/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
В процессе работы над двумя разными проектами перед нами дважды встала одна и та же прикладная задача: рассчитать время простоев. В обоих случаях надо было провести расчет с учетом недельного графика работы. Мы начинали решать задачу с создания локального сценарного решения. Но в какой-то момент стало понятно, что задача расчета требует большого количества усилий и учёта множества нюансов. Тогда мы и задумались: а можно ли сделать что-то изящное (в сравнении с базовыми решениями), что будет применимо к любому (в пределах разумного) графику и что можно будет потом использовать в других проектах? (спойлер: да).
- Постановка задачи, частные решения и их проблемы
Оценка потерь является важной прикладной задачей. Один из базовых способов этой оценки выглядит следующим образом. Пусть у нас есть актив, который приносит n рублей в день. Если наш актив выбыл на неделю, потери составят 7n. Тут все просто. Теперь усложним: пусть актив приносит доход только часть суток и не всю неделю, а только в определенные дни; пусть он выбыл на период с А по В и нам необходимы точные расчёты. Получается задача, которая в общем виде выглядит так: сколько рабочего времени прошло между временными отсечками A и B, если рабочие часы заданы графиком X?
Рассмотрим возможные сценарии. Пусть S – это начало рабочего дня, F – его окончание, а точки А и В лежат внутри рабочего дня. Тогда наш алгоритм должен быть составлен с учетом 6 возможных сценариев.
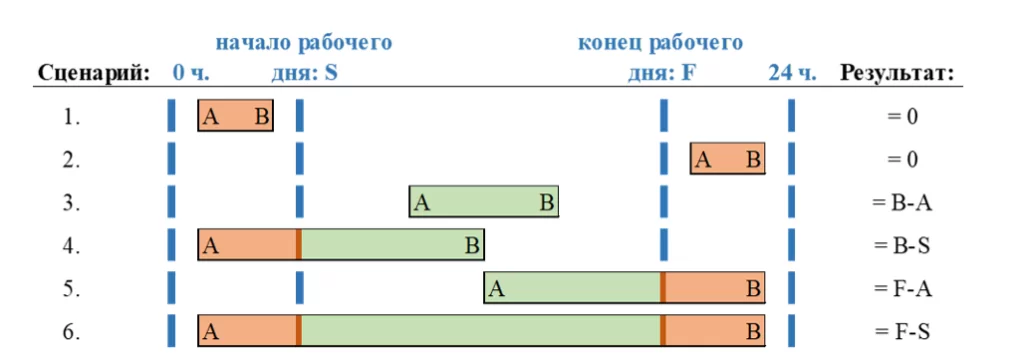
Если точки A и B принадлежат разным дням, то в алгоритм добавляется ещё какое-то количество сценариев.
Когда у нас в рабочем графике есть только точки S и F, а потери времени прекращаются в пределах одних суток, то задача решается просто – потерю времени находят как объект timedelta. Пример такого решения описан в посте на Habr.com «Нахождение длительности временных интервалов в Python». Однако этот алгоритм значительно усложняется, когда отсечек на временной шкале становится много (в пределах одного дня или при потерях времени длительностью более одного дня), а условия включения или исключения интервалов нельзя описать простым правилом.
В этом случае задача базово решается перебором/проверкой всех возможных сценариев с использованием оператора ветвления if-elif-else. В чем тут проблема? Такое решение очень неустойчиво к модификациям исходных условий. Например, если мы добавляем обеды, то длина нашего алгоритма увеличивается примерно в 2 раза. А есть ещё круглосуточная работа и ночная работа. Итого, мы должны описать с полсотни сценариев. Часть из них можно объединить, но такое объединение сильно усложнит алгоритм и сделает код нечитабельным. В общем, не будем останавливаться на доказательстве тезиса «почему 20+ elif это плохо».
Есть решения, претендующие на большую универсальность. Habr-пост из смежной области «SQL: задача о рабочем времени» как раз об этом. Метод предполагает подсчет общего количества дней за вычетом выходных и праздничных дней, а затем умножение этого числа на количество рабочих часов. Однако этот блок решений тоже не универсален. Если мы посмотрим внимательно, то увидим, что в код заложены кастомные данные по режиму работы. Следовательно, любые изменения входных данных потребуют доработки кода.
2. Описание алгоритма
Нам нужен алгоритм, которому все равно, с какой сложностью описан график и какой длины отрезок АB, а значит он не должен оперировать сценариями. Как он может выглядеть?
Представим наши потери времени следующим образом:
- отложим на прямой точки A и B, пометив первую точку белым флагом (старт потерь), а вторую – флагом с шахматным принтом (финиш потерь);
- также отложим на прямой отсечки согласно нашему графику работы, пометив их флагами зелёного цвета (начало работы) или красного цвета (окончание работы).
Разберем на примере.
- точка А: 01.03.2023 11:00;
- точка B: 02.03.2023 13:30;
- график X: пн-пт с 10:00 до 19:00, обед с 13:00 до 14:00.
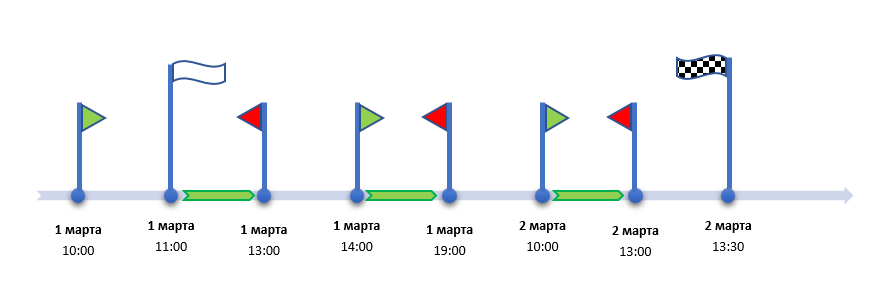
Тут мы используем простую арифметику: искомая величина потерь времени – это сумма разниц между зелёными и красными флажками в пределах белого и шахматного флагов. А значит, все, что нужно, это собрать воедино все временные отсечки и просуммировать интервалы по ним, как показано выше.
Итак, что нужно сделать:
Приведем сразу варианты представления исходных данных. Это датафрейм df, загружаемый из csv/excel-файла.
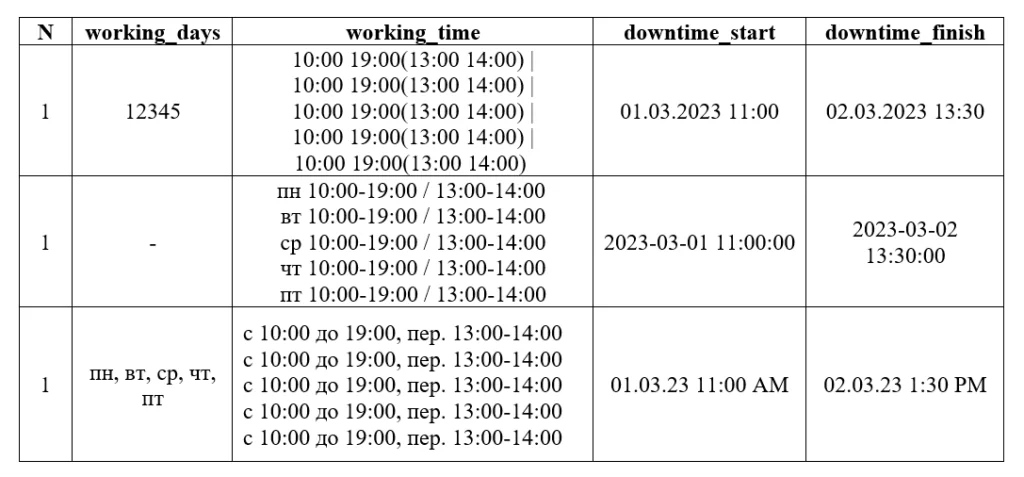
Разберём пошагово наш алгоритм.
Шаг 1:
Представим наш график как список словарей по временным отсечкам для каждого дня недели в следующем виде:
[{time: время, flag: цвет флага, start_finish: ‘’}]
- время согласно графику работы: часы, минуты;
- цвет флага: зелёный – после него время нужно учитывать, красный – после него время учитывать не нужно;
- ‘’ – этому элементу позже будет присвоено значение «старт» или «финиш», в зависимости от того точка А или точка В расположена левее данной временной отсечки.
Для удобства восприятия покажем только values, но подразумеваем, что keys и фигурные скобки тоже присутствуют. В нашем случае получится следующий результат:
Понедельник:
[{time: 10:00, flag: зелёный, start_finish: ‘’},
{time: 19:00, flag: красный, start_finish: ‘’},
{time: 13:00, flag: красный, start_finish: ‘’},
{time: 14:00, flag: зелёный, start_finish: ‘’}]
И так для каждого дня.
Таким образом, на этом этапе нужно составить словарь, включающий режим работы по дням недели с учетом обеденного перерыва. Мы сознательно не приводим код для этой части работы, поскольку, по сути, это подготовка данных, а не сам алгоритм расчета потерь времени. Эта часть зависит от формата представления исходных данных.
Шаг 2:
Схожим образом представим точки A и B:
[{time: дата + время, flag: ‘’, start_finish: старт/финиш}]- дата + время: год, месяц, день, часы, минуты;
- ‘’ – на место этого элемента в дальнейшем будет подставлен красный или зелёный флаг, (по цвету флага ближайшего соседа слева на временной шкале);
- старт/финиш: старт – это точка А, финиш – В.
A: {time: 01.03.2023 11:00, flag: ‘’, start_finish: ‘старт’}
B: {time: 02.03.2023 11:00, flag: ‘’, start_finish: ‘финиш’}
Шаг 3:
Определим все дни между точками A и B включительно и подтянем из графика работы по этим дням все флаги, а также сами точки А и В. Данные из нашего примера превратятся в список. Теперь ключевой момент, на котором, собственно, и строится весь алгоритм: отсортируем список по возрастанию даты и времени. Это важно, т.к. позволит нам идти в цикле от отсечки к отсечке, проверяя, нужно ли включать следующий за ней отрезок в расчет.
[{time: 01.03.2023 10:00, flag: ‘зелёный’, start_finish: ‘’}
{time: 01.03.2023 11:00, flag: ‘’, start_finish: ‘старт’}
{time: 01.03.2023 13:00, flag: ‘красный’, start_finish: ‘’}
{time: 01.03.2023 14:00, flag: ‘зелёный’, start_finish: ‘’}
{time: 01.03.2023 19:00, flag: ‘красный’, start_finish: ‘’}
{time: 02.03.2023 10:00, flag: ‘зелёный’, start_finish: ‘’}
{time: 02.03.2023 13:00, flag: ‘красный’, start_finish: ‘’}
{time: 02.03.2023 13:30, flag: ‘’, start_finish: ‘финиш’}]
Код для шагов 2 и 3:
# функция сбора и сортировки флагов
def collect_downtime (row):
start = pd.to_datetime(row['Point_A'], format = '%d.%m.%Y %H:%M:%S')
finish = pd.to_datetime(row['Point_B'], format = '%d.%m.%Y %H:%M:%S')
schedule = row['schedule']
#список всех дней между точками А и В
day_list = pd.date_range(start.date(), finish.date()).tolist()
# список, куда мы сложим все флаги
target_list_full = []
# обрабатываем каждый день из списка
for current_day in day_list:
target_list_day = [] # переменная для накопления флагов внутри дня
day_begin = current_day.replace(hour=0, minute = 0, second=0, microsecond=0) #начало дня
day_of_week = current_day.dayofweek # день недели
day_schedule = schedule[day_of_week] # график дня недели
#обрабатываем каждую временную отсечку внутри дня. Здесь мы складываем время начала дня с timedelta из графика
for element in day_schedule:
try:
target_element = element
target_element['time'] += day_begin
target_list_day.append(target_element)
except:
pass
target_list_full += target_list_day
# добавим в список начало и конец инцидента, началу сразу присвоим флаг False
target_begin = {'time': start,
'flag': False,
'start_finish': 'Start'}
target_end = {'time': finish,
'flag': '',
'start_finish': 'Finish'}
target_list_full.append(target_begin)
target_list_full.append(target_end)
# ключевой момент: сортируем список флагов по дате
target_list_full = sorted(target_list_full, key = lambda x: x['time'])
result_dict = {'target_list' : target_list_full,
'begin_index' : target_list_full.index(target_begin),
'end_index' : target_list_full.index(target_end)}
return result_dict
# применяем функцию collect_downtime к нашему датафрейму
df['result_dict'] = df.apply(collect_downtime, axis = 1)
Шаг 4:
Необходимо корректно идентифицировать цвет точки старта. Увы, это тот случай, когда все же придется использовать ветвление для проверки цвета флага. Если стартовый флаг первый в списке, то смотрим на ближайший нефинишный флаг справа на временной шкале. Если стартовый флаг не первый в списке, то ориентироваться нужно на ближайший флаг слева.
В нашем примере стартовый флаг следует за зелёным, значит и сам приобретает этот цвет
{time: 01.03.2023 11:00, flag: ‘’, start_finish: ‘старт’}
= > {time: 01.03.2023 11:00, flag: ‘зелёный’, start_finish: ‘старт’}
Шаг 5:
Пройдем в цикле по всему списку от стартового флага до финишного (не включая его) и, если цвет флага зелёный, рассчитаем время до следующего флага:
{time: 01.03.2023 10:00, flag: ‘зелёный’, start_finish: ‘’}
{time: 01.03.2023 11:00, flag: ‘зелёный’, start_finish: ‘старт’} 2 ч.
{time: 01.03.2023 13:00, flag: ‘красный’, start_finish: ‘’} -
{time: 01.03.2023 14:00, flag: ‘зелёный’, start_finish: ‘’} 5 ч.
{time: 01.03.2023 19:00, flag: ‘красный’, start_finish: ‘’} -
{time: 02.03.2023 10:00, flag: ‘зелёный’, start_finish: ‘’} 3 ч.
{time: 02.03.2023 13:00, flag: ‘красный’, start_finish: ‘’} -
{time: 02.03.2023 13:30, flag: ‘’, start_finish: ‘финиш’}
Итого искомое время 2+5+3 = 10 часов.
Код для шагов 4 и 5:
# функция расчета рабочего времени. На вход – словарь, результат функции collect_downtime
def calculate_downtime (row):
target_list = row['result_dict'].get('target_list')
begin_index = row['result_dict'].get('begin_index')
end_index = row['result_dict'].get('end_index')
time_sum = dt.timedelta(0) # переменная для накопления времени
#надо проставить метки True/False для начала и конца инцидента
# если точка А не первая в списке, тогда ориентируемся на предыдущую отсечку:
if begin_index != 0:
target_list[begin_index]['flag'] = target_list[0]['flag']
# точка А первая в списке, точка B не вторая:
elif (end_index != 1):
target_list[begin_index]['flag'] = not (target_list[1]['flag'])
# точка А первая в списке, точка B вторая:
else:
target_list[begin_index]['flag'] = not (target_list[2]['flag'])
# теперь у всех отсечек, кроме финишной, есть признак True/False. Пройдем последовательно по всем отсечкам
for i in range(end_index - begin_index):
time_period = dt.timedelta(0) # переменная для накопления времени простоя
if target_list[i+ begin_index]['flag'] == True:
time_period = target_list[i+1+begin_index]['time'] - target_list[i+begin_index]['time']
time_sum += time_period
return time_sum.total_seconds() / 60 #сразу преобразуем в минуты
# применяем функцию calculate_downtime к нашему датафрейму
df['calculate_downtime'] = df.apply(calculate_downtime, axis = 1)
3. Преимущества алгоритма
- Нечувствительность к изменениям графика работы
Это главное преимущество алгоритма. График работы может быть любым: произвольное число рабочих дней в неделю, ночная работа, круглосуточная работа, произвольно распределённые перерывы. По всем этим вариантам алгоритм отработает корректно.
- Быстрота исполнения кода
Для сравнения производительности предлагаемого алгоритма с традиционным решением на основе ветвления, провели тестирование на датасете из 100 000 строк. Результаты говорят сами за себя: затраты времени на выполнение кода составили 3283 секунды для традиционного алгоритма против 127 секунд для нашего алгоритма. То есть наш алгоритм на основе размеченного списка временных отсечек почти в 26 раз быстрее обычного кода на основе оператора ветвления if-elif-else.
4. Ограничения
Чтобы алгоритм отработал корректно, важно учесть и отработать ряд нюансов. Примем, что мы имеем дело с «чистыми» данными и что у нас нет:
- Незакрытых периодов, когда интервал указан без начала или без конца: рабочий день с хх:хх до 18:00;
- Перепутанных периодов, когда начало идет после конца: обед 13:00 до 12:00;
- Интервалов, ошибочно указанных в других, неподходящих интервалах: обеды в нерабочее время.
Тогда основные ограничения могут быть следующими.
Необходимо внимательно обработать случаи, когда в графике используется время 24:00
Мы реализуем алгоритм с помощью библиотеки datetime, а она просто не знает, что такое 24:00. Будем исходить из того, какая точность результата нам необходима. В нашем случае абсолютная точность не нужна, поэтому просто заменяем 24:00 на 23:59. Если этого недостаточно, можно заменить на 23:59:59.999 и т.д.
Данная версия алгоритма ориентирована на графики, привязанные к дням недели
Поскольку вариаций графиков может быть очень много, полностью универсальным решением будет только использование полного производственного календаря всего исследуемого периода с указанием индивидуального графика каждого дня. Алгоритм в этом случае даже упростится: чтобы узнать график конкретного дня, не нужно будет дополнительных операций. Но несколько усложнится задача подготовки данных. В данном посте исходим все же из того, что раскладка по дням недели полностью описывает график рабочего времени.
5. Заключение
В посте мы привели универсальный алгоритм расчета потерь рабочего времени. Дальше эти данные могут быть привязаны к деньгам, клиентам, любым ресурсам. Алгоритм реализован на языке Python с использованием всем хорошо знакомых библиотек pandas и datetime. С его помощью можно эффективно обрабатывать датасеты длиной в миллионы строк и получать не оценочный, а точный результат. В итоге мы решили создать свой алгоритм, который можно и брать как есть, и, поняв основную идею, достаточно легко воспроизвести с нуля для вашей задачи в привычных вам инструментах. Надеемся, что пост будет вам полезен. Будем рады комментариям и предложениям по улучшению кода.
Ссылка на notebook: https://www.kaggle.com/code/elenakorsakova/downtime-calculation