrame от количества уже хранящихся в нем данных. Для большей наглядности сохраним все значения затраченного времени на вставку в массив, чтобы на графике увидеть изменения.
import pyodbc
server = 'Тут необходимо указать сервер или его IP'
conn = pyodbc.connect('Driver={SQL Server Native Client 11.0};Server='+server+';Network Library=DBMSSOCN;Trusted_Connection=Yes')
time_diff = []
columns = ['iter', 'first_col', 'second_col', 'text']
dataframe_test = pd.DataFrame(columns = columns)
for itr in range(1, 301):
start_test = datetime.now()
dataframe_test = dataframe_test.append(pd.read_sql("select * from [SANDBOX].[dbo].[test_table]", con = conn, columns = columns), ignore_index = True)
end_test = datetime.now()
print('Время выполнения: %s' % str(end_test - start_test))
time_diff.append(end_test - start_test)
plt.plot([i.total_seconds() for i in time_diff])
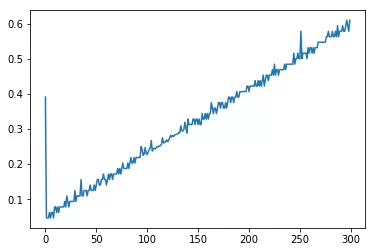
На графике отражено время каждой вставки данных в таблицу. Чем больше строк записано в DataFrame, тем больше времени уходит на вставку новых значений.
Теперь проверим, как изменяется время вставки при использовании массива.
time_diff = []
columns = ['iter', 'first_col', 'second_col', 'text']
test_array = []
for itr in range(1, 301):
start_test = datetime.now()
df_array = pd.read_sql("select * from [SANDBOX].[dbo].[test_table]", con = conn).values
[test_array.append(list(i)) for i in df_array]
end_test = datetime.now()
print('Время выполнения: %s' % str(end_test - start_test))
time_diff.append(end_test - start_test)
start_test = datetime.now()
array_test = pd.DataFrame(data = test_array, columns = columns)
end_test = datetime.now()
print('Время формирования DataFrame: %s' % str(end_test - start_test))
plt.plot([i.total_seconds() for i in time_diff])
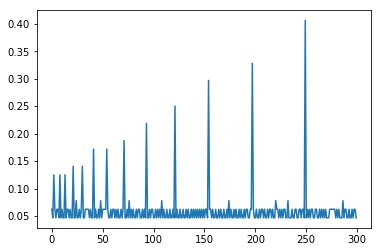
На графике видно, что время на вставку данных не растет постоянно, как при выполнении вставки сразу в DataFrame с помощью метода append. Запись данных в массив и последующее создание DataFrame из полученных данных заметно сокращает время на загрузку, что особенно ощущается при работе с большими объемами информации.