/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Исходные данные
Имея доступ к API камер видеонаблюдения можно запрашивать картинки в реальном времени с желаемой периодичностью. В зонах самообслуживания клиентов нет сидячих\лежачих мест, поэтому было принято информировать дежурного при присутствии более 5 минут в кадре человека с согнутыми коленями. Мы собрали и разметили датасет с АЭ включающий около 1000 изображений. В процессе улучшения моделей датасет был расширен до 12000 изображений.
Алгоритм работы
Первым делом пришла мысль определять «вертикальность» положения человека. Но это оказалось невозможным ввиду искажения изображения камерами и их поворота относительно горизонта. Встречались камеры, повернутые на 90-180 градусов.
Было принято решение опробовать библиотеку PyTorch PoseEstimator. Она позволяет вычислить положения основных суставов человека.
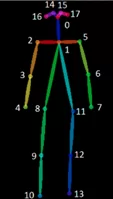
На выходе мы получаем координаты точек и уверенность алгоритма в их определении. Имея координаты трех точек в 2х-мерном пространстве можно вычислить угол между двумя векторами из любой из них:
def CalcDec(points):
p1=points[0]
p2=points[1]
p3=points[2]
def CaclLen(x1,y1,x2,y2):
return sqrt((x1-x2)**2+(y1-y2)**2)
lenP21=CaclLen(p2[0],p2[1],p1[0],p1[1])
lenP23=CaclLen(p2[0],p2[1],p3[0],p3[1])
lenP13=CaclLen(p1[0],p1[1],p3[0],p3[1])
result=acos((lenP21**2+lenP23**2-lenP13**2)/(2*lenP21*lenP23))*57.2958
return result
Я вычислял изгиб в точках 9 и 12 (коленных суставах) и точках 8 и 11. Если угол меньше 120° алгоритм относил человека к АЭ.
К сожалению, библиотека работала медленно и качество распознавания ключевых точек нас не устраивало. Большинство камер искажают картинку, т.к. расположены под потолком и в зимнее время люди плотно одеты. Все это не способствовало правильной работе модели:
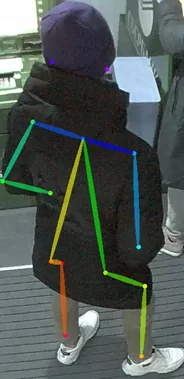

Ключевые точки определены неверно, вычислив углы алгоритм решил, что это сидящий человек.
Увеличить быстродействие удалось подавая на вход PyTorch PoseEstimator не кадр целиком, а обрезанные изображения, переобучить модель не представлялось возможным в виду сложности разметки датасета и отсутсвия желанияJ.
У нас уже был опыт работы с библиотекой Yolo. Она неплохо справляется с задачей object detection. Я взял предобученную сеть, и переобучил ее на своих данных. Yolo гораздо быстрее PoseEstimator и показала неплохой результат в классификации людей. Но, не достаточно хороший – присутствовали ошибки первого и второго рода. Мы несколько раз расширяли обучающую выборку, но значительно улучшить качество помогло только внедрение классификатора RESNET. Он так же, как Yolo был переобучен для разделения изображений на 2 класса – АЭ и другие люди.
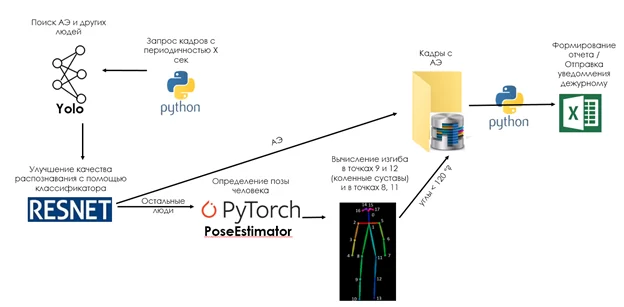
В результате алгоритм выглядит следующим образом:
Исходный код метода predict:
def Predict():
batch=len(frames_queue.queue)
global frames_processed_cnt # Очередь из кадров для обработки
files_list = []
channel_ids_list = []
processedFrames=0
for i in range(batch):
try:
start=datetime.now()
item = frames_queue.get_nowait()
channelName='channel_'+str(item['channel_id'])
# YOLO. находим в кадре положения AЭ и других людей
predictResult,image=yolo_model.predictPath(item['img_path'])
cntHomeless=0
classBoxes=dict()
classBoxes['homeless']=[]
classBoxes['people']=[]
classBoxes['seated']=[]
for predict in predictResult['homeless']+predictResult['people']+predictResult['seated']:
# классификатор RESNET
classifireLabel,classifireConf=homeless_classifire.predict_img(predict.image)
if classifireConf>0.4:
if classifireLabel==0: #people
classBoxes['people'].append(predict)
elif classifireLabel==1: #homeless
classBoxes['homeless'].append(predict)
elif classifireLabel==2: #seated
classBoxes['seated'].append(predict)
fileName=os.path.basename(item['img_path'])
if len(classBoxes['seated'])>0:
imageWithBoxes=Yolo.drawBoxes(image,classBoxes,yolo_model.colors)
SaveResult(imageWithBoxes,item['datetime'],item['server'],channelName,'seated_'+fileName)
if len(classBoxes['homeless'])>0:
imageWithBoxes=Yolo.drawBoxes(image,classBoxes,yolo_model.colors)
SaveResult(imageWithBoxes,item['datetime'],item['server'],channelName,'homeless_'+fileName)
else:
# для каждого класса рисую скелет и проверяю на принадлежность к классу АЭ
for i,people in enumerate(predictResult['people']):
#PoseEstimator
candidate, subset, peopleBodyImage = PredictBody(people.image)
finder=HomelessFinder(candidate,subset)
if finder.CntHomeless()>0:
cntHomeless+=finder.CntHomeless()
SaveResult(peopleBodyImage,item['datetime'],item['server'],channelName,"homeless_pose_"+fileName)
# нарисовать все скелеты на исходном кадре если найден хотябы один АЭ
if cntHomeless>0:
fileName=os.path.basename(item['img_path'])
image = cv2.imread(item['img_path'])
_,_,allBodyImage = PredictBody(image)
SaveResult(allBodyImage,item['datetime'],item['server'],channelName,fileName)
frames_processed_cnt+=1
processedFrames+=1
if cntHomeless>0:
print(datetime.now()-start,"Человек в кадре: ",len(predictResult['people'])," АЭ:",cntHomeless)
except Exception as e:
print('Ошибка: ',e,item)
При нахождении Yolo АЭ – кадр отправляется в отчет. В остальных случаях все изображения найденных людей отправляются на вход обученному классификатору RESNET, который так же относит объект к одному из классов. Если и этот алгоритм не нашел АЭ происходит определение ключевых точек человека с помощью библиотеки PyTorch PoseEstimator. На выходе мы получаем координаты основных суставов и вычисляем углы в ключевых точках. Если углы <120 градусов отправляем кадр в отчет.

Последним этапом происходит анализ отчета, если присутствие АЭ продолжается в течении заданного времени происходит информирование дежурного.
В результате был разработан инструмент на базе 3-х моделей, позволяющий дежурному реагировать на инциденты более оперативно, прикладывая при этом меньше усилий.