/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
В современном мире, где фотографии играют огромную роль в сфере социальных медиа, онлайн-безопасности и контроля содержимого, важно иметь эффективные инструменты для обнаружения нежелательных предметов на изображениях. В данной публикации мы рассмотрим практическое применение двух из самых популярных моделей YOLO и ResNet для обнаружения нежелательных предметов на фотографиях.
YOLO (You Only Look Once) – это одна из наиболее известных моделей для обнаружения объектов на изображениях в реальном времени. Она основана на сверхточных нейронных сетях и позволяет достичь высокой скорости обработки без ущерба точности. YOLO разделяет изображение на сетку ячеек и каждая ячейка предсказывает границы и классы объектов, содержащихся внутри нее.
ResNet (Residual Neural Network) – это глубокая нейронная сеть, разработанная для решения проблемы затухания градиента. Она использует концепцию «skip connections» или «residual connections», позволяющих передавать информацию непосредственно от одного слоя к другому, минуя промежуточные слои. Это позволяет обучать более глубокие сети с лучшей производительностью.
Предлагаем рассмотреть практический пример использования моделей для обнаружения нежелательных предметов на фотографиях. У нас имеется массив адресов изображений в объявлениях сайта ДомКлик. Нашей задачей был поиск на изображениях таких нежелательных элементов, как оружие, алкогольные напитки, сигареты или экстремистские символы вроде свастики.
Первым шагом будет чтение csv-файла с адресами изображений и их загрузка.
import os
import shutil
from urllib.request import Request, urlopen
URL = 'https://img.dmclk.ru/vitrina/owner/'
import pandas as pd
from tqdm import tqdm
def loader(url_input, local_path):
url = URL + url_input
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
with urllib.request.urlopen(req) as response, open(local_path, 'wb') as out_file:
shutil.copyfileobj(response, out_file)
photo_df = pd.read_csv('full_sample_photo_res.csv', sep='^')
photo_df.loc[:, 'list_url'] = photo_df['list_url'].apply(lambda x: x.split(','))
os.makedirs('photos', exist_ok=True)
df = photo_df.explode('list_url', ignore_index=True)
for i in tqdm(df.index):
file_name = os.path.basename(df.loc[i, 'list_url'])
local_path = f'photos/{file_name}'
loader(df.loc[i, 'list_url'], local_path)
df.loc[i, 'local_path'] = local_path
Для примера мы хотим найти изображения с ножами.
Модель YOLO8x
Разработчики имеют предобученные модели в открытом доступе. Помимо этого, они предлагают возможность провести обучение моделей на их вычислительных ресурсах, если собственных мощностей не хватает.
Запускаем предобученную модель YOLO v8x для определения объектов (Detection) на 1000 фотографиях из Domclick.ru. Для выполнения задачи используем программу:
from roboflow import Roboflow
import os
HOME = os.getcwd()
from IPython import display
display.clear_output()
import ultralytics
from ultralytics import YOLO
from IPython.display import display, Image
from threading import Event, Thread
from queue import Empty, Queue
import shutil
from urllib.error import HTTPError
from urllib.request import Request, urlopen
import pandas as pd
from tqdm import tqdm
THREADS = 11
RESULT_FILE = 'result.csv'
URL = 'https://img.dmclk.ru/vitrina/owner/'
PHOTO_PATH = 'photos'
STOP_EVENT = Event()
def img_loader(url_input, local_path):
url = URL + url_input
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
with urlopen(req) as response, open(local_path, 'wb') as out_file:
shutil.copyfileobj(response, out_file)
def worker(input_queue: Queue, output_queue: Queue):
#model = YOLO('yolov8x.pt')
while not STOP_EVENT.is_set():
try:
try:
img = input_queue.get()
except Empty:
tqdm.write('thread stop')
break
img_name = os.path.basename(img)
img_path = f'{PHOTO_PATH}/{img_name}'
print(img_path)
try:
img_loader(img, img_path)
res1 = model.predict(img_path, conf=0.25, save_txt=True, save_conf=True)
palette = 1
img_sus = 1
output_queue.put((img, img_sus, palette))
os.remove(img_path)
except HTTPError:
output_queue.put((img, '404', None))
except Exception as e:
tqdm.write(e.__str__())
output_queue.put('DONE')
print('thread finished')
def listener(output_queue: Queue, total_files: int):
pbar = tqdm(total=total_files)
working_threads = THREADS
while working_threads:
try:
try:
item = output_queue.get()
except Empty:
continue
if item == 'DONE':
working_threads -= 1
else:
line = f'{item[0]};{item[1]};{item[2]}\n'
with open(RESULT_FILE, 'a') as r:
r.write(line)
pbar.update(1)
except KeyboardInterrupt:
tqdm.write('STOP')
STOP_EVENT.set()
pbar.close()
input_queue = Queue()
output_queue = Queue()
model = YOLO('yolov8n.pt')
photo_df = pd.read_csv('photo3.csv', sep='^')
photo_df.loc[:, 'list_url'] = photo_df['list_url'].apply(lambda x: x.split(','))
df = photo_df.explode('list_url', ignore_index=True)[1:]
df.drop_duplicates(subset=['list_url'], inplace=True, ignore_index=True)
to_process = df.loc[:, 'list_url'].tolist()
try:
processed = pd.read_csv(RESULT_FILE, sep=';')
processed_files = processed.loc[:, 'file'].tolist()
to_process = set(to_process).difference(processed_files)
except FileNotFoundError:
with open(RESULT_FILE, 'w') as r:
r.write('file;is_file_sus;palette\n')
total = len(to_process)
for file in to_process:
input_queue.put(file)
threads = []
for i in range(THREADS):
print(f'thread {i} launching')
thread = Thread(target=worker, args=(input_queue, output_queue))
threads.append(thread)
thread.start()
print(f'listener launching')
listener(output_queue, len(df['list_url']))
print('empying queue')
while not input_queue.empty():
input_queue.get()
Команда для запуска
model = YOLO('yolov8x.pt')
res1 = model.predict(img_path, conf=0.25, save_txt=True, save_conf=True)
Результаты будут записываться в текстовый файл и выводиться на экран.
Определение предметов заняло примерно 16 минут времени. Было определено 686 предметов. Произведем поиск на экране по слову knife (Нож) и находим фото, где были обнаружены ножи:
image 1/1 C:\Users\chimb\WORK\photos\b77190191fbf40d18f1cca62ddbcdd84.jpg: 480×640 3 bottles, 4 cups, 2 knifes, 2 spoons, 2 bowls, 1 bed, 1 dining table, 1 tv, 2 ovens, 1 sink, 7429.8ms

image 1/1 C:\Users\chimb\WORK\photos\8bd91f5dc622460c91119d168e199b2d.jpg: 384×640 3 bottles, 1 fork, 8 knifes, 1 spoon, 1 sink, 7209.2msапиапи

480×640 2 bottles, 2 cups, 1 knife, 1 bowl, 1 chair, 1 dining table, 1 cell phone, 1 oven, 1 refrigerator, 11615.4ms

640×480 6 bottles, 1 knife, 1 bowl, 2 bananas, 1 carrot, 1 microwave, 1 oven, 1 sink, 10649.5ms

640×480 2 bottles, 1 cup, 1 fork, 2 spoons, 4 bowls, 2 chairs, 1 dining table, 1 oven, 1 book, 5815.3ms
Модель RESNET101
Запустим задачу определения объектов (Detection) на 1000 фотографиях из Domclick.ru, используя модель RESNET101. Для запуска задачи используем программу:
from torchvision import models
#dir(models)
# Загружаем resnet-101 layers pre-trained model
#
resnet = models.resnet101(weights=True)
#
#
resnet
resnet.eval()
import torch
from PIL import Image
from torchvision import transforms
def preprocessing(img):
#
# Фунция производит предварительную обработку
#
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)])
img_cat_preprocessed = preprocess(img)
batch_img_cat_tensor = torch.unsqueeze(img_cat_preprocessed, 0)
return batch_img_cat_tensor
def labeler(tens):
with open('c:/Users/chimb/.fastai/data//imagenet_classes.txt') as f:
labels = [line.strip() for line in f.readlines()]
_, index = torch.max(tens, 1)
percentage = torch.nn.functional.softmax(tens, dim=1)[0] * 100
print(labels[index[0]], percentage[index[0]].item())
_, indices = torch.sort(tens, descending=True)
[(labels[idx], percentage[idx].item()) for idx in indices[0][:5]]
from threading import Event, Thread
import os
from queue import Empty, Queue
import shutil
from urllib.error import HTTPError
from urllib.request import Request, urlopen
import pandas as pd
from tqdm import tqdm
THREADS = 11
RESULT_FILE = 'result.csv'
URL = 'https://img.dmclk.ru/vitrina/owner/'
PHOTO_PATH = 'photos'
STOP_EVENT = Event()
def img_loader(url_input, local_path):
url = URL + url_input
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
with urlopen(req) as response, open(local_path, 'wb') as out_file:
shutil.copyfileobj(response, out_file)
def worker(input_queue: Queue, output_queue: Queue):
while not STOP_EVENT.is_set():
try:
try:
img = input_queue.get()
except Empty:
tqdm.write('thread stop')
break
img_name = os.path.basename(img)
img_path = f'{PHOTO_PATH}/{img_name}'
print(img_path)
try:
img_loader(img, img_path)
img_cat = Image.open(img_path).convert('RGB')
img_prep = preprocessing(img_cat)
out = resnet(img_prep)
labeler(out)
palette = 1
img_sus = 1
output_queue.put((img, img_sus, palette))
os.remove(img_path)
except HTTPError:
output_queue.put((img, '404', None))
except Exception as e:
tqdm.write(e.__str__())
output_queue.put('DONE')
print('thread finished')
def listener(output_queue: Queue, total_files: int):
pbar = tqdm(total=total_files)
working_threads = THREADS
while working_threads:
try:
try:
item = output_queue.get()
except Empty:
continue
if item == 'DONE':
working_threads -= 1
else:
line = f'{item[0]};{item[1]};{item[2]}\n'
with open(RESULT_FILE, 'a') as r:
r.write(line)
pbar.update(1)
except KeyboardInterrupt:
tqdm.write('STOP')
STOP_EVENT.set()
pbar.close()
input_queue = Queue()
output_queue = Queue()
photo_df = pd.read_csv('photo3.csv', sep='^')
photo_df.loc[:, 'list_url'] = photo_df['list_url'].apply(lambda x: x.split(','))
df = photo_df.explode('list_url', ignore_index=True)[1:]
df.drop_duplicates(subset=['list_url'], inplace=True, ignore_index=True)
to_process = df.loc[:, 'list_url'].tolist()
try:
processed = pd.read_csv(RESULT_FILE, sep=';')
processed_files = processed.loc[:, 'file'].tolist()
to_process = set(to_process).difference(processed_files)
except FileNotFoundError:
with open(RESULT_FILE, 'w') as r:
r.write('file;is_file_sus;palette\n')
total = len(to_process)
for file in to_process:
input_queue.put(file)
threads = []
for i in range(THREADS):
print(f'thread {i} launching')
thread = Thread(target=worker, args=(input_queue, output_queue))
threads.append(thread)
thread.start()
print(f'listener launching')
listener(output_queue, len(df['list_url']))
print('empying queue')
while not input_queue.empty():
input_queue.get()Результаты будут записываться в текстовый файл и выводиться на экран.
Производим поиск на экране по слову knife (Нож) и определяем, что ножи не обнаружены. Можно сделать вывод о том, что модель YOLO показывает лучший результат в данной задаче.
Далее мы проводим дообучение наших моделей на датасете ножей. Возможно, это даст нам лучший результат.
Подключаем готовую обученную модель с ножами с сайта https://universe.roboflow.com/kmitl-evvyr/weapon-detection-knife/model/1. Для подключения используем следующий код:
from roboflow import Roboflow
rf = Roboflow(api_key="ne2aD5LuLH2xQyAFcVip")
project = rf.workspace().project("weapon-detection-knife")
model = project.version(1).model
print(model.predict(img_path, confidence=40, overlap=30).json())
В результате запуска получили результат, который демонстрирует, что предобученная модель неправильно находит ножи, например, ошибочно принимает за ножи другие предметы. На следующем изображении показан пример ошибочного определения. Вместо ножа определена верхняя часть дома.

Далее протестируем модель RCNN ResNet 50 FPN V2. Мы обучим её на реальном наборе данных и протестируем.
Создадим свой датасет из 55 фотографий и произведем обучение модели.
При создании своего набора фотографий для обучения используем 55 фотографий с ДомКлик, где были обнаружены ножи моделью Yolo8x. Модель RCNN ResNet 50 FPN V2 требует, чтобы датасет был подготовлен в формате Pascal VOC format. В результате получаем каталог с тремя подкаталогами test, train, valid c фотографиями. Test содержит тестовый набор из 5 файлов, 39 файлов из train используется для обучения, 11 файлов из valid для проведения проверки модели.
Выполняем вручную маркировку фотографий. Для этого выделяем область с ножами и указываем к какому классу эта область относится. Используем классы __background__’, ‘knifes-detect’, ‘knifes’, ‘no_knifes’, ‘object’.

Подготавливаем файл YAML для набора данных. Он содержит информацию об изображениях и путях к XML-файлам. Наряду с этим, он также содержит имена классов и количество классов в наборе данных.
Файл knifes-detect.yaml
TRAIN_DIR_IMAGES: 'data/knifes-detect/dataset/train'
TRAIN_DIR_LABELS: 'data/ knifes-detect /dataset/train'
VALID_DIR_IMAGES: 'data/ knifes-detect /dataset/valid'
VALID_DIR_LABELS: 'data/ knifes-detect /dataset/valid'
CLASSES: [
'__background__',
'knifes-detect', 'knifes', 'no_knifes','object'
]
NC: 5
SAVE_VALID_PREDICTION_IMAGES: True
Используем следующий код модели. Torch vision позволяет загрузить предварительно подготовленную модель и настроить ее на другом наборе данных.
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
def create_model(num_classes, pretrained=True, coco_model=False):
model = torchvision.models.detection.fasterrcnn_resnet50_fpn_v2(
weights=torchvision.models.detection.FasterRCNN_ResNet50_FPN_V2_Weights.DEFAULT
)
if coco_model:
return model
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
if __name__ == '__main__':
model = create_model(num_classes=81, pretrained=True, coco_model=True)
print(model)
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.")
Для запуска обучения используем следующую команду:
python train.py --model fasterrcnn_resnet50_fpn_v2 --config data_configs/ppe.yaml --epochs 50 --project-name fasterrcnn_resnet50_fpn_v2_ppe --use-train-aug --no-mosaicНиже приведены выходные данные терминала после окончания последней эпохи.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.203
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.243
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.189
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.018
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.084
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.352
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.256
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.125
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.250
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.450
Получили mAP@0.50:0.95 IoU 35,2%. Но для этого прогона лучший результат оказался после 45-й эпохи, которая составила 37,3 при 0.50:0.95 IoU. Обучающий скрипт сохраняет модель последней эпохи, а также лучшую модель. Мы будем использовать наилучшую модель для вывода.
В результате обучения получили следующие графики:
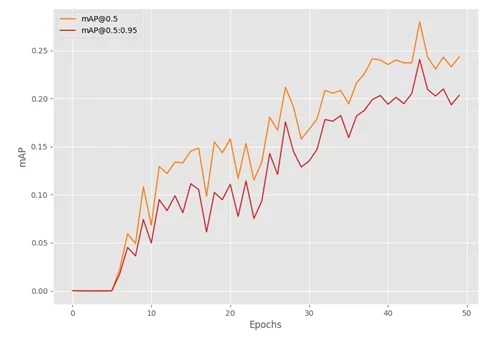
На графике видно, что самое большое значение mAP получено на эпохе 45.
Далее следует график потерь, который снижался до конца обучения.
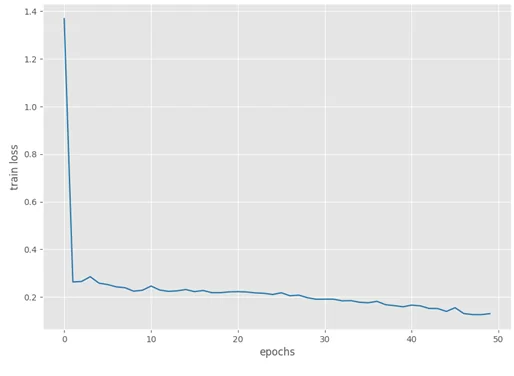
Теперь мы проверим нашу обученную модель на тестовом наборе данных. Для запуска определения объектов используем команду:
python inference.py –weights outputs/training/fasterrcnn_resnet50_fpn_v2_ppe/best_model.pth –input data/dataset/test/1123.jpg –show-image –threshold 0.9
После запуска на нескольких фотографиях получили результат, свидетельствующий о том, что модель не смогла определить ножи на изображениях.
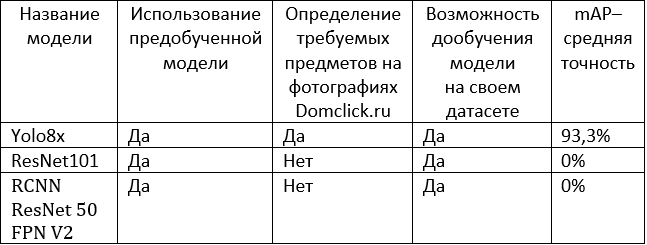
Результаты применения моделей YOLO и Resnet:
В итоге проделанной работы можно сделать следующие выводы.
Задача определения предметов на фотографиях может быть решена путем применения предобученных моделей YOLO8. Данная модель имеет хорошую поддержку в интернете и успешно развивается. В своем составе имеет несколько предобученных моделей. Предобученная модель Yolo8x.pt показала хороший результат в данной задаче.
Предобученные модели Resnet не смогли справиться с задачей определения ножей на фотографиях. Попытка дообучить модели Resnet на своем наборе данных также не увенчалась успехом. Для дообучения модели Resnet требуются датасет для обучения большего размера и вычислительные ресурсы.
Таким образом, в условиях ограниченности временных и вычислительных ресурсов и учитывая более хорошую поддержку YOLO в сети Интернет, можно сделать вывод, что применение предобученной модели YOLO8 является лучшим выбором для решения задачи определения предметов на фотографиях.