/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Проблема дисбаланса классов может привести при классификации к недообучению модели, а не верно выбранная метрика для оценки качества работы алгоритма к ложному восприятию качества построенной модели. Чтобы избежать этих ошибок нужно понимать logic behind, с которой подробно разберемся в статье.
Что такое дисбаланс:
Важно также заметить, что разница в количестве представленных наблюдений по классам – это не разреженность признаков. Ситуация, в которой у доминирующей части наблюдений отсутствует класс, а остальные наблюдения в приблизительно равных пропорциях представлены в выборке дисбалансом не является.
Дисбалансом также принято считать существенную разницу в количественном представлении классов в выборке.
Разница в 10-20% не будет считаться дисбалансом, тем не менее итоговой «отсечки», по которой выборку можно назвать несбалансированной нет, это всегда эвристика, которая зависит от конкретной задачи.
Есть и обратная ситуация, когда минорный класс настолько мало представлен в выборке, например, 1/10.000, что задача из классификации несбалансированной выборки должна перейти в разряд детектирования аномальных наблюдений, которая решается уже другими методами.
Природа дисбаланса:
Это самый первый вопрос, который необходимо выяснить после установления факта наличия дисбаланса в выборке наблюдений.
Распространенное явление, почему появился дисбаланс классов – это наличие дубликатов в выборке. Логичным действием в такой ситуации является удаление повторяющихся наблюдений.
Дисбаланс может встретиться в многоклассовой задаче из-за исторических особенностей выборки, например, это популяция какого-то редкого вида.
Дисбаланс классов может возникать в случае, если не проведена стратификация при делении тренировочной и тестовой выборках, стратификацию по классам – зависимой переменной, можно установить при помощи параметров библиотеки sklearn.train_test_split, тогда выборка сохранит одинаковый «баланс» или «дисбаланс» в обеих частях выборки.
Функционал ошибки и метрика оценки качества
Если в задаче иcпользуется функция потерь logloss, то не естественное сокращение дисбаланса классов приведет к тому, что алгоритм станет неоткалиброванным.
Также если в задаче используется метрика ROC-AUC, то дисбаланс классов нет необходимости выравнивать, потому что метрика не чувствительна к смещению.
Семплирование
Существует два базовых метода, связанных с семплированием: oversampling и undersampling. В первом случае искусственно расширяется минорный класс, используя, например, технику bootstrapping, а во втором случае рандомно обрезается мажорный класс – из него случайным образом отбирается выборка соизмеримая по размеру с минорным классом.
Давайте, сгенерируем искусственную выборку, на которой, сможем посмотреть применимость методов.
# импорт необходимых библиотек
from collections import Counter
from sklearn.datasets import make_classification
from matplotlib import pyplot
from numpy import where
# создаем искусственный датасет из 2 признаков и 1000 наблюдений.
# для воспроизводимости результатов необходимо зафиксировать random_state
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
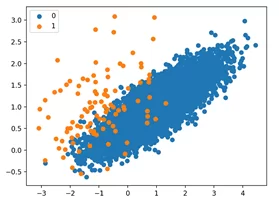
Визуализируем датасет, чтобы убедиться в том, что получилось сгенерировать дисбаланс.
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
Существуют также методы, так называемого «умного недосемплирования».
Стратегия Nearmiss – 1:
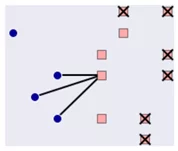
Из мажоритарного класса выбираются объекты, у которых среднее расстояние минимально до N ближайших наблюдений минорного класса.
Для работы с несбалансированной выборкой можно использовать библиотеку imblearn
# параметр version отвечает за тип семплирования
undersample = NearMiss(version=1)
# генерируем новую выборку
X, y = undersample.fit_resample(X, y)
# построим новый график
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
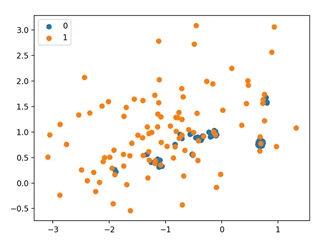
Как видно из диаграммы, в облаке наблюдений остались только те точки мажорного, которые ближе всего находились к представителям минорного.
Стратегия Nearmiss – 2:
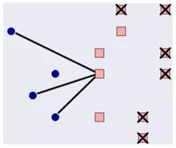
Из мажоритарного класса выбираются объекты, у которых среднее расстояние минимально до N самых дальних наблюдений минорного класса.
Аналогичным образом воспроизведем использование метода при помощи кода:
# указываем версию семплирования и кол-во соседей
undersample = NearMiss(version=2, n_neighbors=3)
# проводим андерсемплинг
X, y = undersample.fit_resample(X, y)
# строим график
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
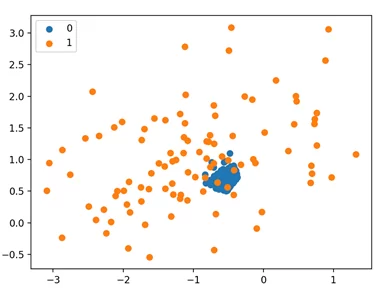
Исполнив пример, мы видим, что Nearmiss-2 выбирает наблюдения, которые находятся в центре масс для перекрытия между двумя классами.
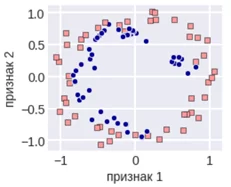
SMOTE: Synthetic Minority Oversampling Techniques и ADASYN: Adaptive Synthetic
В методе SMOTE выбирается одно из наблюдений минорного класса, для него идет поиск k ближайших соседей из того же минорного класса, так формируются «выпуклые пары» объектов. На отрезках между наблюдениями «соседями» выбирается случайный объект, который искусственно расширяет выборку.
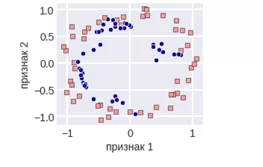
SMOTE
Рассмотрим имплементацию метода SMOTE:
# заменяем тип трансформации
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)
# строим аналогичный график для результатов
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
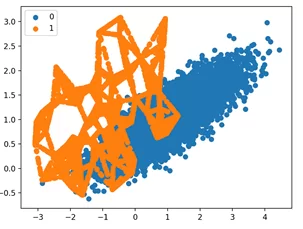
Метод ADASYN имеет схожу логику, но количество искусственно добавленных объектов минорного класса пропорционально количеству объектов доминирующего класса в окрестности наблюдения.
ADASYN
Рассмотрим пример работы ADASYN – адаптивного синтетического семплирования на примере:
# изменяем метод семплирования
oversample = ADASYN()
X, y = oversample.fit_resample(X, y)
# визуализируем результаты
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
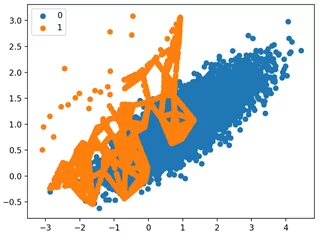
Из примера видим, что наблюдения разных классов, расположенные близко, друг к другу получают наибольший фокус. Остальные наблюдения, расположенные относительно далеко могут быть восприняты, как выбросы. ADASYN уделяет слишком много внимания этим областям пространства функций, и это может привести к снижению производительности модели.
Взвешивание объектов: Во многих алгоритмах, реализованных в sklearn, а также в CatBoost есть возможность уравнять дисбаланс классов, используя веса, присваиваемые наблюдениям. Так, обычно наблюдениям доминирующего класса (с меткой 0) равными 1, а наблюдениям минорного класса присваивают веса 1 — m_40⁄m_1, где m_0,m_1 – это количество наблюдений по классам 0 и 1 соответственно. При оценке такого алгоритма с уравниванием по весам стоит использовать метрику оценки – AUC-ROC, так как она строится в относительных координатах – TRP, FPR.
Присваивание весов можно сделать не вручную, а автоматически, использовав параметр class_weight=’balanced’.
Итог: имея в виду список «маяков», на которые стоит обращать внимание при работе с несбалансированной выборкой, Вы с большой вероятностью избежите большого числа логических ошибок, которые можно допустить, если решать задачу «в лоб».