/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Часто при анализе данных нам приходится работать со столбцами типа datetime, работа с которыми может сопровождать определенными проблемами. К счастью, Pandas успешно справляется с вызванными трудностями.
Например, при импорте данных в DataFrame без передачи дополнительных аргументов, даты по умолчанию могут быть представлены в виде строки, из-за чего нельзя корректно произвести их сортировку и построить визуализацию:
df = pd.read_csv('тест.csv')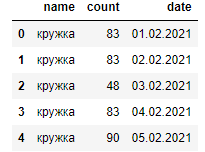
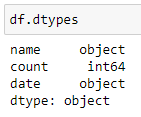
Как видим столбец «date» представлен в формате “object”.
Чтобы это исправить, при импортировании csv-файла, необходимо в функцию read_csv() передать аргумент «parse_dates» с именем столбца, содержащего даты:
df = pd.read_csv('тест.csv', parse_dates=['date'])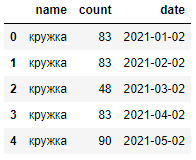
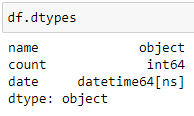
Нам удалось преобразовать столбец date в нужный нам тип «datetime64[ns]», но в то же время появилась новая проблема. Часть данных преобразовалась в формат “гггг-дд-мм”. Чтобы этого избежать и привести наши даты в формат “гггг-мм-дд” при импорте необходимо дополнительно передать аргумент «dayfirst» со значением «True»:
df = pd.read_csv('тест.csv' ,parse_dates=['date'], dayfirst=True)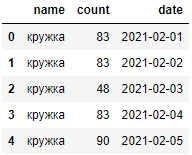
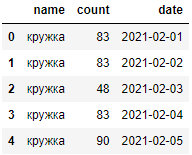
Также изменить тип данный в столбце, содержащим даты можно и после импорта, при помощи функции to_datetime(), при необходимости добавляя аргумент «dayfirst»:
df = pd.read_csv('тест.csv')
df['date'] = pd.to_datetime(df.date, dayfirst=True)
Если же в нашем датасете дата разбита на отдельные столбцы, например «год», «месяц», «день», то при импорте данных их можно объединить, передав через параметр «parse_dates» список списка наименований столбцов:
df = pd.read_csv('тест.csv', parse_dates=[['год','месяц','день']])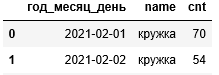
В данном случае наименование столбца «год_месяц_день» создаётся автоматически. Если мы хотим указать собственное имя столбца, то вместо списка через параметр «parse_dates» необходимо передать словарь:
df = pd.read_csv('тест.csv', parse_dates={'date':['год','месяц','день']})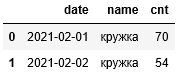
Бывает, что дата в датасете может быть написана в произвольном порядке, например «ддммгггг чч:мм:гггг». В таком случае передача параметра «parse_dates» будет недостаточным для преобразования в тип «datetime64[ns]». Выручит нас модуль datetime и лямда-функции. С их помощью можно написать собственный синтаксический анализатор, который на вход принимает дату и время определенного шаблона, а на выходе получает дату и время в формате «гггг-дд-мм чч:мм:сс». Для начала импортируем datetime:
from datetime import datetimeНапишем лямда-функцию, в которой указываем шаблон даты и времени аналогичный дате и времени в нашем датасете:
custom_datetime = lambda x: datetime.strptime(x, '%d%m%Y %H:%M:%S')Далее при импорте данных через параметр «date_parser» передаем созданную ламда-функцию совместно с «parse_dates»:
df = pd.read_csv('тест2.csv', parse_dates=['date'], date_parser=custom_datetime)
Данный способ хоть и увеличивает время импорта данных, но позволяет самим настраивать анализатор и преобразовывать дату и время из любого формата.
Столбец «date» преобразован в нужный формат и тип, и мы можем приступать к анализу.