/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Задача была такая: набор признаков должен обеспечить максимальную информативность. Это значит, что отбираются признаки, способные объяснить наибольшую долю дисперсии исходного набора.
Факторный анализ – многомерный метод, который применяется для изучения связей между переменными, когда существует предположение об избыточности исходных данных. Вращение Varimax в ходе факторного анализа способствует нахождению наилучшего подпространства признаков.
Метод главных компонент – метод статистического анализа, позволяющих снизить размерность пространства признаков и потерять при этом минимальное количество информации. Достигается это за счёт построения подпространства признаков меньшей размерности таким образом, чтобы дисперсия, распределённая по получаемым осям, была максимальна.
Первым этапом будет генерация исходных данных: DataFrame, большее количество столбцов которого будут заполнены случайными числами с заданной амплитудой, и лишь некоторые признаки (назову их существенными), которые будут выступать переменными, используемыми в модели. Я рассмотрю представленные выше методы на примере снижения размерности полученного набора данных.
Импорты (main):
import string
import numpy as np
import pandas as pd
Функции, используемые для генерации (main):
def genData(col, row, feature, path):
# случайные имена шумных столбцов
columns=[string.ascii_lowercase[np.random.randint(len(string.ascii_lowercase))]+str(i) for i in range(col)]
# случайные имена столбцов с признаками
feat=[string.ascii_lowercase[np.random.randint(len(string.ascii_lowercase))]+str(i) for i in range(feature)]
df = pd.DataFrame()
# заполнение столбцов данными
for i in range(row):
noise = pd.DataFrame([[np.random.random() / 10 for _ in range(col)]], columns=columns)
features = pd.DataFrame([[np.random.uniform() + np.random.random() / 10 for _ in range(feature)]], columns=feat)
df2 = pd.concat([noise, features], axis=1)
df = pd.concat([df, df2], ignore_index=True)
# сохранение результата
df.to_csv(path, index=False)
# возврат набора данных и имён столбцов существенных признаков
return df, feat
def genResult(path, respath, features):
# чтение сгенерированного набора
data = pd.read_csv(path)
# вычисление класса, к которому относится каждый вектор набора
data["res"] = (data[features].sum(axis=1)).round().astype("int")
# сохраним результат
data["res"].to_csv(respath, index=False)
# возврат столбца с полученными классами
return data["res"]
Импорты:
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from main import genData, genResult
Генерация данных:
warnings.filterwarnings("ignore")
# пути для сохранения файлов
dataPath = "./data.csv"
resPath = "./res.csv"
# количество существенных признаков
numFeatures = 4
# размер генерируемых данных
col = 10000
row = 1000
data, features = genData(col, row, numFeatures, dataPath)
result = genResult(dataPath, resPath, features)
Вывожу информацию о полученном наборе.
print(data.info())
Смотрю на полученные классы:
print(result.head())
Список существенных признаков:
print(features)
Получаю матрицу факторных нагрузок:
X = data
Y = result
n_components = 4
# создание экземпляра класса метода главных компонент
pca = PCA(n_components=n_components)
featureNames = X.columns
# вычисление матрицы факторных нагрузок
fitted = pca.fit(X=X, y=Y)
Далее выбираю существенные признаки:
# выбор существенных признаков
df = pd.DataFrame()
# подготовка матрицы для отбора существенных признаков
components = np.abs(fitted.components_.T)
for c in range(len(components)):
df[featureNames[c]] = components[c]
# отбор существенных признаков
trustedFeatures = []
for i in range(n_components):
trustedFeatures.append(df.apply(max, axis=0).idxmax())
df = df.drop(df.apply(max, axis=0).idxmax(), axis=1)
print(trustedFeatures)

Проверяю, совпадают ли полученные признаки с исходными существенными признаками (совпадают):
features.sort() == trustedFeatures.sort()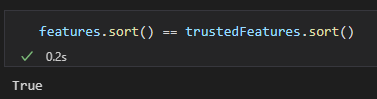
Затем я подготовил и обучил модели:
# создание моделей
clf1 = RandomForestClassifier(max_depth=2, random_state=0)
clf2 = RandomForestClassifier(max_depth=2, random_state=0)
# обучение моделей
clf_all = clf1.fit(X, Y.values.ravel())
clf_resampled = clf2.fit(X[trustedFeatures], Y.values.ravel())
print("Точность модели на полной обучающей выборке = ", clf_all.score(X, Y))
print("Точность модели на отобраных признаках = ", clf_resampled.score(X[trustedFeatures], Y))

Рассмотрев результаты обучения, можно заметить, что точность модели при обучении на отобранных признаках с помощью методов факторного анализа и главных компонент выросла на 0.14. Это произошло благодаря тому, что в результате отбора признаков снизилось количество «шумных» переменных модели, а переменную, объясняемую 10004 признаками, удалось объяснить с помощью 4.
Рассмотренный пример показывает целесообразность использования возможности снижения количества переменных модели за счёт отбора существенных признаков. Стоит учесть, что метод снижения размерности нужно подбирать, исходя из природы данных.