/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Основным элементом MPP в GreenPlum является Сегмент, который является — неделимой конфигурационной единицей в кластере GP и представляет из себя экземпляр сервера PostgreSQL. Именно сегменты производят чтение и запись данных. На одной ноде (физическом сервере) может находиться несколько сегментов. Разделение мощностей нод на сегменты необходимы для выравнивания производительности кластера и его масштабирования. Число сегментов на сервере зависит от его основных характеристик (число ядер ЦПУ, объема ОЗУ и размера дискового пространства). Все сегменты на Segment Host кластера имеют одинаковый объем оперативной памяти, размер доступного хранилища.
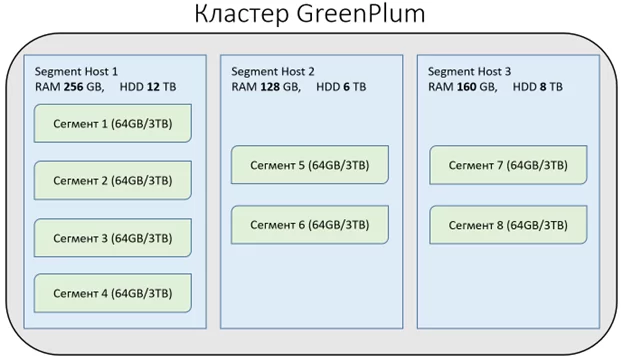
В примере кластера видно, как сегменты распределились по нодам в зависимости от ресурсов нод. Каждый сегмент резервирует часть ресурсов ноды.
В GreenPlum существует три способа распределения данных по сегментам кластера.
- Distributed replicated — копирование всех строк таблицы на каждый сегмент
- Distributed by — распределение данных по сегментам на основании указанного поля
- Distributed randomly – равномерное распределение данных по сегментам
Данные способы реализуются при создании таблиц в конструкции Create table.
create table table_distr_repl
(MY_ID integer,
MY_INT integer,
MY_DATE date,
MY_TEXT varchar(40)
)
distributed replicated;
--distributed by (MY_ID);
--distributed randomly;
Подробное сравнение способов сегментирования таблиц.
В качестве примера возьмем кластер из 228-ми сегментов. И таблицу из 10 млн строк.
Одно из полей содержит Уникальный ID “MY_ID integer”
- Занимаемое место:
distributed replicated -19 GB.*
distributed by (MY_ID) -97 MB.*
distributed randomly -97 MB.*
Как видим distributed replicated таблица заняла в сотни раз больше места из-за того, что все строки таблицы размещены на каждом из 228-ми сегментах.
* -расчет занимаемого места производился исходя из упрощения — не производится зеркалирования данных. Фактически таблицы будут занимать места в N раз больше, где N — это число зеркальных копий сегментов.
- Равномерность размещения данных:
distributed replicated Не распределяет данные по сегментам, а производит их копирование. В случае таких таблиц равномерность распределения по сегментам абсолютна.
distributed by (MY_ID) Распределяет данные по полю (MY_ID). В нашем случае значения данного поля являются равно-распределёнными. И распределение по сегментам, в этом случае, близко с абсолютному.
Выбор данного способа распределения накладывает ответственность за равномерность.
Для демонстрации создаем две таблицы (table_distr_by, table_distr_by2) и распределяем данные в них по полю (MY_ID).
В таблице table_distr_by в поле (MY_ID) разместим равнораспределённый идентификатор со значениями (1,2,3,4…), а в таблице table_distr_by2 тоже поле заполним одним значением (1) в каждой строке.
С помощью запроса выясним как распределились данные:
select count(1), gp_segment_id
from table_distr_by
group by gp_segment_id
order by gp_segment_id;
| count | gp_segment_id |
| 43540 | 0 |
| 43817 | 1 |
| 43756 | 2 |
| 43731 | 3 |
| 43758 | 4 |
| ….. | …. |
select count(1), gp_segment_id
from table_distr_by2
group by gp_segment_id
order by gp_segment_id;
| count | gp_segment_id |
| 10000000 | 171 |
Как видно в первом случае у нас сроки таблицы равномерно распределились по сегментам кластера, а во втором случае — все 10млн срок разместились на одном сегменте.
Не равномерно распределение строк по кластеру в случае с таблицей table_distr_by2 приведет к тому, что место на сегменте №171 закончится раньше, чем на остальных.
Представим, что пользователь создает таблицу, которая сегментирована по неравно распределённым значениям. В процессе заполнения такой таблицы появляется ошибка о том, что нет свободного места. Несмотря на то, что на кластере места в сотни раз больше. Если оставить такую таблицу на кластере, то на данный сегмент более не получится записать данные.
distributed randomly Распределяет строки поровну между всеми сегментами.
select count(1), gp_segment_id
from table_distr_rand
group by gp_segment_id
order by gp_segment_id;
| count | gp_segment_id |
| 43801 | 0 |
| 43887 | 1 |
| 43889 | 2 |
| 43839 | 3 |
| 43801 | 4 |
| ….. | …. |
Как видим, данные распределились равномерно. Незначительное отклонение в распределении связанно кратностью числа строк таблицы с количеством сегментов и особенностей работы алгоритма распределения.
Если вычислить среднее отклонение всех значений поля от count от 43 859 то получим 0.1%.
Получается, что 99.9% строк будут читаться и записываться одновременно всеми сегментами.
- Сравнение скорости записи
| Таблица | Способ сегментирования | Особенность | Время загрузки (insert) 100 млн строк в миллисекундах |
| table_distr_repl | distributed replicated | — | 5061 |
| table_distr_by | distributed by | Сегментировано по равно распределённому значению поля (MY_ID) | 3197 |
| table_distr_by2 | distributed by | Неэффективное сегментирование по полю (MY_ID) (все строки на одном сегменте) | 5331 |
| table_distr_rand | distributed randomly | — | 3002 |
- Сравнение скорости запросов к таблицам.
Запросы без условий
Select *
From
table_distr_repl
limit 10000;
| Таблица | Способ сегментирования | Особенность | Время загрузки (insert) 100 млн строк в миллисекундах |
| table_distr_repl | distributed replicated | — | 1703 |
| table_distr_by | distributed by | Сегментировано по равно распределённому значению поля (MY_ID) | 344 |
| table_distr_by2 | distributed by | Неэффективное сегментирование по полю (MY_ID) (все строки на одном сегменте) | 1624 |
| table_distr_rand | distributed randomly | — | 187 |
Запросы с условиями
Select *
From
table_distr_repl
where my_text like ‘%441%’
and my_id >= 4000000
and my_id < 5000000;
| Таблица | Способ сегментирования | Особенность | Время работы запроса в миллисекундах |
| table_distr_repl | distributed replicated | — | 3109 |
| table_distr_by | distributed by | Сегментировано по равно распределённому значению поля (MY_ID) | 1969 |
| table_distr_by2 | distributed by | Неэффективное сегментирование по полю (MY_ID) (все строки на одном сегменте) | 3110 |
| table_distr_rand | distributed randomly | — | 375 |
Запросы с JOIN
Далее производим 9 измерений, связывая между собой сегментируемые тремя способами таблицы.
Select t1.*, t2.my_id as my_id2
From
“Таблица 1” t1 Left join “Таблица 2” t2
On t2.my_id = t1.my_id
where my_text like ‘%c10%’;
| Таблица 1 | Способ сегментирования | Время соединение с таблицей 2 table_distr_repl в миллисекундах | Время соединение с таблицей 2 table_distr_rand в миллисекундах | Время соединение с таблицей 2 table_distr_rand в миллисекундах | Число строк |
| table_distr_repl | distributed replicated | 10734 | 8438 | 6032 | 444444 |
| table_distr_by | distributed by | 6859 | 9078 | 1328 | 444444 |
| table_distr_rand | distributed randomly | 21891 | 9063 | 1891 | 444444 |
Сравнение производительности запросов было проведено в условиях исключающий использования HASH данных. В случаях, когда производился JOIN между таблицами с идентичным способом сегментирования создавалась вторая таблица с тем-же набором данных.
Для исключения влияния нагрузки на результат тестирование производилось 3 раза. Во всех случаях отклонения во времени выполнения одного и того-же запроса составляла не более 5%
Встроенный в GreenPlum анализатор запросов и план запросов даёт исчерпывающую информацию о задействованных сегментах и переносах данных между ними. Показатель стоимости запроса COST представляет из себя диапазон значений (пример 126172..464844), разброс которых не позволяет произвести точную оценку эффективности запроса. По этой причине для сравнения запросов использовалось время его выполнения.
Для наглядности нормализуем результаты в процентах от максимального значения. Где минимальное значение – лучший результат.
| Способ сегментирования | Время записи % | Время чтения без условий % | Время чтение с условиями % | Время чтение с JOIN % |
| distributed replicated | 100,00 | 100,00 | 100,00 | 100 |
| distributed by | 63,17 | 20,20 | 63,33 | 63,37 |
| distributed randomly | 59,32 | 10,98 | 12,06 | 95,54 |
Выводы.
Использование distributed replicated не оправдано. Занимает избыточно много места на диске. Долго записывается и читается, медленно связываются с другими таблицами. Единственный плюс заключается в том, что данные равномерно распределяются по кластеру.
Использование distributed by оправдано, когда заведомо знаем по каким полям данная таблица будет связываться с другими таблицами. И в этом случае связывание покажет наилучшие результаты. Минусом является возможность неравномерного размещения данных на кластере.
Использование distributed randomly оправдано в большинстве случаев. Его легко использовать, так как не нужно указывать поля, по которым будет проходить сегментация. Данные равномерно распределяются по сегментам и не занимают лишнего места.