/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Различные соревнования в области Data Science не только позволяют на практике применить имеющиеся навыки, но и мотивируют изучать для победы новые методы и алгоритмы. Зачастую решение может быть получено несколькими путями, с разной степенью оптимальности и качества. В статье я расскажу о своем опыте участия во внутреннем DS-соревновании, в ходе которого узнал и использовал нескольких различных алгоритмов решения задачи.
Описание задачи
Суть соревнования заключалась в следующем. Имеется некоторое игровое поле «магазин», на котором случайным образом размещены несколько типов объектов:
- Игрок (может перемещаться в четырех направлениях – вверх, вниз, влево, вправо).
- Препятствия (ограничивающие рамки игрового поля также считаются препятствиями).
- Продукты, имеющие 2 свойства:
- коэффициент важности (importance);
- оставшееся количество (countLeft).
Остальные клетки пусты (доступны для перемещения).
Визуально игровое поле я представил для себя в таком виде:
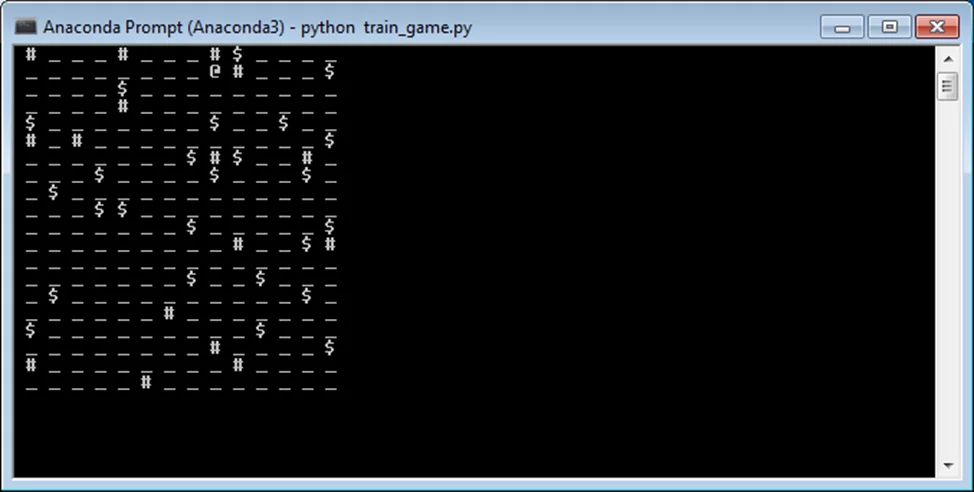
Здесь символ @ обозначает игрока, # — препятствия, _ — свободное поле, а $ — продукты.
Количество набранных игроком очков увеличивается при сборе продуктов и уменьшается с каждым совершенным ходом. При попытке переместиться на клетку с препятствием игрок не совершает движение, при этом счетчик его ходов увеличивается. Также каждый ход количество оставшихся продуктов может быть уменьшено на единицу.
Целью соревнования является набор максимального количества очков путем сбора размещенных на игровом поле продуктов за минимальное число шагов. Соревнование продолжается, пока все продукты не будут собраны или не пропадут. Досрочное прекращение игры не допускается.
Базовое решение
Базовое решение заключалось в прописывании игроку четких правил совершения действий с проверкой состояния клетки, на которую предполагалось перейти, чтобы не врезаться в препятствия.
Для этого я сначала рассчитывал расстояние от игрока до каждого продукта с помощью метрики известной, как «Расстояние городских кварталов» или «Манхэттенское расстояние». В двумерном пространстве для двух точек с координатами (х1,у1) и (х2,у2) его можно рассчитать по формуле:
L = |х2 — х1| + |у2 — у1|
Затем выбирал с помощью полученных значений ближайший продукт и направлял игрока к нему. Если для нескольких продуктов расстояние было одинаковым, целью выбирал продукт с максимальной важностью. После достижения цели список продуктов обновлялся, а расстояния пересчитывались.
Достаточно быстро в этом подходе выявилась проблема – метрика расстояния не учитывала случаи, когда продукт был закрыт от игрока препятствием. Например, в этой ситуации:
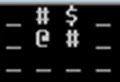
манхэттенское расстояние равняется 2, хотя для того, чтобы достигнуть продукта, игроку понадобится 6 шагов.
Кроме того, существовала проблема с описанием порядка действий игрока для достижения цели. Необходимо было предусмотреть массу вариантов, когда на пути встречается препятствие, чтобы можно было его обойти. Код программы разросся за счет большого количества условий. При этом, все равно могли встретиться ситуации, не предусмотренные алгоритмом.
Улучшенное решение
Развитием базового решения стала замена алгоритма расчета расстояния до ближайшего продукта на более подходящий вариант. Я решил использовать алгоритм поиска «А*» («А со звездой» или «А стар»). Он находит путь к одной заданной точке и отдаёт приоритет тем путям, которые ведут ближе к цели. При этом при построении пути учитываются возможные препятствия.
Основой алгоритма «А*» является формула F = G + H. В ней F – общая стоимость узла, G – расстояние между текущим и начальным узлом (стоимость перемещения между ними), H – эвристически оцененное расстояние от текущего до конечного узла (ориентировочная стоимость перемещения между ними).
Основные шаги этого алгоритма для двумерной сетки перечислены ниже:
- Добавляем начальный узел в открытый список.
- Повторяем следующие действия:
- Находим в открытом списке узел с наименьшей стоимостью F (назовем его текущим узлом).
- Переносим его в закрытый список.
- Для каждого из 8 узлов, прилегающих к текущему узлу, проверяем:
- Если он недоступен для перехода или находится в закрытом списке, игнорируем его. В противном случае выполняем следующие действия:
- Если его нет в открытом списке, добавляем его в открытый список. Делаем текущий узел родительским для этого узла. Записываем стоимость узла F, G и H.
- Если он уже есть в открытом списке, проверяем, лучше ли этот путь к узлу, используя в качестве меры стоимость G. Более низкая стоимость G означает, что это лучший путь. Если это так, изменяем родительский узел на текущий узел и пересчитываем оценки G и F узла. Если сохранять открытый список отсортированным по оценкам F, может потребоваться отдельный список для учета изменений.
- Останавливаемся, когда:
- Добавили целевой узел в закрытый список, и в этом случае путь был найден, или
- Не удалось найти целевой узел, и открытый список пуст. В этом случае пути нет.
- Сохраняем путь. Двигаясь в обратном направлении от целевого узла, переходим от каждого узла к его родительскому узлу, пока не достигнем начального узла. Это искомый путь.

Подробнее с алгоритмом «А*» и его реализацией можно ознакомиться в статье по ссылке или здесь.
Новая реализация программы действий игрока учитывала недостатки базового варианта, связанные с некорректным расчетом расстояния до продуктов, скрытых за препятствиями, а также с выбором вариантов действий для достижения цели – игрок просто двигался по оптимальному пути, сформированному алгоритмом.
Но одним из условий соревнования было использование в решении алгоритмов обучения с подкреплением. То есть, необходимо было создать агента, который самостоятельно находил бы оптимальное решение задачи, взаимодействуя с программной средой. В связи с этим, сформированные решения мне не подходили. Однако они стали базой, на которую можно было ориентироваться при оценке решения с помощью RL.
Решение с использованием RL
Обучение с подкреплением (reinforcement learning, RL) является одним из способов машинного обучения, при котором система (агент) самостоятельно учится взаимодействовать с некоторой средой, используя для этого определенный набор действий. При этом окружающая среда реагирует на действия агента, возвращая, так называемые, сигналы подкрепления – некоторую награду за успешные и штраф за ошибочные действия.
Для реализации агента я выбрал RL-алгоритм под названием Q-Learning. Его суть заключается в том, что агент формирует функцию полезности Q на основе получаемого от среды вознаграждения. В дальнейшем это дает ему возможность выбирать стратегию поведения не случайно, а с учетом накопленного опыта взаимодействия со средой.
Алгоритм основан на уравнении Беллмана:
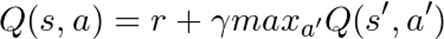
где Q – функция полезности, s – состояние системы, a – действие агента, γ – коэффициент обесценивания будущей награды (число от 0 до 1), r – награда.
Оно означает, что функция полезности Q для каждой пары состояние-действие определяется наградой, полученной агентом при переходе из текущего состояния в новое (путем выполнения заданного действия), добавленной к значению наилучшего действия в следующем состоянии.
Другими словами, в каждый момент времени t агент выбирает из возможных вариантов действие at, в результате выполнения которого получает награду rt, переходит в новое состояние st+1, которое может зависеть от предыдущего состояния st и выбранного действия, и обновляет значение функции Q. Обновление функции использует взвешенное среднее между старым и новым значениями:

здесь rt это награда, полученная при переходе из состояния st в состояние st+1, α это скорость обучения (0 < α ≤ 1) — чем этот коэффициент выше, тем сильнее агент доверяет новой информации, γ – коэффициент дисконтирования (0 < γ ≤ 1) — чем он меньше, тем меньше агент задумывается о выгоде от будущих своих действий.
В первом приближении алгоритм состоит из 5 шагов:
- первоначальная инициализация таблицы со значениями функции полезности Q;
- наблюдение за изменением состояния среды;
- обновление функции полезности;
- выбор дальнейшего действия агента;
- повтор действий со 2 по 4 в цикле.
На первом шаге происходит построение таблицы, содержащей одну строку для каждого возможного состояния системы и один столбец для каждого возможного действия агента. Значения (Q-values) в таблице могут быть инициализированы случайным образом или некой скалярной величиной, например, нулями.
Затем в цикле происходит выбор следующего действия агента, его выполнение, обновление значений в таблице Q в соответствии с полученным значением награды и обновление состояния среды. Для того чтобы агент не застревал на одном месте, получив некоторую промежуточную награду, необходимо время от времени выполнять случайные действия, чтобы в конечном итоге изучить всю карту, исследовав все возможные состояния.
Цикл продолжается до тех пор, пока не будет достигнута конечная точка или агент не будет уничтожен, например, столкнувшись с препятствием.
Обучение агента путем обновления значений в таблице Q происходит в течение некоторого количества эпох. Каждый раз, когда агент достигает цели, увеличивается его понимание оптимального пути до нее. Таким образом, после достаточного количества эпох в таблице Q будет содержаться полная карта возможных состояний, показывающая, как добраться до цели из каждого узла.
Подробнее ознакомиться с алгоритмом Q-learning и его реализацией можно в статьях: здесь или здесь.
Также при знакомстве с алгоритмами обучения с подкреплением мне сильно помог GitHub репозиторий MorvanZhou, в котором содержится большое количество туториалов для понимания различных RL-алгоритмов, реализованных на языке python.
В моем случае при решении задачи соревнования алгоритм Q-learning показал эффективность ниже, чем при использовании алгоритма поиска пути «А*» – предположительно из-за недостаточного количества эпох. Однако в сравнении базовым вариантом программы, основанным на правилах, задача была решена лучше. Это связано с тем, что RL-алгоритм более качественно отрабатывал ситуации с обходом препятствий. Минусом решения стала его ресурсоемкость – при количестве эпох более 1000 время расчета состояний превышало 15 минут (ограничение на время расчета решения в соревновании). В то же время, Q-learning не единственный и не самый эффективный из алгоритмов обучения с подкреплением, а у этого направления есть большой потенциал для применения.