03.03.2022, Милованов Максим, г. Новосибирск Подбор параметров для построения модели для различных видов переменных
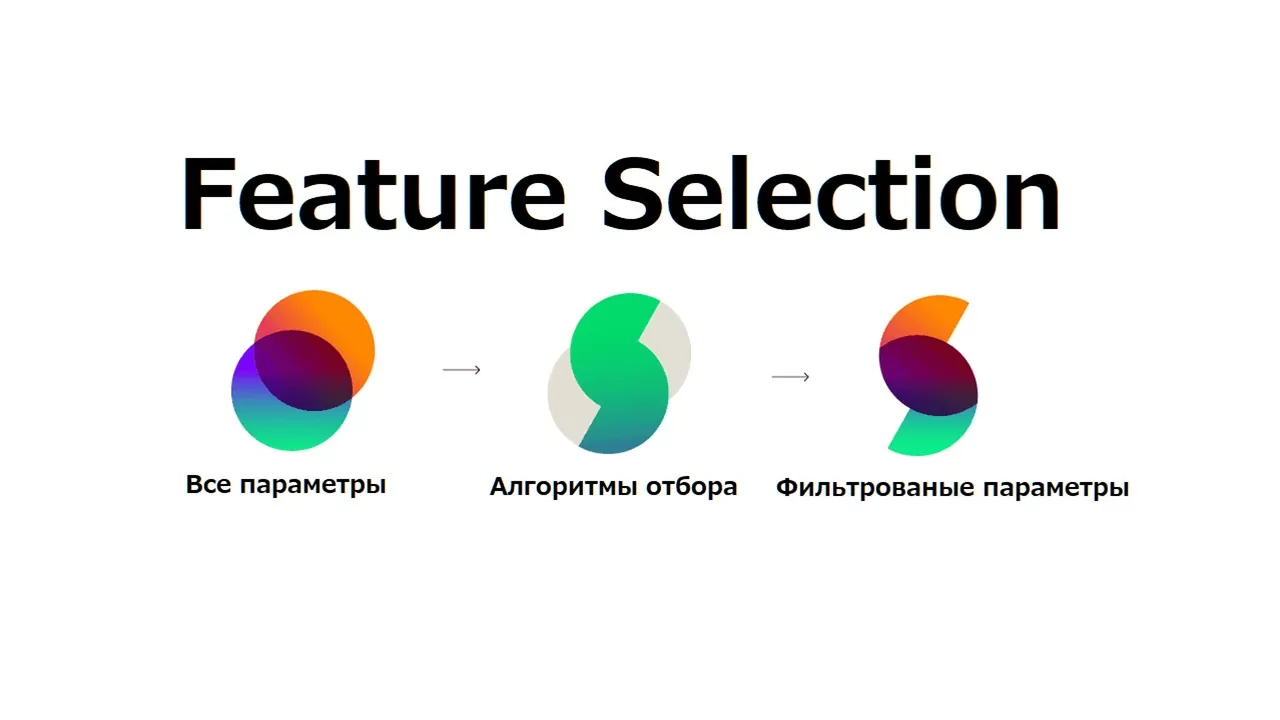
При построении моделей, не зависимо от используемого метода, выбор используемых при построении признаков оказывает значительное влияние на результат. Правильный подбор и фильтрация позволяют не только ускорить обработку данных, но и вероятно улучшить качество модели в целом. Именно поэтому правильный алгоритм определения значимых признаков играет большую роль, что и будет рассмотрено в данной статье.
/img/star (2).png.webp)
/img/news (2).png.webp)












/img/event.png.webp)