/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Adversarial Validation часто используется в соревнованиях на Kaggle. Идея данной техники достаточно проста и интуитивно понятна. Необходимо классифицировать каждое наблюдение к обучающему или тестовому набору данных. Если переменные в обучающем и тестовом наборе данных подчиняются одному закону распределения, то модель классификации даст плохое качество предсказания. Однако если в датасетах будет наблюдаться какое-либо систематическое различие в переменных, тогда классификатор сможет качественно определить, какое наблюдение относится к обучающему набору данных, а какое к тестовому. Иными словами, классификатор распознает обучающий и тестовый датасет, если какая-либо из переменных подчиняется разным законам распределения в этих двух датасетах. И чем лучше по качеству будет классификатор, тем хуже обстоит ситуация для решения основной целевой задачи, для которой были созданы обучающий и тестовый наборы данных. Данная техника помогает выявить проблему переобучения на этапе предварительного анализа данных и может использоваться для любых типов задач: регрессия, классификация, нейронные сети.
Между тренировочной и тестовой выборкой могут быть большие различия, и важно выяснить, насколько различия сильны, так как это может сыграть решающую роль для реализации целевой модели. Adversarial Validation нужно для того, чтобы выявить это различие в переменных.
Для реализации данной техники будет использоваться набор данных: прогнозирование спроса для магазина. Данные представлены за 145 недель по таким характеристикам как: категория продукта, подкатегория, текущая цена, скидка на продукт, город расположения и т.д.
Выполним импорт библиотек:
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, roc_auc_score
Далее загружаются тренировочный и тестовый наборы данных. В Adversarial Validation стоит задача узнать, какая строка относится к тренировочному датасету, а какая к тестовому. Поэтому необходимо создать новую целевую переменную, где 1 отмечены наблюдения из тренировочной выборки, а 0 из тестовой. Это будет целевая переменная, которую классификатор будет статься предсказать.
train['train'] = 1
test['train'] = 0
Теперь перемешаем новые данные и получим единый новый датасет. Этот набор будет использоваться для Adversarial Validation.
df = pd.concat([train, test]).reset_index(drop=True)Для моделирования использовался Catboost классификатор. Инициализуем его.
model_catboost = CatBoostClassifier(
learning_rate=0.9,
random_state=1328,
thread_count=-1,
iterations=200,
cat_features=["city_code", "region_code", "center_type", "category", "cuisine"],
verbose=25,
eval_metric="AUC",
od_type="Iter",
od_wait=50)
Поделим набор на тренировочный для обучения модели и тестовый для проверки качества.
X_train, X_test, y_train, y_test = train_test_split(df.drop(['id', 'train'], axis=1), df['train'], test_size=0.25, random_state=12)Применим модель для тренировочный данных
model_catboost.fit(X_train, y_train)Посмотрим на значимость фичей для CatBoost
fi = pd.DataFrame()
fi['importance'] = model_cbs.feature_importances_
fi['feature_name'] = model_cbs.feature_names_
Самым большой значимостью обладала фича «grade», достигая значения 26.29 на фоне значимости других фичей в районе 1-5. Посмотрим, какая вышла метрика AUC и график ROC-AUC.
prediction = model_catboost.predict_proba(X_test)[:,1]
print('roc_auc_score for CatBoostClassifier: ',roc_auc_score(y_test, prediction))
roc_auc_score for CatBoostClassifier: 0.9798
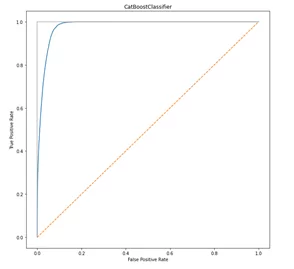
Метрика AUC достигает 0,9798, что говорит о качестве классификатора, и он может с легкостью определить относится наблюдение к тренировочному или тестовому набору данных. Это значит, что фича «grade» имеет разные законы распределения в обучающем и тестовом наборе данных, что может привести к переобучению целевой модели предсказания спроса. Необходимо к ней применить дополнительные итерации или вовсе исключить из анализа.
Очень ярким примером (не относящимся к этому набору данных) является переменная, отвечающая за временной промежуток. Ситуация, когда тренировочный и тестовый набор данных были получены из разных временных промежутков, например, тестовый набор данных собирался позже тренировочного. И классификатор распознал, если дата больше, то наблюдение относится к тестовому набору данных. Также если собирать данные в разные временные промежутки, меняются распределения и других фичей, что также может привести к плохому качеству целевой модели.
Попробуем убрать фичу “grade” из общего набора данных и снова обучить классификатор CatBoost. Посмотрим снова на метрику AUC и график ROC-AUC.
roc_auc_score for CatBoostClassifier: 0.8889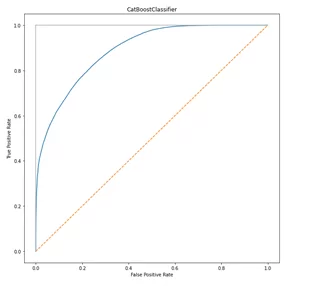
Рис. 2 ROC-AUC после удаления фичи
Таким образом, убрав фичу, метрика AUC стала намного меньше, а значит ситуация для целевой модели по предсказанию спроса улучшилась.
Однако Adversarial Validation не может дать информацию о том, как устранить проблему. Данный подход может только выявить ее. Для решения проблемы необходимо применять креатив, причем так, чтобы был минимальный ущерб для целевой модели. Идея метода заключается в том, чтобы удалить информацию неважную для итоговой целевой модели, но важную для разделения тренировочного и тестового наборов.