/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Для начала загрузим датасет:
from sklearn import datasets
data = datasets.load_diabetes(as_frame=True)
dataset = data.frame

Создать тестовый набор очень просто, нужно произвольно выбрать 20% образцов и отложить их:
import numpy
def split_test_train (dataset, test_size):
shuffled_indx = numpy.random.permutation(len(dataset))
test_set_size = int(len(dataset) * test_size)
train_indx = shuffled_indx[test_set_size:]
test_indx = shuffled_indx[:test_set_size]
return dataset.iloc[test_indx], dataset.iloc[train_indx]
Теперь для того чтобы разделить набор данных, требуется вызвать функцию split_test_train():
test_set, train_set = split_test_train(dataset, 0.2)Все работает, но еще далеко от совершенства. При каждом запуске программы будут получаться разные тестовые наборы. Чтобы этого избежать можно сохранить тестовый набор и использовать его при последующих запусках или установить начальное значение генератора случайных чисел:
import numpy
def split_test_train (dataset, test_size):
numpy.random.seed(42)
shuffled_indx = numpy.random.permutation(len(dataset))
test_set_size = int(len(dataset) * test_size)
train_indx = shuffled_indx[test_set_size:]
test_indx = shuffled_indx[:test_set_size]
return dataset.iloc[test_indx], dataset.iloc[train_indx]
Данный метод имеет реализацию в модуле Scikit-Learn — функция train_test_split(). Функция train_test_split() имеет дополнительную особенность, в нее можно передавать несколько наборов данных с одинаковым количеством строк и она разобьет их по тем же самым индексам. Это удобно при наличии отдельного набора для меток. Пример использования train_test_split():
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(dataset, test_size=0.2, random_state=42)
До этого момента мы рассматривали случайные методы выборки. Они неплохи для больших наборов данных, однако если это не так, испытательный набор может оказаться смещенным, что приведет к неверной оценке работы модели. Чтобы этого не допустить используются стратифицированные выборки.
Выборка делится на однородные подгруппы (страты) и из каждой страты выбирается правильное количество образцов для обеспечения репрезентативности испытательного набора. В Scikit-Learn представлен класс StratifiedShuffleSplit.
Например, разделим dataset на train и test выборки, сохранив баланс возрастных страт. Сперва создадим столбец «age_cat», содержащий 5 возрастных страт:
dataset["age_cat"] = numpy.around(dataset["age"]/5, 2)
dataset["age_cat"].hist()
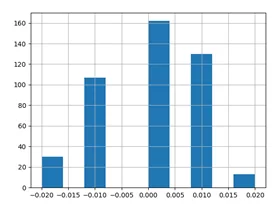
Теперь разделим датасет с использованием столбца «age_cat»:
from sklearn.model_selection import StratifiedShuffleSplit
shuffle_split = StratifiedShuffleSplit(n_splits=1, test_size=0.2,random_state=42)
for train_indx, test_indx in shuffle_split.split(dataset, dataset["age_cat"]):
train_set = dataset.loc[train_indx]
test_set = dataset.loc[test_indx]
Проверим, работает ли код ожидаемым образом. Для этого рассчитаем пропорции страт в каждом наборе данных и сравним процент ошибок.
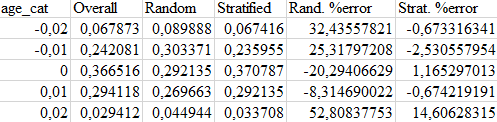
Здесь видно, что испытательный набор, сгенерированный с использованием стратифицированной выборки имеет пропорции страт близкие к пропорциям в полном наборе данных. Чего нельзя сказать о выборке полученной случайным методом.
И последний совет: после того как разделите набор данных на тестовый и обучающий, отложите тестовый и не заглядывайте в него! Иначе ваш мозг обнаружит паттерны в наборе, и исходя из них вы подберете определенный тип модели МО. В итоге вы получите более оптимистичную оценку качества вашей модели, и на реальных данных она будет работать не настолько хорошо, как вы ожидали.