/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 6 мин.
Допустим, необходимо спрогнозировать кредитную благонадежность заемщика. Благонадежный заемщик будет относиться к классу 1, неблагонадежный – к классу 0. Тогда существует четыре вида исхода прогнозирования:
- True Positives — благонадежный заемщик спрогнозирован верно;
- False Positives — благонадежный заемщик спрогнозирован неверно;
- True Negatives – неблагонадежный заемщик спрогнозирован верно;
- False Negatives – неблагонадежный заемщик спрогнозирован неверно.
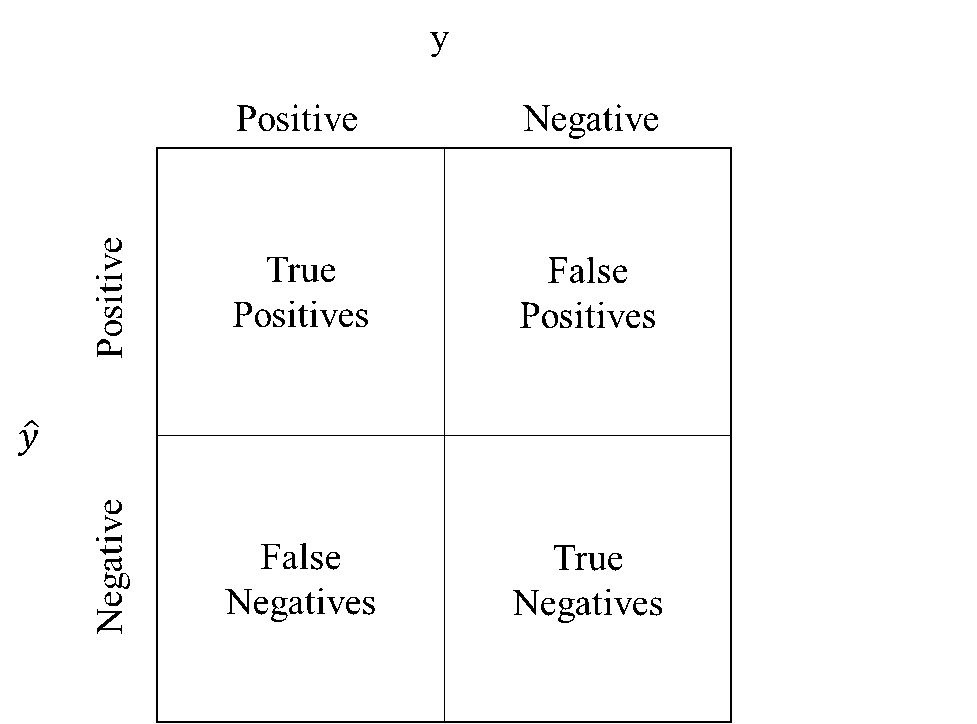
Для нашей задачи TPR = True Positives / (True Positives + False Negatives) является уровнем доходности банка, а FPR = False Positives / (False Positives + True Negatives) – уровнем убыточности банка. При этом, чем лучше один показатель, тем хуже другой. Поэтому вводится порог срабатывания, выше которого прогнозные значения будут относиться к классу 1, ниже – к классу 0 соответственно.
Но для бизнеса мало посчитать показатели. Необходимо принимать решения, математически и статистически обоснованные. Поэтому в анализ включают ROC-кривую, площадь под кривой (AUC) и коэффициент Джини. То есть, строится график отсортированных прогнозных target-значений.
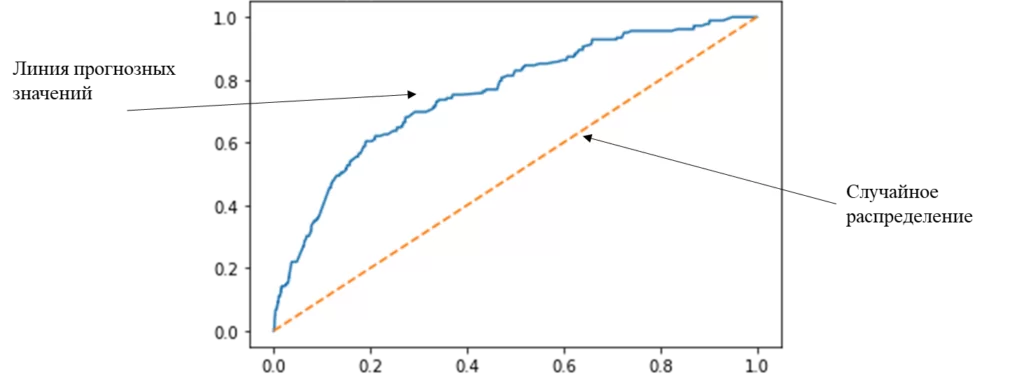
Затем рассчитывается площадь под кривой – площадь фигуры под линией прогнозных значений. Так мы узнаем качество работы нашего алгоритма. А уже коэффициент Джини (Gini = 2 * AUC ROC — 1) используется как итоговая метрика для принятия решений.
Данный показатель прост в расчёте и легко интерпретируем, а значит популярен и часто используется в моделях банковского скоринга. Но достаточно ли одной метрики и можно «положиться» на Gini в управленческих вопросах? Разберемся.
С развитием экономики растёт уровень кредитования, а вместе с ним и уровень задолженности. Возникает необходимость управления кредитным риском. А значит, появляется задача улучшения модели рейтингования заемщиков.
В качестве примера возьмем датасет с наблюдениями по количественным и качественным характеристикам заемщиков на протяжении экономического цикла и более, для которых проставлен признак дефолта. В таблице ниже представлен пример маркированных данных.
| ИНН | ID наблюдения | Дата | F1 | F2 | F3 | F4 | … | F17 | default | split |
| 1234567890 | 1 | 2017-30-09 | 100 000 | 89 | 0,4 | 530 | … | A | 0 | train |
| 0987654321 | 2 | 2018-09-30 | 259 058 | 56 | 0,78 | 942 | … | C | 1 | train |
| 7418529631 | 3 | 2015-12-31 | 1 000 680 | 77 | 0,63 | 5 022 | … | F | 1 | test |
| 1472583699 | 4 | 2020-05-31 | 68 012 | 69 | 0,7 | 135 | … | A | 0 | test |
Необходимо преобразовать качественные показатели. Многие модели машинного обучения работают только с числовыми факторами и не чувствительны к иным. Однако, в бизнесе не всегда важные показатели являются числовыми. Поэтому используют различные способы кодирования переменных. В данной задаче применили WOE-преобразование. Такой подход позволяет придать значимость признаку в формате числа (WOE-вес) и включить его в набор факторов для обучения модели прогнозирования. Важно, чтобы значения показателей были ранжированы, где А – лучшее значение, B – хорошее значение, С – удовлетворительное значение и т.д. WOE-веса рассчитываются как натуральный логарифм от отношения доли хороших наблюдений к доле плохих отношений. Использую следующую функцию:
# df - датасет; split_column – столбец который делит выборку на тестовую и обучающую; split - train/test; factor – столбец фактора.
def woe(df, split_column, split, factor):
woe = pd.concat([np.log((df[(df[split_column] == split) & (df['default'] == 0)][factor]\
.value_counts()/df[(df[split_column] == split) & (df['default'] == 0)][factor].count())\
/(df[(df[split_column] == split) & (df['default'] == 1)][factor]\
.value_counts()/df[(df[split_column] == split) & (df['default'] ==
1)][factor].count())).rename('WOE train')], axis=1)
return woe
# создадим преобразованный столбец для первого фактора
woe_F13 = {'A': woe(df, 'split', 'train', 'F13')['WOE train']['A'],
'B': woe(df, 'split', 'train', 'F13')['WOE']['B],
'C': woe(df, 'split', 'train', 'F13')['WOE']['C'],
'D': woe(df, 'split', 'train', 'F13')['WOE']['D']
}
df['F13_woe'] = df['F13'].replace(woe_F13)
По аналогии преобразую остальные факторы (F14 – F17).
Для прогнозирования использую логистическую модель.
Запишу факторы в отдельный лист для удобства.
feat_cols = [F1, F2, F3, F4, F5, F8, F9, F13_woe, F14_woe, F15_woe, F17_woe]
# разделим датасет на обучающую и тестовую выборки
df_train = df[df['split'] == 'train'][['ИНН', 'ID наблюдения', 'default', 'split'] + feat_cols].copy()
df_test = df[df['split'] == 'test'] [['ИНН', 'ID наблюдения', 'default', 'split'] + feat_cols].copy()
df_full = pd.concat([df_train, df_test], axis = 0).reset_index()
# импортируем библиотеки
from sklearn.linear_model import LogisticRegression
import statsmodels.api as sm
# строим модель
log_reg = sm.Logit(df_train['default'], df_train[feat_cols]).fit()
А теперь посчитаю Джини train / test для прогнозной модели.
from sklearn.metrics import roc_auc_score # импортируем метрику roc auc
print('Gini Train: ', 2 * roc_auc_score(df_full[df_full['split'] == 'train']['default'], log_reg.predict(df_full[df_full['split'] == 'train'][feat_cols])) - 1)
print('Gini Test : ', 2 * roc_auc_score(df_full[df_full['split'] == 'test']['default'], log_reg.predict(df_full[df_full['split'] == 'test'][feat_cols])) - 1)

На основе полученных результатов предварительно было принято решение доверять данной модели. Однако, в ходе анализа модели было предложено рассмотреть возможность добавления нового фактора – F18. Данный показатель является качественным, поэтому требует преобразования с помощью woe функции. Переобучили модель с учетом нового набора предикторов и посчитали Джини.

По результатам видно, что на обучающей выборке качество модели лучше с дополнительным фактором, а на тестовой – без него. Так как решение принимается исходя из большего значения по Gini test, то дополнительный фактор не будет добавлен в модель.
Выбор в пользу модели без нового фактора достаточно противоречив, поэтому рассчитаем дополнительную метрику – среднюю абсолютную ошибку. Данный показатель считается, как среднее разностей между фактическими и прогнозными значениями и не противоречит логике задачи. Для этого импортируем необходимую библиотеку и вычислим ошибку для модели с дополнительным фактором и без него.
from sklearn.metrics import mean_absolute_error
# MAE для модели без нового фактора
print('MAE Train:', mean_absolute_error(df_full[df_full['split'] == 'train']['default'], log_reg.predict(df_full[df_full['split'] == 'train'][feat_cols])))
print('MAE Test:', mean_absolute_error(df_full[df_full['split'] == 'test']['default'], log_reg.predict(df_full[df_full['split'] == 'test'][feat_cols])))

# MAE для модели с новым фактором
print('MAE Train модели с фактором F18:', mean_absolute_error(df_full[df_full['split'] == 'train']['default'], log_reg.predict(df_full[df_full['split'] == 'train'][feat_cols])))
print('MAE Test модели с фактором F18:', mean_absolute_error(df_full[df_full['split'] == 'test']['default'], log_reg.predict(df_full[df_full['split'] == 'test'][feat_cols])))

Средняя абсолютная ошибка интерпретируется как «чем меньше, тем лучше». По результатам видно, что модель с дополнительным фактором предсказала с меньшей ошибкой.
Сравним все полученные результаты метрик.
| Показатель | Split | Модель без доп. фактора (1) | Модель с доп. фактором (2) | Модель с лучшим результатом |
| Gini | Train | 0,5119 | 0,5137 | 2 |
| Test | 0,6297 | 0,6134 | 1 | |
| MAE | Train | 0,3911 | 0,3882 | 2 |
| Test | 0,3953 | 0,3948 | 2 |
Из таблицы следует, что включение нового фактора F18 увеличивает прогнозную силу модели. Однако, такой вывод стал доступен после расчета дополнительной метрики. Напрашивается вывод, что коэффициента Джини недостаточно для оценки качества модели. Чтобы подтвердить гипотезу, необходимо большее количество экспериментов. А в данной статье положено начало для этого.