/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
При моделировании какого-либо процесса с помощью ML (machine learning), одной из наиболее трудоемких и ответственных задач является создание массива данных, достаточного по объему для создания модели с высокими качественными характеристиками. Что делать, если данных недостаточно?
В рамках одной из задач по созданию математической модели, оценивающей вероятность манипулирования финансовой отчетностью, предоставляемой клиентом в банк, была зафиксирована проблема недостаточности данных для обучения модели с учителем. В качестве объекта массива была выбрана квартальная финансовая отчетность (ФО). Массив состоял из нескольких тысяч объектов, и для нашей задачи этого было достаточно. Проблема появилась при формировании значений целевой переменной. Аналитиками было выявлено всего лишь 20 доказанных случаев манипулирования финансовой отчетностью. Это крайне малое количество для массива, состоящего из нескольких тысяч объектов. При случайной разбивке массива, в нашем случае на 5 фолдов, при применении функции кросс-валидации, высока вероятность того, что какой-либо из фолдов окажется без объектов с доказанными случаями манипулирования ФО. В данном случае функционал кросс-валидации будет бесполезен и процесс по обучению модели будет завершаться ошибкой.
На первый взгляд, есть решение данной проблемы, которое заключается в применении метода «indersampling», суть которого заключается в дублировании в массиве тех объектов, для которых в нашем случае доказаны факты манипулирования ФО. Как оказалось, применение метода «indersampling» решило проблему кросс-валидации, но создать модель с приемлемыми метриками качества не получилось. Был сделан вывод о том, что применение метод «indersampling» не целесообразно в случае, когда количество объектов миноритарного класса и мажоритарного класса отличаются на несколько порядков. В нашем случае метод дублирования создает большое количество объектов в массиве, которые являются полными копиями своего родителя. В этом случае массив теряет свою уникальность, и обучение на такой выборке приводит к переобучению модели. Очевидность данного факта демонстрируют метрики качества модели на тестовой выборке.
Графики значений метрики ROC_AUC на тестовой и обучающей выборках в зависимости от количества объектов в выборке:
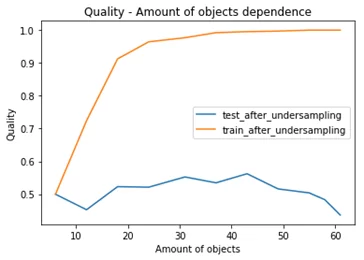
Максимальное значение метрики ROC_AUC, полученное на тестовой выборке приближается к 0,55 и для нашего случая результат не удовлетворительный. Так же при увеличении объектов выборке значение метрики ROC_AUC ухудшается, данный факт указывает на то, модель не пригодна для эксплуатации.
В результате проделанной работы было принято решение о создании метода поиска объектов похожих на миноритарные объекты в массиве по своим параметрам и перевода данных объектов в класс миноритарных. Описание метода предлагается в усеченном варианте, та как метод реализован под массив, который участвовал в создании модели. К примеру, одним из признаков манипулирования ФО является разнонаправленная динамика показателей «Выручка» и «Дебиторская задолженность». На основании экспертного мнения аналитиков, разнонаправленная динамика, превышающая 20% указывает на предпосылки манипулирования ФО. При проверке выборки на данное условие, было выявлено около 25% отклонений такого характера в массиве ФО, следовательно, такие отклонения носят довольно массовый характер и такие объекты не следует переносить в миноритарный класс на основании таких отклонений. Необходимо было провести анализ отклонения в историческом периоде на протяжении двух лет. Для достижения этой цели ФО, как объекты были сгруппированы по принадлежности клиентам. У каждого клиента в выборке имелось 8 ФО – соответствует количеству кварталов в периоде равном двум годам. С помощью процедуры T/SQL с применением функции:
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY “PARAMETER”) OVER (PARTITION BY “CLIENT”)вычислялась медиана параметра в группе из 8 ФО, затем в каждой из 8 ФО рассчитывалось отклонение параметра от медианы параметра в процентном отношении.
В итоге вычислялась разность отклонений от медианы выручки и дебиторской задолженности(ДЗ):
Отклонение от медианы выручка = (Выручка – Выручка_Me/Выручка_Me) *100;
Отклонение от медианы ДЗ = (ДЗ – ДЗ _Me/ ДЗ_Me) *100;
Новый параметр = |Отклонение от медианы выручка — Отклонение от медианы ДЗ|;
Корреляция нового параметра с объектами из миноритарного класса составила 90% и, следовательно, новый параметр можно использовать для вычисления объектов из мажоритарного класса в выборке похожих на объекты из миноритарного класса. С помощью разработанного метода количество объектов в миноритарном классе увеличилось с 20 до 330. После корректировки целевой переменной, создали новую модель.
Графики значений метрики ROC_AUC на тестовой и обучающей выборках в зависимости от количества объектов в выборке после корректировки целевой переменной:
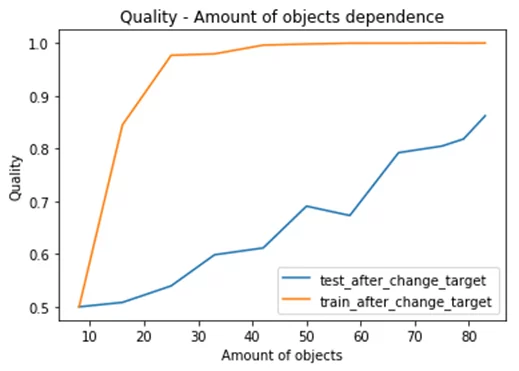
Максимальное значение метрики ROC_AUC, полученное на тестовой выборке приближается к 0,84 и для нашего случая результат удовлетворительный. Так же при увеличении объектов выборки значение метрики ROC_AUC растет, данный факт указывает на то, модель дает адекватную оценку большинству объектов выборке.
Для достижения определенного баланса миноритарного и мажоритарного классов в выборке можно воспользоваться алгоритмами SMOTE или ASMO из библиотеки imblearn.
Оба алгоритма осуществляют поиск «ближайших соседей». Такой метод желательно использовать, когда есть большая уверенность, что в миноритарном классе все объекты по своим параметрам являются представителями данного класса. В нашем случае объекты попали в миноритарный класс на основе суждений аналитиков и в процессе балансировки выборки на основе разработанного алгоритма, были обнаружены объекты, которые по своим параметрам оказались наиболее яркими представителями для отнесения их в миноритарный класс.