15.04.2022, Маркова Виктория,г. Воронеж Доверять Джини или нет: вот в чем вопрос
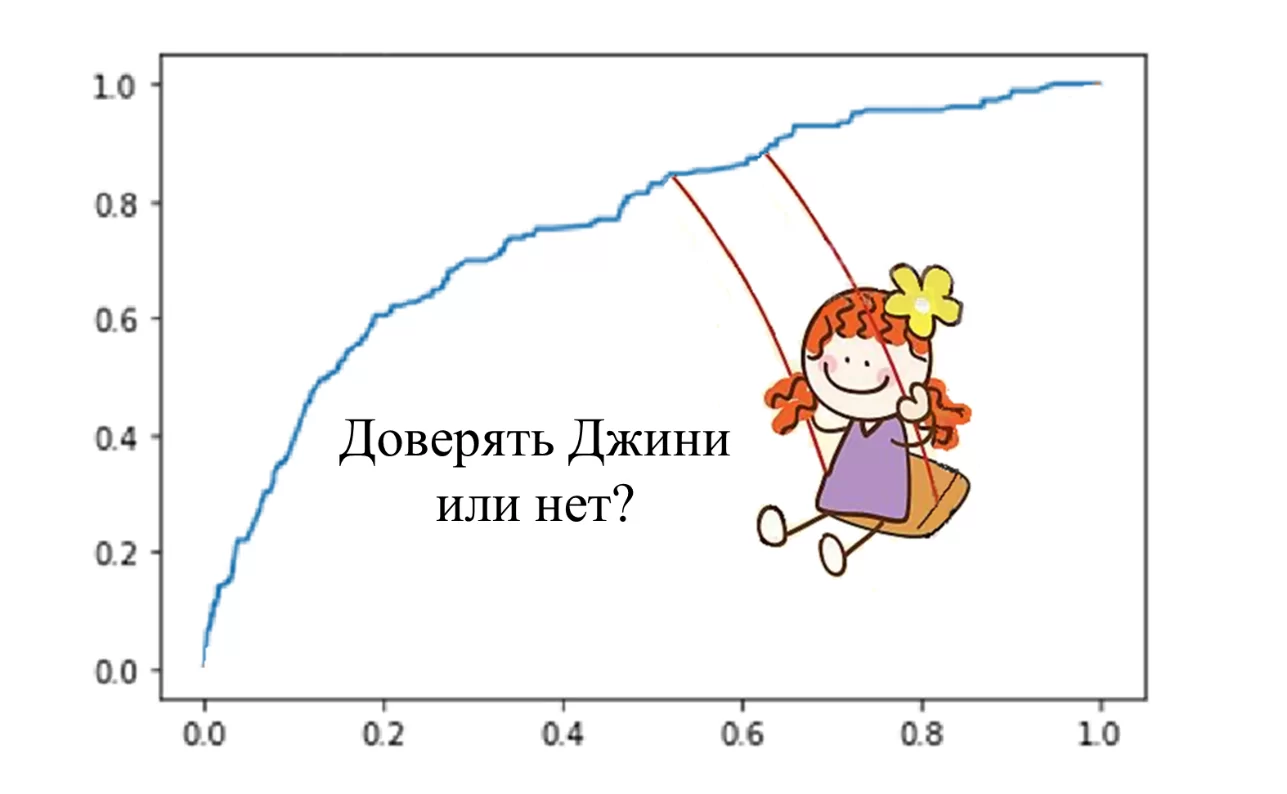
Коэффициент Джини, кривая Лоренца, TPR и FPR– одни из самых популярных атрибутов экономических задач, решаемых с помощью ML. Все они используются для оценки качества модели и, так или иначе, связаны друг с другом. Предлагаю вспомнить, как они рассчитываются
/img/star (2).png.webp)
/img/news (2).png.webp)











/img/event.png.webp)