/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Наиболее распространённой архитектурой построения телевизионных систем видеонаблюдения (ТСВ) является децентрализованная модель организации серверов ТСВ в точках продаж, на которых осуществляется хранение архива ТСВ.
Для аудита необходима массовая выгрузка скриншотов с каждого сервера ТСВ для формирования Data Set и последующего анализа с применением инструментов СV.
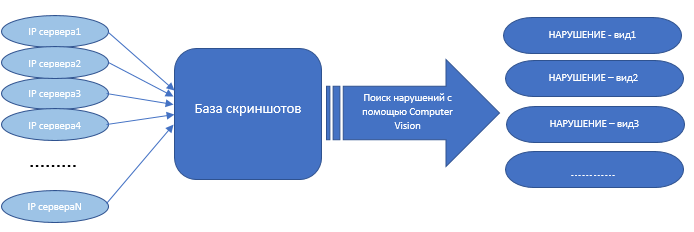
Разберем предлагаемые возможности вендора TRASSIR, которые можно использовать для аудита.
TRASSIR позволяет сохранять скриншоты путем настройки правил на серверах ТСВ
Мастер по созданию правил предназначен для простой настройки правил в системе видеонаблюдения. Он позволяет задать нужную реакцию на то или иное событие в системе за несколько кликов без необходимости глубоко погружения в систему — без скриптов.
Плюсы метода:
- Легко и понятно настраивается;
- Быстрая выгрузка скриншотов по отдельной камере за определенный период времени;
- Не требует компетенций программирования (без скриптов).
Минусы метода:
- Настройка одного правила по одной камере повышает существенно трудозатраты при настройке большого количества серверов ТСВ.
TRASSIR позволяет сохранять скриншоты с помощью скрипта
Вендор предлагает собственный редактор скриптов, состоящий из следующих функциональных областей:
- Область управления скриптом.
- Область редактирования скрипта.
На официальном сайте вендора Trassir (https://www.dssl.ru/files/trassir/manual/ru/setup-rules-examples.html) имеется подборка скриптов, которые могут использоваться для работы, а также данные скрипты хранятся на диске С в установочной папке DSSL/Trassir, поэтому в области редактора скрипта можно загрузить пример скрипта по сбору скриншотов.
Данный скрипт позволяет производить настройку каждого сервера для сохранения скриншотов с определенной периодичностью и отправлять для формирования базы. Данный скрипт работает по правилу:

Это очень удобно, когда производитель системы видеонаблюдения изначально предлагает свой скрипт для решения наших задач.
Но применяя промышленный скрипт для выгрузки скриншотов с более 1000 серверов, мы столкнулись с несколькими недостатками:
— во-первых, настройка правил вручную для каждого сервера занимает очень много времени;
— во-вторых, если список серверов изменяется, то нужно все правила прописывать заново вручную;
— в-третьих, данный скрипт не отрабатывает ошибки, то есть если в момент подключения к серверу он недоступен, скрипт выдает ошибку и к следующему серверу уже не может подключиться.
Анализируя возможности, предлагаемые вендором TRASSIR, мы выяснили, что используемое производителем ПО взаимодействует со скриптами Python.
Для устранения минусов промышленного скрипта мы решили создать свой скрипт и поделиться с Вами этим опытом.
Для данного скрипта мы используем модули из стандартной библиотеки Python:
— requests, os, ast, json, io, time, sys, traceback, shutil.
А также устанавливаем с помощью команды pip дополнительные модули, необходимые для работы с http запросами:
— urllib, urllib3, re, ssl, PIL.Image, pandas as pd.
Импортируем данные модули:
import requests
import urllib, urllib3, re, ssl
import os
import ast, json, io, time
import PIL.Image as Image
import pandas as pd
import sys, traceback, shutil
Входными данными будет excel файл со списоком IP-адресов серверов ТСВ по данным точкам продаж:

Указываем путь к excel файлу, стартовые метки, папку для формирования скриншотов и т.д.
servers = pd.read_excel(r'/home/user/Рабочий стол/скрипты/TSV/server.xlsx')
#стартовая временная метка для подсчета продолжительности выполнения скрипта
start = time.time()
start_int = 28800 # начальная граница интервала 8:00 a.m.
start_time = time.strftime('%H:%M:%S',time.gmtime(start_int))
finish_int = 72000 # конечная граница интервала 8:00 p.m.
datetime.strptime(time.strftime('%H:%M:%S',time.gmtime(finish_int)),'%H:%M:%S')
str(start_time).replace(":","")
#для формирования папки с выгруженными скриншотами за определенное число
start_moment = str(datetime.now().date() - timedelta(days=back_days)).replace("-","") + 'T'
+ 'Test'
catch_time = datetime.strptime(start_time,'%H:%M:%S')
delta_value = 30 # шаг З0 минут
Прописываем функцию получения скриншота: из excel файла получает список каналов, формирует запрос к серверу и к конкретному каналу и непосредственно выгружает скриншот. Так же на этом этапе происходит обработка всех выпадающих ошибок.
Для удобства последующей обработки, предусмотрели создание необходимых директорий: для каждого сервера и для каждого канала, в итоге структура каталога получается следующая: корень – дата, за которую загружали скриншоты, далее – каталоги по каждому серверу, в каждом таком каталоге – папки по каждому каналу, и уже в них – сами скриншоты.
def Get_screenshot(serv_ip, serv_name, chnl_list, catch_time, delta_value, str_dict, session):
start_moment = str(datetime.now().date() - timedelta(days=back_days)).replace("-","") + 'T'
try:
os.mkdir("/home/user/Рабочий стол/скрипты/TSV/" + start_moment + '/' + str(serv_name))
except:
print('Folder has already created!', traceback.format_exc())
for f in json.loads(str_dict)['channels']:
catch_time = datetime.strptime(start_time,'%H:%M:%S')
print('channel s name ', f['name'])
try:
if chnl_list.count(f['name']) > 0:
try:
os.mkdir("/home/user/Рабочий стол/скрипты/TSV/" + start_moment + '/' + str(serv_name) + '/' + f['name'].replace('/','-'))
except:
print('Folder has already created!', traceback.format_exc())
while catch_time <= finish_time:
start_cycle = time.monotonic()
catch_moment = str(datetime.now().date() - timedelta(days=back_days)).replace("-","") + 'T' + str(catch_time.time()).replace(":","")
print('ID канала ',f['guid'],"Имя канала ",f['name'])
rq = "https://" + serv_ip + ":8080/screenshot/" + f['guid'] + "?timestamp=" + catch_moment + "&sid=" + session
print('Запрос скриншота ',rq)
scr = urllib.request.urlopen(rq,context=ssl._create_unverified_context()).read()
img = Image.open(io.BytesIO(scr))
img_path = "/home/user/Рабочий стол/скрипты/TSV/" + start_moment + '/' + str(serv_name) + '/' + f['name'].replace('/','-') + '/' + serv_ip + ' ' + catch_moment + ' ' + f['name'].replace('/','-') + "img.jpeg"
print(img_path)
img.save(img_path)
finish_cycle = time.monotonic()
cycle = round((finish_cycle - start_cycle)/60,2)
with open('/home/user/Рабочий стол/скрипты/TSV/scr_success.txt','a',encoding='utf-8') as outfile:
outfile.write(str(serv_name) + '~' + serv_ip + '~'+ catch_moment + '~scr_success~cycle_time ' + str(cycle))
outfile.write('\n')
outfile.close()
catch_time = catch_time + timedelta(minutes=delta_value)
print(catch_time.time())
except:
print('failure of screenshots downloading')
print(traceback.format_exc())
with open('/home/user/Рабочий стол/скрипты/TSV/scr_failure.txt','a',encoding='utf-8') as outfile:
outfile.write(str(serv_name) + '~' + serv_ip + '~' + catch_moment + '~scr_failure ' + traceback.format_exc())
outfile.write('\n')
outfile.close()
if traceback.format_exc().count('403'):
break
return print('finish')
Здесь прописан собственно алгоритм, по которому действует скрипт, а также создание файлов логов для фиксирования всех полученных исключений.
Основной цикл идет по списку серверов, полученному из excel файла, делает запросы к серверам на получение id сессии и далее запускает функцию Get_screenshot.
def main():
try:
os.mkdir("/home/user/Рабочий стол/скрипты/TSV/" + start_moment)
except:
print('Folder has already created!')
bgn = time.monotonic()
with open('/home/user/Рабочий стол/скрипты/TSV/scr_failure.txt','a',encoding='utf-8') as outfile:
outfile.write('Новая сессия ~' + str(time.ctime()))
outfile.write('\n')
outfile.close()
with open('/home/user/Рабочий стол/скрипты/TSV/scr_success.txt','a',encoding='utf-8') as outfile:
outfile.write('Новая сессия ~' + str(time.ctime()))
outfile.write('\n')
outfile.close()
print('requests ',requests.__version__)
print('urllib3 ',urllib3.__version__)
print('re ',re.__version__)
success = 0
failure = 0
for idx, inf in servers[:].iterrows():
print('порядковый номер',idx)
serv_ip = inf[0]
serv_name = inf[1]
chnl_list = inf[2].split(",")
rqst_ss = 'https://' + serv_ip + ':8080/login?username=uvk&password=uvk'
print('запрос сессии',rqst_ss)
try:
ss = urllib.request.urlopen(rqst_ss,context=ssl._create_unverified_context()).read()
print(ss)
ss = json.loads(ss)
rqst_res = ss['success']
session = ss['sid']
print('результат запроса сессии ',rqst_res)
print('сессия ',session)
if rqst_res == 0:
print(serv_ip,' ', serv_name, 'rqst_ss failure')
else:
rqst_chnl = "https://" + serv_ip + ":8080/channels/?sid=" + session
channels = urllib.request.urlopen(rqst_chnl,context=ssl._create_unverified_context()).read()
channels_str = channels.decode("UTF-8")+"}"
str_dict = channels_str.split(",\n\t\"remote_channels\"")[0]+"}"
print('ip ',serv_ip)
print('Время захвата кадра', catch_time.time())
print('интервал между кадрами, мин ',delta_value)
Get_screenshot(serv_ip,serv_name, chnl_list, catch_time,delta_value,str_dict,session)
success += 1
except:
print(serv_ip,' ', serv_name, ' session failure')
print(traceback.format_exc())
failure += 1
end = time.monotonic()
span = round((end - bgn)/60,2)
with open('/home/user/Рабочий стол/скрипты/TSV/total.txt','a',encoding='utf-8') as outfile:
outfile.write('success: ' + str(success) + '~' + 'failure: ' + str(failure) + '~' + 'total time: ' + str(span))
outfile.write('\n')
outfile.close()
if __name__ == '__main__':
main()
Данный скрипт работает с excel файлом, который содержит список IP-адресов серверов ТСВ, с помощью http запросов получает список каналов, а затем с каждого канала выгружает скриншоты за период с 8 утра до 8 вечера с интервалом в полчаса.
В итоге у нас получился скрипт, который работает бесперебойно, отрабатывает ошибки, а также позволяет оперативно вносить изменения в базе серверов, без изменения самого скрипта.
В результате мы упростили работу по выгрузке скриншотов и оставили время для эффективного поиска нарушений с помощью Computer Vision.