/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
При решении практических задач классификации часто приходится сталкиваться с дисбалансом классов. Такая ситуация может влиять на итоговый результат модели. Хочу рассказать, как дисбаланс и его устранение отражается на результатах классификации на примере простого классификатора логистической регрессии.
В процессе работы покажу, как на результаты модели влияет устранение дисбаланса разными методами: автоматической балансировкой, уменьшением или увеличением класса. Реализуем эти подходы и выберем лучший метод для тестовой выборки.
Для примера взяты данные о сердечных заболеваниях с сайта Kaggle (Heart Disease). В исходных данных 229 наблюдений, из которых 165 (72%) относятся к единичному классу и 64 (28%) – к нулевому.
Подготовим исходные данные:
data = pd.read_csv('heart.csv')
features = data.drop(['target'], axis=1)
target = data['target']
features_valid, features_test, target_valid, target_test = train_test_split(features, target, test_size=0.25,
random_state=42)
Для начала посмотрим на элементарную модель логистической регрессии с автоматической балансировкой классов с помощью параметра class_weight=’balanced’:
model_lr = LogisticRegression(class_weight='balanced')
model_lr.fit(features_train, target_train)
predictions = model_lr.predict(features_valid)
print("Accuracy:", accuracy_score(predictions, target_valid))
print("F1:", f1_score(predictions, target_valid))
Получаем следующие метрики: Accuracy: 0.7931034483; F1: 0.857142857.
Теперь попробуем сделать тоже самое вручную. Сбалансировать классы можно двумя способами — путем увеличения меньшего класса с помощью случайного дублирования или путем уменьшения большего класса с помощью случайного удаления наблюдений.
Создадим функцию для увеличения меньшего класса:
def upsample(features, target, repeat):
features_zeros = features[target == 0]
features_ones = features[target == 1]
target_zeros = target[target == 0]
target_ones = target[target == 1]
features_upsampled = pd.concat([features_zeros] + [features_ones] * repeat)
target_upsampled = pd.concat([target_zeros] + [target_ones] * repeat)
features_upsampled, target_upsampled = shuffle(
features_upsampled, target_upsampled, random_state=12345)
return features_upsampled, target_upsampled
Применим функцию с числом повторений 3 (чтобы примерно выровнять пропорции) и посмотрим, как изменятся метрики для такой модели:
features_upsampled, target_upsampled = upsample(features_train, target_train, 3)
model = LogisticRegression()
model.fit(features_upsampled,target_upsampled)
predicted_valid = model.predict(features_valid)
print("Accuracy:", accuracy_score(predicted_valid, target_valid))
print("F1:", f1_score(target_valid, predicted_valid))
Модель показывает следующие результаты: Accuracy: 0.8275862069; F1: 0.8936170213.
Создадим функцию для уменьшения большего класса и сразу применим ее в работе:
def downsample(features, target, fraction):
features_zeros = features[target == 0]
features_ones = features[target == 1]
target_zeros = target[target == 0]
target_ones = target[target == 1]
features_downsampled = pd.concat(
[features_zeros.sample(frac=fraction, random_state=12345)] + [features_ones])
target_downsampled = pd.concat(
[target_zeros.sample(frac=fraction, random_state=12345)] + [target_ones])
features_downsampled, target_downsampled = shuffle(
features_downsampled, target_downsampled, random_state=12345)
return features_downsampled, target_downsampled
features_downsampled, target_downsampled = downsample(features_train, target_train, 0.39)
model = LogisticRegression()
model.fit(features_downsampled,target_downsampled)
predicted_valid = model.predict(features_valid)
print("Accuracy:", accuracy_score(predicted_valid, target_valid))
print("F1:", f1_score(target_valid, predicted_valid))
Получаем следующие метрики: Accuracy: 0.79310344828; F1: 0.875.
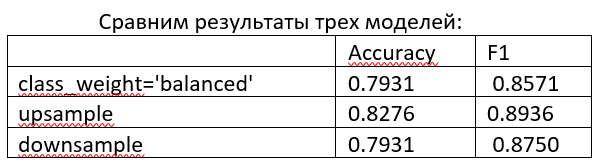
Таким образом, модель с увеличением меньшего класса показывает метрики выше. Можно применить ее на тестовой выборке:
model = LogisticRegression()
model.fit(features_upsampled,target_upsampled)
predictions = model.predict(features_test)
print("Accuracy:", accuracy_score(predictions, target_test))
print("F1:", f1_score(predictions, target_test))
Результаты: Accuracy: 0.896551724137931; F1: 0.9302325581395349
Можно сделать вывод, что устранение дисбаланса классов положительно влияет на метрики итоговой модели. В конкретно рассмотренной модели наилучший результат показал метод увеличения меньшего класса. Однако, в целом, различия между методами не так велики и для других данных лучший результат может показать другая модель.