/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В предыдущей статье «Ликвидация классового дисбаланса в данных. Удаление некоторого числа примеров мажоритарного класса» мы рассмотрели стратегию удаления некоторого числа примеров мажоритарного класса для ликвидации классового дисбаланса. Сегодня мы рассмотрим другой подход.
Для иллюстрации примеров, так же, как и предыдущей статье, возьмём данные о транзакциях по кредитным картам. Целевой столбец “Class” содержит информацию о том, является ли транзакция мошеннической.
Метод, который может применятся для сбалансирования данных – увеличение числа примеров миноритарного класса.
Первый по простоте способ – копирование экземпляров миноритарного класса.
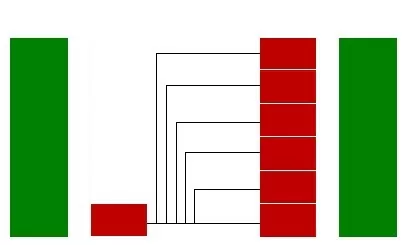
Вычисляется необходимое количество случаев для балансировки классов и производится копирование случайных записей.
from imblearn.over_sampling import RandomOverSampler
x = df.iloc[:, 2:30].values
y = df.Class.values
ros = RandomOverSampler()
x_res, y_res = ros.fit_sample(x, y)
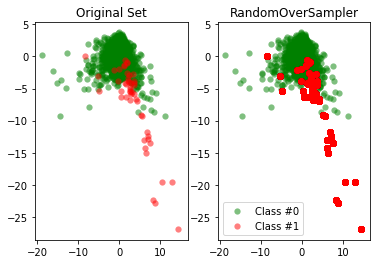
Более яркие красные точки отражают наличие большего количества идентичных данных. Нужно помнить, что обучение модели на множестве дубликатов может привести к созданию переобученной модели.
Иначе работает алгоритм SMOTE. Выбирая экземпляры, которые расположены близко в пространстве признаков, он рисует линию между ними и создаёт новый экземпляр в точке вдоль этой линии.
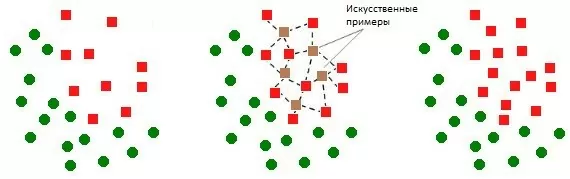
Сначала выбирается случайный экземпляр из класса меньшинства . Затем для него находятся ближайшие соседи (обычно k = 5). Из них выбирается случайный сосед
![]() . Вычисляем разность между векторами признаков экземпляра и выбранного соседа
. Вычисляем разность между векторами признаков экземпляра и выбранного соседа
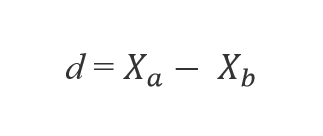
После этого каждое значение нового вектора домножется на случайное число от 0 до 1, получается вектор ![]() . Новый искусственный пример вычисляется по формуле:
. Новый искусственный пример вычисляется по формуле:
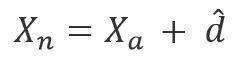
from imblearn.over_sampling import SMOTE
x = df.iloc[:, 2:30].values
y = df.Class.values
sm = SMOTE ()
x_res, y_res = sm.fit_sample(x, y)
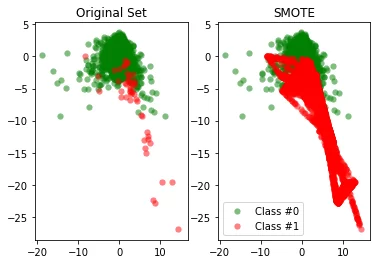
Но нужно заметить что, если миноритарные экземпляры распределены среди мажоритарных и их плотность мала, SMOTE может смешать классы. Чтобы решить эту проблему можно использовать ADASYN — алгоритм адаптивного искусственного увеличения числа экземпляров миноритарного класса. Ключевая идея алгоритма — использовать плотность распределения миноритарногокласса в качестве критерия для автоматического определения количества искусственных образцов, которые необходимо создать для каждого примера миноритарного класса. Для этого в начале рассчитывается степень дисбаланса. mᵣ — миноритарный класс, mₓ — мажоритарный класс.
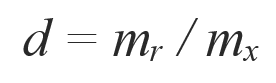
Если d < dₓ (где dₓ предварительно установленный порог для максимально допустимого дисбаланса) тогда: а) Рассчитать количество искусственных примеров, которые должны быть созданы из миноритарного класса:
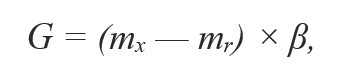
β — уровень баланса созданных искусственных образцов. β = 1 означает, что нужен полный баланс между двумя классами. б) Для каждого xᵢ принадлежащему миноритарному классу, найти k-ближайших соседей и вычислить отношение мажоритарных соседей к общему количеству,
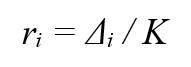
в) Нормализовать rᵢ для всех наблюдений миноритарного класса rₓ ← rᵢ / ∑ rᵢ, так что их сумма становится равна единице. г) В результате, вычисляется количество необходимых искусственных примеров в каждой области
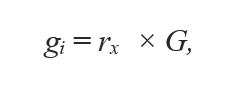
from imblearn.over_sampling import ADASYN
x = df.iloc[:, 2:30].values
y = df.Class.values
ada = ADASYN()
x_res, y_res = ada.fit_sample(x, y)
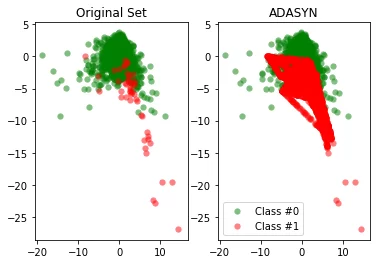
Как мы видим, в области, где распределение миноритарного класса меньше, алгоритм не добавлял новых случаев. Нужно помнить, что применяя метод увеличение числа примеров миноритарного класса, мы рискуем получить зашумлённые данные, что может негативно сказаться на качестве модели, полученной при обучении на этих данных.