/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 13 мин.
Это будет история о том, как мы придумали и приступили к реализации бенчмарка объективным, упорядоченным и унифицированным способом – через написание универсального инструмента.
В первой части публикации представим теоретическую часть задачи, предпосылки, а также первую попытку реализации универсального инструмента. Основные результаты сравнения опишем в следующей части.
В нашей работе часто приходится сталкиваться с задачами обработки больших данных. Традиционный метод обработки, который мы используем — библиотека Pandas. Она предоставляет приятные вещи (чтения форматов из коробки, фильтрации, агрегации, concat, join merge). Всё это позволяет абстрагироваться от технических трудностей, сразу приступая к самому алгоритмически интересному.
Но время идёт, и появляются другие решения — Polars, Koalas, ускорители Numba и Cython, Pandas 2.0 — целый ворох технологий, которые стремятся сделать обработку данных быстрее. И, вроде бы, не так сложно запустить одно и другое, померить время и посмотреть, кто лучше. Однако точечный бенчмарк не даёт полной картины.
У нас возникает потребность качественно проанализировать технологии, чтобы уже не отвлекаться на мысли о том, а что тут можно модернизировать. А ещё желательно, чтобы у нас при этом остался какой-то кусок кода, который можно:
- использовать для бенчмарка новых (или свежевыкопанных, или обновлённых) инструментов;
- пересчитывать на разных ресурсах;
- пересчитывать под конкретную задачу;
- использовать любому человеку и получить достоверный результат.

Теоретическое описание идеи
По классике, при выборе технологии необходимо максимально полно описать альтернативные инструменты, их сильные и слабые стороны. Также понятно, что каждый раз описывать примерные преимущества Pandas и иже с нею не очень-то полезно, хочется конкретики. Многие метрики невозможно качественно оценить на глаз, затратно или невозможно проанализировать теоретически. Поэтому предлагаем создать код, который будет сквозным образом воспроизводить объективный набор экспериментов и выдавать чисто метрики. Для этого рассмотрим, как бы выглядел план экспериментов, если бы мы воспроизводили его более или менее руками.
Получить такой план рассчитываем, «перемножив» два списка — список экспериментов и список альтернатив. Первый из них будет содержать алгоритмическое описание экспериментов (открыть файл, сгруппировать по такой-то колонке, отфильтровать и т.д.), каждый из которых будет давать на выходе некие метрики (время и оперативная память).
Второй — список альтернатив — содержит все доступные технологии и их возможные (или, лучше, имеющие смысл) комбинации/реализации.
Их условное «перемножение» даст нам матрицу, в каждой клетке которой будет находиться значение метрик эксперимента, проведённого для конкретной альтернативы — как, например:
{среднее время работы}{группировки по *условию*}{на pandas + Cython}.
И далее мы бы стали проводить серии испытаний и заполнять матрицу. Как только заполним матрицу до конца, сможем сказать, что исследование исчерпано, и дальнейшее принятие решения будем считать обоснованным — ну, то есть как только заполним, а потом разберём и проанализируем полную картину.

Первый из обозначенных списков — список экспериментов — по нашему представлению, должен содержать множество из пересечения двух составляющих: конкретные данные, на которых будет проводиться исследование, и операции над данными, которые хочется проделать.
Есть ещё метрики, но тут всё довольно-таки тривиально: в основном, когда мы говорим о метриках, имеем в виду скорость, так как именно она очень чувствительна в нашей работе, и ещё занимаемая оперативная память. У них можно посчитать среднее значение на выборке испытаний, потому что скорость, например, довольно сильно «гуляет» от эксперимента к эксперименту. Кроме того, будем просматривать обычное и стандартное отклонения, чтобы убедиться, что среднее значение не оторвано от реальности.
Данные
Начнём с рассмотрения данных, которые были бы максимально похожи на то, с чем приходится работать. Для публикации решили взять на Kaggle набор датасетов big-sales-data.
Мы остановились на датасете Books_rating.csv весом в 2,9 гигабайт и размером в 3 000 000 строк.
Содержание датасета:
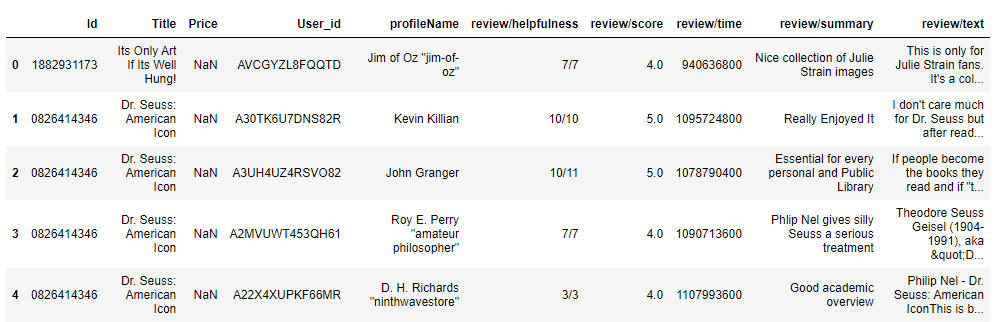
Данные эти качественно отличаются от того, что мы видим в наших «боевых» русскоязычных базах, однако существенные отличия есть и с публичными русскоязычными датасетами, а объём этих данных всё-таки определяет доступный размах. Собственно, признак, по которому наборы данных могут принципиально отличаться друг от друга — это как раз объём. Его станем оценивать в строчках, хотя это и не до конца честно.
Для анализа того, как поведёт себя инструмент на данных разной длины, станем пилить этот датасет на файлики поменьше – с определённой длиной в строчках. Из модуля предполагается проделывать все тесты над рядом файлов, которые лежат в указанной папке.
Операции и альтернативы
Кроме данных, мы должны учитывать какой-то набор операций, а также набор альтернатив. На данный момент излагаем только эскизный этап, наши наброски по этому поводу. Поэтому для начала в качестве операций возьмём чтение из файлов формата csv и операцию groupby, а в качестве альтернатив – модули pandas и polars, имея в виду, что потом эти списки расширятся.
Практическая реализация (попытка номер раз)
Для большей абстрактности решения был придуман подход, при котором мы абстрагируемся от проверяемой альтернативы.
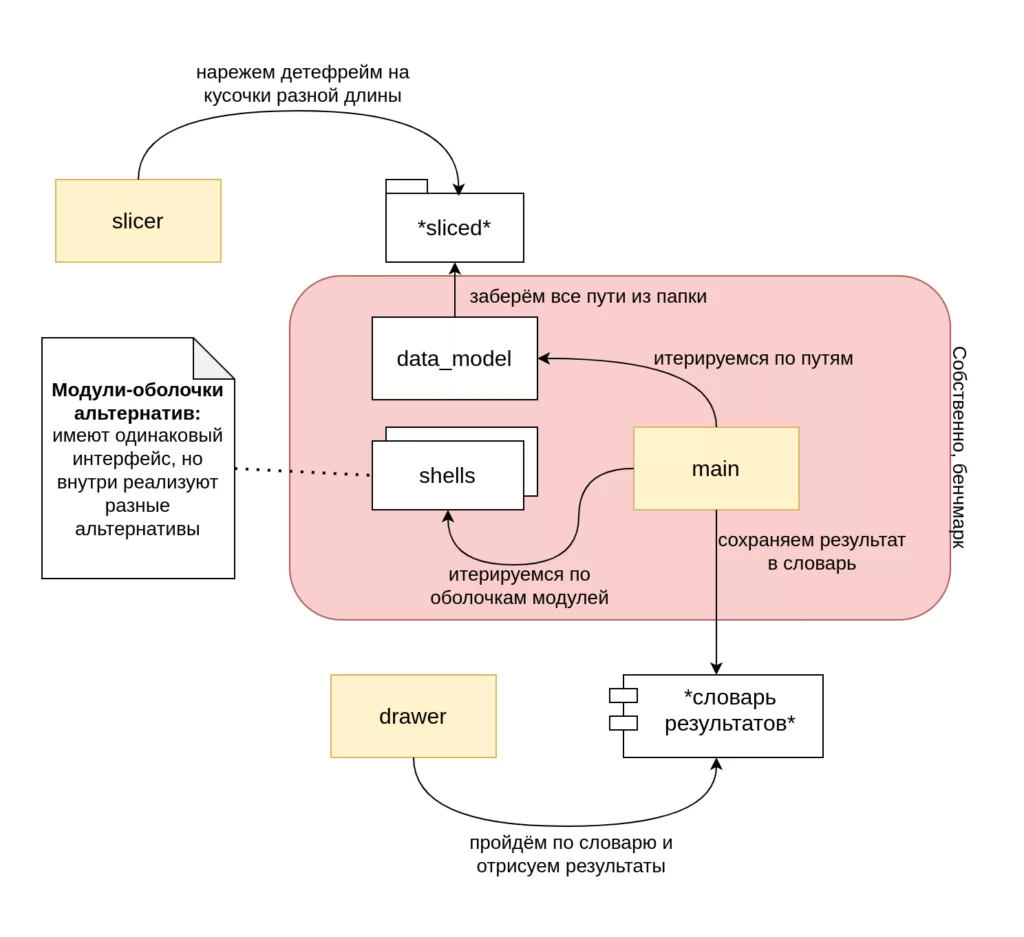
Суть в том, чтобы написать для каждой исследуемой альтернативы особые файлы-обёртки, в которых интерфейс будет унифицирован и подогнан под необходимые эксперименты. Далее из тестового модуля мы думали абстрагировано их перебирать, пробегать сколько надо раз, замерять метрики и т. д. Результаты всех прогонов должны были помещаться в словарь, который потом можно разбирать и анализировать. Ничего сложного, казалось бы. Посмотрим на реализацию.
Модуль slicer: просто на всякий случай
Модуль slicer нарезает большой датафрейм на датафреймы поменьше, а потом смотреть всё в динамике по длине.
Основной код модуля выглядит так:
import os
import math
import pandas as pd
def save_slice(df, n, dir_path):
file_name = 'books_' + str(n) + '.csv'
df.to_csv(os.path.join(dir_path, file_name))
def made_slices(df, n, max_val, min_val, dir_path=None):
if dir_path == None:
dir_path = get_default_save_path()
df = df.iloc[:max_val]
k = math.floor((max_val - min_val) / n)
for i in range(n + 1):
amount = max_val - k * i
if amount <= 0:
continue
save_slice(df.iloc[:(amount)], amount, dir_path)
if __name__ == '__main__':
df = read_default_books()
made_slices(df, 5, 6000, 3000)
Из интересного, что можно рассказать об этой функции: когда она запускалась в промежуточном варианте (там ещё не было минимального порога), она упала где-то на одной тридцатой всех файлов. Это произошло, потому что она заполнила всю — вообще всю — память на ноутбуке. Очень удобно, что всё это она складывает в одной папке, и это можно было быстро удалить. Но, судя по тому, как быстро удалилось это всё, память ноутбука где-то там всё ещё хранит отпечаток размноженного много-много раз big-sales-data.
В общем, модуль рекомендуем применять с осторожностью. Если вдруг попробуете, используйте минимальный порог — он появился там именно после этой истории.
Модули-оболочки: идейное ядро
Для начального примера их было реализовано две — для Pandas и Polars. Операций было имплементировано также немного: open_csv, groupby и длина датафрейма. Мы рассматриваем это как первую эскизную версию, поэтому этих опций будет пока достаточно. Главное, что они включают в себя варьирования по обоим критериям: по альтернативам и по операциям. Вот так выглядит оболочка для Pandas:
import pandas as pd
MODULE_NAME = 'pandas'
PATH_KEY = 'path'
DATA_KEY = 'data'
COL_KEY = 'col'
def open_csv(**kwargs):
return pd.read_csv(kwargs[PATH_KEY])
def groupby(**kwargs):
return kwargs[DATA_KEY].groupby(kwargs[COL_KEY])
def lines(**kwargs):
return kwargs[DATA_KEY].shape[0]
А вот такая оболочка написана для Polars:
import polars as pl
MODULE_NAME = 'polars'
PATH_KEY = 'path'
DATA_KEY = 'data'
COL_KEY = 'col'
def open_csv(**kwargs):
return pl.read_csv(kwargs[PATH_KEY])
def groupby(**kwargs):
return kwargs[DATA_KEY].groupby(kwargs[COL_KEY])
def lines(**kwargs):
return kwargs[DATA_KEY].shape[0]
Как видите, они практически идентичны: взятые операции достаточно просты, и их реализации на разных модулях не имеют различий в коде.
Подобные оболочки можно положить в массив и легко прогонять снаружи — унифицировано и абстрагировано от внутренней реализации. При этом разница реализаций будет проявляться лишь через посчитанные метрики. Как раз то, что нужно.
Файл main: дурная голова ногам покоя не даёт
Всю красоту запускает код, написанный в файле main.py (очень оригинально). Код его довольно длинный, поэтому посмотрим на него по частям. Начнём с импортов:
import os # пути будем перебирать
import time # время вычислять
import resource # и ресурсы посмотрим
import drawer
import data_model
import shells.polars_shell as pl
import shells.pandas_shell as pd
Импортируем встроенные os, time и resources. Далее подключаем наш собственный drawer, чтобы сразу после теста посмотреть, чего насчиталось, и data_model, который, по сути, производит абстракцию над ранее нарезанными данными.
В конце импортируем собственные модули-оболочки — все, которые хотим проанализировать. Для примера у нас их всего две.
Чтобы единожды запустить функцию и получить от неё время и память, написали функцию run_single:
def run_single(test_function, **kwargs): # abstract function for a single check
time_start = time.perf_counter()
test_function(**kwargs)
time_elapsed = (time.perf_counter() - time_start)
memMb=resource.getrusage(resource.RUSAGE_SELF).ru_maxrss/1024.0/1024.0
return time_elapsed, memMb
Она берёт объект функции и kwargs для неё, после чего запускает и возвращает время и память.
Чтобы её пробегать n-ное число раз, применяем функцию run_many:
def run_many(n, test_function, **kwargs): # abstract function for n checks and aggregation
secs = [0] * n
memo = [0] * n
for i in range(n):
secs[i], memo[i] = run_single(test_function, **kwargs)
t_m, t_d, t_sd = count_metrics(secs, to_print=False)
m_m, m_d, m_sd = count_metrics(memo, to_print=False)
return {
'time': {
'mean': t_m,
'diviation': t_d,
'standard diviation': t_sd,
},
'memory': {
'mean': m_m,
'diviation': m_d,
'standard diviation': m_sd,
},
}
Она запустит функцию n раз и на списке из n штук подсчитает метрики при помощи следующего кода:
def count_metrics(samples, to_print=True):
mean_val = sum(samples) / len(samples)
div = 0
st_div = 0
for i in samples:
div += i - mean_val
st_div += (i - mean_val) ** 2
div /= len(samples)
st_div /= len(samples)
st_div **= 0.5
if to_print:
print('Mean value: {a}'.format(a=mean_val))
print('Diviation: {a}'.format(a=div))
print('Standard Diviation: {a}'.format(a=st_div))
return mean_val, div, st_div
Здесь считаются среднее значение, отклонение и стандартное отклонение для затраченного времени и задействованной памяти компьютера.
Чтобы проделать это для всего интерфейса оболочек, написали такой код:
def run_all():
modules = [pl, pd] # set modules for checking
n = 30 # set number of repeats for getting stochastically better results
data_sets = data_model.get_datasets_defualt() # read our data
result = {} # an empty result
for m in modules: # let us iterate choosen modules
result[m.MODULE_NAME] = {} # an empty result for a single module
# print(m.MODULE_NAME)
for d in data_sets:
filename = os.path.basename(d)
result[m.MODULE_NAME][filename] = {}
# print(filename)
kw = {'path': d} # set dict for kwargs
open_res = run_many(n, m.open_csv, **kw) # check the open function
result[m.MODULE_NAME][filename]['open'] = open_res # save open res
data = m.open_csv(**kw) # and now let us read data properly, please
kw = {'data': data} # set dict with data for kwargs
result[m.MODULE_NAME][filename]['lines'] = m.lines(**kw) # save len of data
kw['col'] = data_model.col_name
gr_res = run_many(n, m.groupby, **kw) # check the groupby function
result[m.MODULE_NAME][filename]['groupby'] = gr_res # save groupby res
return result
if __name__ == '__main__':
res = run_all()
# print(res)
drawer.print_res(res)
В этом коде явно прописано, как проходится интерфейс оболочки, и как собираются kwargs под каждую функцию. Это не очень хорошо, уже настораживает. Но подождите.
Модуль data_model: пора поговорить о просчётах плана
В общем, на волне повсеместной объективизации и абстракции мы допустили одну существенную ошибку: попытались абстрагироваться от данных и от операций по отдельности. И у нас бы всё получилось, если бы данные не были по сути своей частью операции — по крайней мере, вещами одного порядка.
В самом начале рассуждения мы обозначали данные частью списка экспериментов. Наравне с операциями. Вот надо было их там и оставить, судя по всему)
Сейчас, на этапе сублимации опыта, угадывается мысль, что итерировать данные лучше было бы не из главного модуля, а из оболочек. Тогда составление разных оболочек было бы единственной формой вот этой регулярной модификации, о которой говорили в начале — а инвариант одинаковости данных в функциях (как и инвариант однозначности функций) соблюдался бы самим пользователем, который дописывает оболочки.

В общем, по итогу код, «владеющий» конкретикой данных, был вынесен в модуль data_model, основной код которого можно видеть ниже:
import os
col_name = 'review/score'
def get_flat_names(file_path, ext=None):
file_list = []
for item in os.listdir(file_path):
if not os.path.isfile(os.path.join(file_path, item)):
continue
if not ext or ext == 'all' or os.path.splitext(item)[1] != ext:
continue
file_list.append(os.path.join(file_path, item))
return file_list
Только вот это всё равно ничего особенно не спасает: изменяемая часть кода оказывается по разные стороны от нашего main, а значит, и менять его будет до определённой степени неудобно.
Так мы слоника не продадим. Но использовать имеющийся код до некоторой степени всё-таки можно.
Модуль drawer: или его эскиз
В модуле drawer мы реализовали отрисовку графиков. Работали частично из терминала Unix, и при первых попытках нарисовать что-нибудь обнаружилось, что из терминала нет возможности запускать фигуру matplotlib. Она всё-таки рисуется в графической оболочке, а терминал идентифицирует себя как kitty, у него лапки.
И хотя, в общем-то можно было решить это просто сохранением графика в файл, но для отладки нашли интересное решение – милую библиотечку uniplot, которая печатает довольно приятные графики прямо в консоль. Это несколько удобнее при отладке кода, а функционально получается почти то же самое.
По итогу код модуля drawer сейчас присутствует с вшитой uniplot, потом поменяем на хороший чёткий график matplotlib:
from uniplot import plot
def collect_ticks(result, key, *args):
sup_dict = {}
for filename, results in result[key].items():
l = int(filename.split('_')[1].split('.')[0])
sup_dict[l] = results[args[0]][args[1]][args[2]]
sup_keys = list(sup_dict.keys())
sup_keys.sort()
sup_ticks = []
for sup in sup_keys:
sup_ticks.append(sup_dict[sup])
return sup_ticks
def print_res(result):
key_rest = ['open', 'time', 'mean']
plot([sup_ticks_pd, sup_ticks_pl],
legend_labels = ['pandas', 'polars'],
lines = True)
Перебираем словарик, вылавливаем оттуда среднее время открытия по модулям Polars и Pandas. Сейчас от этого получается вот такой пиксельный график:
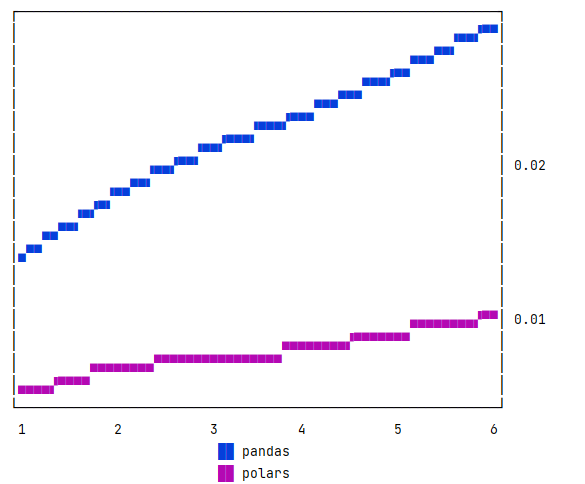
В общем, это вся реализация к текущему моменту времени. Подводя итоги первой итерации, стоит перечислить положительные и отрицательные итоги.
Положительные:
- предложен подход, который обнаруживает большую объективность, наглядность и воспроизводимость по сравнению с точечным бенчмарком, который применяется сейчас;
- подход реализован в коде, проверен на двух операциях, одной метрике и некоторых данных.
Отрицательные:
- допущена структурная ошибка (но, ошибка выявлена, мы её осознали и будем поправлять);
- текущая реализация отличается существенной прототипичностью – неполная реализация модулей-обёрток, эскизное состояние модуля drawer, использование графиков uniplot – все эти вещи не позволяют говорить о применении инструмента в текущей версии.
С полным кодом того, чего пока есть, вы можете ознакомиться в репозитории.
Выводы
Таким образом, в первой части публикации мы описали идею нашего будущего бенчмарка, выбрали данные для исследования, представили код и результаты первой версии практической реализации универсального инструмента.
О том, как мы «поднимем» Spark на локальном компьютере, переделаем структуру и добавим другие оболочки альтернатив, собираемся написать в следующей части публикации.
Спасибо за внимание, и, если у вас есть для нас советы/замечания/предложения, оставьте их, пожалуйста, в комментариях.