/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Python используется для решения огромного количества задач, но у него есть одна большая проблема — скорость. Эта ситуация может измениться благодаря Mojo.
Что за Mojo?
Mojo — новый язык программирования (появился в 2023 году), который, по сути, является надмножеством Python, как TypeScript и JavaScript. Mojo устраняет имеющиеся у Python проблемы производительности и развертывания, а, по заявлениям разработчиков, в некоторых задачах обгоняет Python в 35 тыс. раз!
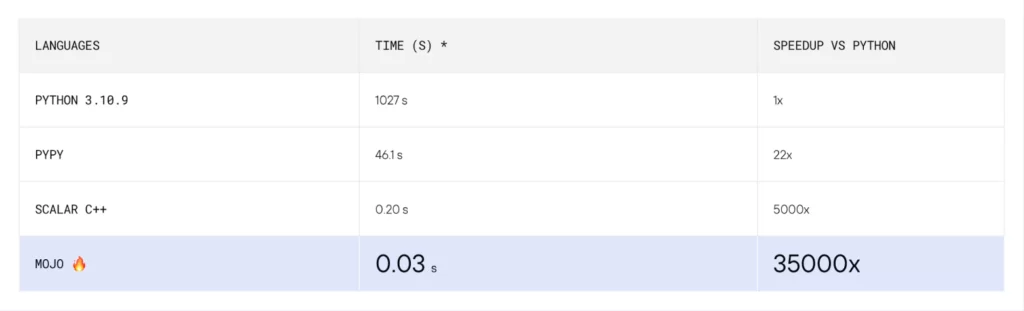
Вдобавок, за Modular, разработчиками Mojo, стоит Крис Латтнер, создатель языка программирования Swift и компилятора LLVM, который облегчил разработку новых мощных языков программирования (Rust, Julia), что заставляет быть ещё более уверенным в успехе Mojo.
Проблемы Python
Python — прекрасный язык, с большим количеством областей применения. Он доминирует в области Data Science, обладает огромным количеством фреймворков, что надежно закрепляет его в инструментарии современного разработчика.
Так почему бы не использовать его при решении всех задач? Просто он в несколько тысяч раз медленнее, чем C‑подобные языки. Это делает непрактичным его использование для чувствительных к производительности частей кода, однако у Python есть одно неоспоримое преимущество: он может обращаться к коду, написанному на быстрых языках, таких, как C, позволяя программистам Python чувствовать себя как в родной среде, даже если они используют высокооптимизированные числовые библиотеки. Но и у такого подхода существуют неизбежные проблемы с производительностью: приходится иметь дело с невозможностью эффективной параллельной обработки в Python, а также с отсутствием слияния, то есть множества скомпилированных функций подряд приводят к накладным расходам.
Как Mojo может решить эти проблемы?
Создать быстрый, а также простой и гибкий в использования язык программирования, который будет лишен проблем Python, сложно, однако Modular, кажется, имеют все шансы на успех.
В первую очередь, Mojo — язык, разработанный для программирования на графических процессорах (GPU), что крайне важно для разработок в области искусственного интеллекта. В качестве «фундамента» Mojo использует гибкую инфраструктуру для современных оптимизирующих компиляторов MLIR, которая позволяет разработчикам Mojo извлечь все преимущества векторов, потоков и аппаратных устройств искусственного интеллекта.

Память управляется аналогично Rust через систему владения с набором правил, которые проверяются компилятором, при нарушении которых программа не будет скомпилирована. Это никак не замедляет скорость работы программы, но повышает безопасность. Также поддерживается ручное управление, как в C++.
Все это делает Mojo эффективным в использовании ресурсов, однако есть ещё одно важное преимущество. Он разработан как надмножество Python, таким образом, не придется изучать другой язык. Mojo полностью совместим и может взаимодействовать с экосистемой Python, что означает поддержку популярных библиотек.

Но это ещё не всё, есть и новый функционал, например, статическая типизация (вы все ещё можете использовать динамические типы, но статические необходимы для оптимизации) и наличие возможности у разработчика в любой момент перейти в более быстрый «режим», используя «fn» вместо «def» для создания своей функции. В этом режиме нужно явно объявить тип каждой переменной, и в результате Mojo сможет создать оптимизированный машинный код для реализации функции. Более того, если используется «struct» вместо «class», атрибуты будут плотно упакованы в память, поэтому их можно будет использовать даже в структурах данных, не гоняясь за указателями. Именно этот функционал позволяет языкам C быть настолько быстрыми, а теперь он доступен и для разработчиков на Python, нужно просто изучить немного нового синтаксиса.
Тесты и сравнения
Начнем с простого, вычислим сумму арифметической прогрессии, используя цикл for.
Вот так будет выглядеть наш код на Python:
%%python
from time import time
start_time = time()
sum = 0
for i in range(10_000_000_001):
sum += i
end_time = time()
python_execution_time = (end_time - start_time) * 1_000_000_000Получим следующее:
- sum = 500000000500000000
- python_execution_time = 73 357 328 653.33557 nanoseconds
А так на Mojo:
from Time import now
start_time = now()
var sum: Int = 0
for i in range(10_000_000_001):
sum += i
end_time = now()
mojo_execution_time = end_time - start_timeРезультаты:
- sum = 500000000500000000
- mojo_execution_time = 82 nanoseconds
По итогам тестирования можем установить, что Mojo считает сумму арифметической прогрессии от 0 до 1 000 000 000 быстрее Python почти в 1 000 000 000 раз! При этом, чем больше элементов, тем больше разница между соревнующимися. Естественно, эта задача мало похожа на реальную, но она показывает, насколько быстро Mojo может работать с циклами.
Теперь попробуем что‑нибудь сложнее, например, вычисление числа π.
Python:
%%python
from time import time
def pi(n) -> float:
total = 0.0
for i in range(1 - 2*n, 2*n + 1, 4):
total += 1.0 / i
return 4 * total
start_time = time()
print(pi(10_000_000_000))
end_time = time()
python_execution_time = (end_time - start_time) * 1_000_000_000Получаем:
- pi = 3.1415926534900813
- python_execution_time = 73357328653.33557 nanoseconds
Mojo:
from Time import now
fn pi(n: Int) -> FloatLiteral:
var total: FloatLiteral = 0.0
for i in range(1 - 2*n, 2*n + 1, 4):
total += 1.0 / i
return 4 * total
start_time = now()
print(pi(10_000_000_000))
end_time = now()
mojo_execution_time = end_time - start_timeРезультат:
- pi = 3.1415926534900813
- mojo_execution_time = 11596816608 nanoseconds
В этот раз разница не такая существенная, но все также ощутима, Python медленнее в 500 раз.
Ну и наконец, умножение матриц, одна из операций, на основе которой Modular демонстрируют преимущества своей разработки.
Сначала реализуем алгоритм умножения матриц на Python исходя из определения.
%%python
def matmul_python(C, A, B):
for m in range(C.rows):
for k in range(A.cols):
for n in range(C.cols):
C[m, n] += A[m, k] * B[k, n]Протестируем нашу реализацию используя квадратные матрицы 128×128 и вычислим скорость в гигафлопсах.
%%python
import numpy as np
from timeit import timeit
class Matrix:
def __init__(self, value, rows, cols):
self.value = value
self.rows = rows
self.cols = cols
def __getitem__(self, idxs):
return self.value[idxs[0]][idxs[1]]
def __setitem__(self, idxs, value):
self.value[idxs[0]][idxs[1]] = value
def benchmark_matmul_python(M, N, K):
A = Matrix(list(np.random.rand(M, K)), M, K)
B = Matrix(list(np.random.rand(K, N)), K, N)
C = Matrix(list(np.zeros((M, N))), M, N)
secs = timeit(lambda: matmul_python(C, A, B), number=2) / 2
gflops = ((2 * M * N * K) / secs) / 1e9
print(gflops, "GFLOP/s")
return gflops
python_gflops = benchmark_matmul_python(128, 128, 128).to_float64()Итог: python_gflops = 0.0016717199881536883 GFLOP/s
Теперь реализуем на Mojo.
from Benchmark import Benchmark
from DType import DType
from Intrinsics import strided_load
from List import VariadicList
from Math import div_ceil, min
from Memory import memset_zero
from Object import object, Attr
from Pointer import DTypePointer
from Random import rand, random_float64
struct Matrix:
var data: DTypePointer[DType.float32]
var rows: Int
var cols: Int
fn __init__(inout self, rows: Int, cols: Int):
self.data = DTypePointer[DType.float32].alloc(rows * cols)
rand(self.data, rows*cols)
self.rows = rows
self.cols = cols
fn __del__(owned self):
self.data.free()
fn zero(inout self):
memset_zero(self.data, self.rows * self.cols)
@always_inline
fn __getitem__(self, y: Int, x: Int) -> Float32:
return self.load[1](y, x)
@always_inline
fn load[nelts:Int](self, y: Int, x: Int) -> SIMD[DType.float32, nelts]:
return self.data.simd_load[nelts](y * self.cols + x)
@always_inline
fn __setitem__(self, y: Int, x: Int, val: Float32):
return self.store[1](y, x, val)
@always_inline
fn store[nelts:Int](self, y: Int, x: Int, val: SIMD[DType.float32, nelts]):
self.data.simd_store[nelts](y * self.cols + x, val)Функция умножения матриц:
fn matmul_naive(C: Matrix, A: Matrix, B: Matrix):
for m in range(C.rows):
for k in range(A.cols):
for n in range(C.cols):
C[m, n] += A[m, k] * B[k, n]Алгоритм бенчмарка:
@always_inline
def benchmark[func : fn(Matrix, Matrix, Matrix) -> None]
(M : Int, N : Int, K : Int, python_gflops: Float64):
var C = Matrix(M, N)
C.zero()
var A = Matrix(M, K)
var B = Matrix(K, N)
@always_inline
@parameter
fn test_fn():
_ = func(C, A, B)
let secs = Float64(Benchmark().run[test_fn]()) / 1_000_000_000
_ = A.data
_ = B.data
_ = C.data
let gflops = ((2*M*N*K)/secs) / 1e9
let speedup : Float64 = gflops / python_gflops
print(gflops, "GFLOP/s, в", speedup.value, "раз быстрее Python")
benchmark[matmul_naive](128, 128, 128, python_gflops)Результат: 13.978696 GFLOP/s, в 8361.864443 раз быстрее Python
Наблюдаем ускорение более чем в 8 000 раз в таком непростом алгоритме.
Однако, если использовать torch:
import numpy as np
from timeit import timeit
import torch
def benchmark_torch_matmul_python(M, N, K):
A = torch.randn(M, N)
B = torch.randn(N, M)
secs = timeit(lambda: torch.matmul(A, B), number=2) / 2
gflops = ((2 * M * N * K) / secs) / 1e9
print(gflops, "GFLOP/s")
return gflops
python_gflops = benchmark_torch_matmul_python(128, 128, 128).to_float64()Результат: python_gflops = 19.74407991241765 GFLOP/s
Здесь Mojo оказался медленнее в 1.41244 раза. К сожалению, использовать torch с Mojo для дополнительных тестов пока нет возможности.
Заметим, что все тесты проводились на CPU.
Заключение
Протестировав Mojo и сравнив его с Python, можно сделать как минимум один вывод — Python без использования сторонних библиотек медленнее, причем заметно.
Конечно, новые языки и фреймворки появляются постоянно и не все из них становятся востребованными и популярными, да и Mojo ещё находится в очень раннем развитии, но, кажется у него есть все шансы стать востребованным у современных разработчиков.