/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 5 мин.
Обучение с подкреплением (reinforcement learning, RL) является разделом машинного обучения, активно развивающимся направлением в искусственном интеллекте. В данном посте я хочу показать, как с помощью нехитрого трюка ускорить обучение алгоритма RL, на примере окружения игры в Gym.
Gym — это набор инструментов для разработки и сравнения алгоритмов обучения с подкреплением.
Основные методы окружения (env):
• reset() − инициализация окружения, возвращает первое наблюдение;
• step(a) − выполнить в среде действие 𝐚 и получить кортеж: (𝐬𝐭+1, 𝐫, 𝐭𝐞𝐫𝐦𝐢𝐧𝐚𝐭𝐞𝐝, 𝐭𝐫𝐮𝐧𝐜𝐚𝐭𝐞𝐝, 𝐢𝐧𝐟𝐨) , где 𝐬𝐭+1,следующее состояние, 𝐫 вознаграждение, 𝐭𝐞𝐫𝐦𝐢𝐧𝐚𝐭𝐞𝐝 флаг завершения эпизода (проигрыш), 𝐭𝐫𝐮𝐧𝐜𝐚𝐭𝐞𝐝 флаг завершения эпизода по step-лимиту);
• render() − визуализация текущего состояния среды;
• close() − закрывает окружение;
• env.observation_space информация о пространстве состояний;
• env.action_space − информация о пространстве действий.
Описание задачи
Агент (обучаемый алгоритм) управляет правой ракеткой, и соревнуется с левой ракеткой, управляемой компьютером. Каждый из них пытается отклонить мяч от своих ворот в ворота соперника. Цель игры обучить алгоритм, так чтобы обыгрывать компьютер. Игра пинг понг выбрана случайно, исходя из простоты и понятности. На сайте Gymnasium Documentation можно выбрать любую представленную игру Atari , их там свыше 50. Главное, чтобы в окружении агента в качестве состояния было изображение, и был ограниченный дискретный набор действий.
Реализация
Ниже представлен код инициализации окружения и загрузки основных библиотек.
!pip install -q "gymnasium[atari, accept-rom-license]"
import gymnasium as gym
import matplotlib.pyplot as plt
env = gym.make('PongNoFrameskip-v4')
env = gym.wrappers.AtariPreprocessing(env,terminal_on_life_loss=False, grayscale_obs=True,grayscale_newaxis=False, scale_obs=True)
env = gym.wrappers.FrameStack(env, 4)
n_states = env.observation_space.shape
n_actions = env.action_space.n
n_actions = 6, n_states : (4, 84, 84)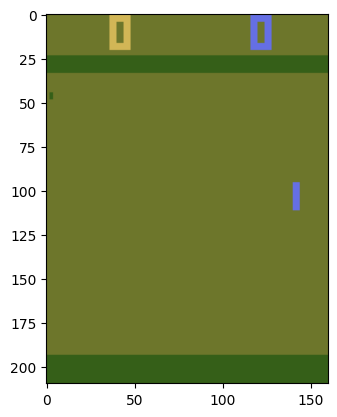
Агент может совершить одно из шести действий, в пространстве состояний, в нашем случае это массив размерностью (4, 84, 84), что означает 4 кадра картинки поля размером 84 на 84.
Приведем для примера вариант игры со случайной стратегией, то есть агент выбирает действие случайно.
env.reset()
total_reward = 0
done = False
k = 0
while not done:
s, r, terminated, truncated, _ = env.step(env.action_space.sample())
total_reward += r
done = terminated or truncated
k = k + 1
Вознаграждение, которое получает агент при случайной стратегии составляет –21 и он проигрывает, чтобы выиграть компьютер, необходимо получить вознаграждение в размере +21. Для достижения этой цели я обучу собственный алгоритм. Он довольно сложный, посмотреть его можно по ссылке на GitHub.
Я приведу основную функцию запуска.
При случайной стратегии агент проигрывает, совершая в среднем около тысячи действий (движений ракеткой).
Рассмотрим два варианта обучения алгоритма, первый – стандартный (агент играет игру до конца), второй – предлагаемый мной к рассмотрению в этом посте.
- Агент играет полный эпизод (всю игру) и учится набирать +21 очко, совершая при этом более 1000 действий за одну игру.
- Агент играет часть эпизода, совершая при этом ровно 300 действий за одну игру и учится набирать максимальное количество очков, которое успевает заработать за 300 движений ракеткой, это около + 3 очков. После того как модель обучилась играть до +3 очков, веса этой модели подаём на вход модели из первого варианта, которая играет полную игру, в результате, достаточно одной игры, чтобы выйти на максимальный результат.
Я хочу показать в посте, что вариант обучения при игре только в часть эпизода, эффективнее по затраченному времени на обучение.
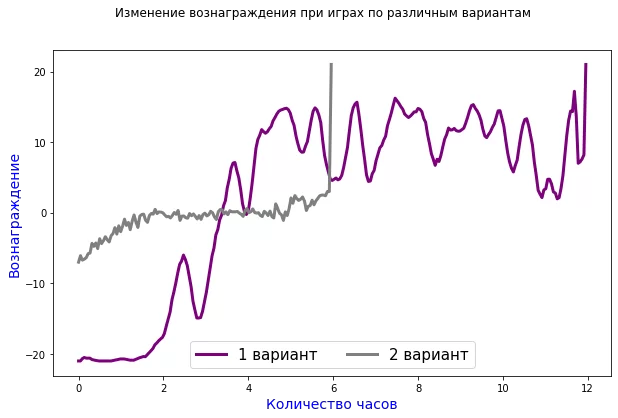
Обучение проходит следующим образом, алгоритм (использовалась нейросеть) принимает исходное состояние и возвращает одно из шести действий, которое в свою очередь подаётся на вход в окружение, и агент получает вознаграждение или штраф. Ниже на графике приведено сравнение обучения обоих вариантов:
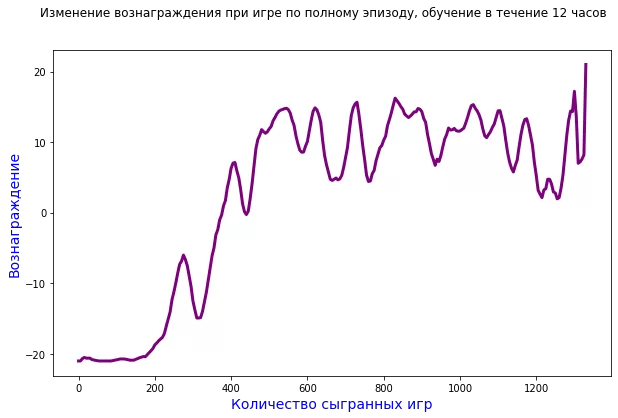
При игре в полный эпизод, график обучения выглядит следующим образом:
А при игре в укороченный эпизод, график обучения выглядит так:
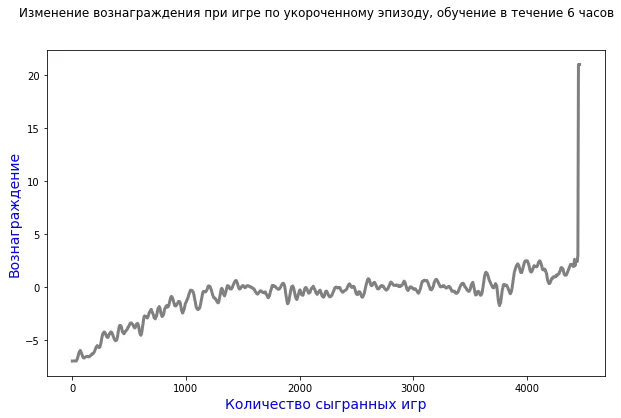
Таким образом, агент, обучаясь на коротком эпизоде игры, тратит в два раза меньше времени, чтобы получить максимальное вознаграждение, при этом количество сыгранных игр в три раза больше. Если играть ещё более короткий эпизод, например, не до трёх очков, а до одного, очевидно, что игр потребуется ещё больше, и алгоритм сойдётся к оптимальной точке, сочетания времени, объёма потребляемой памяти и количества сыгранных эпизодов.
Итог
Применить данный метод можно практически в любом окружении, где в качестве состояния выдаётся изображение и правило получения вознаграждения, не меняются в течение времени.
К минусам данного подхода и вообще RL в целом, можно отнести сложность создания самого окружения для реальной задачи. В рассматриваемом примере окружение уже написано и задача состояла только в том, чтобы обучить агента. Но если такое окружение уже есть, то данный подход принесет экономию времени и видеопамяти.
Обучение с подкреплением в настоящее время имеет небольшую сферу применения, и в основном это робототехника, различные системы рекомендации (музыки, интернет ресурса и т. д.), но несомненно это быстро развивающаяся технология найдет применение и в аудите.