/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Крупные корпорации предъявляют большие требования к хранению и скорости обработки больших объемов данных. Так, для работы с информацией, хранящейся на серверах Hadoop, разработана система управления базами данных Hive. Включает в себя SQL-подобный язык HiveQL, разработанный с учетом масштабируемости и легкости использования. Однако Hive нельзя назвать эффективной в потоковой обработке данных. Причиной тому являются особенности MapReduce, не позволяющие выполнять сложные запросы в режиме реального времени. Таким образом, запрос даже небольших объемов данных может занять минуты. Оптимизация запросов позволяет достичь существенного увеличения производительности. Рассмотрим подробнее.
1. Модель данных Hive
Модель данных Hive представлена следующим образом:
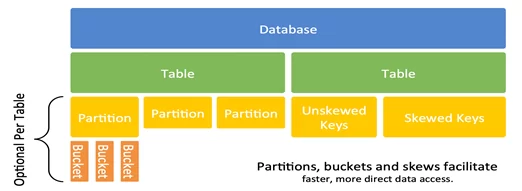
В Hive база данных, как и классические РСУБД, включает в себя таблицы, индексы, связи. Отличительная особенность hive-таблиц заключается в способе хранения: таблицы хранятся в виде обычных файлов на HDFS. Hive-таблицы различают двух типов:
- Внутренние таблицы наполняются данными посредством HiveQL-запроса после создания. Такие таблицы используются для работы с временными данными или при необходимости управления жизненным циклом данных.
- Внешние таблицы, в которые данные загружаются из внешних источников (csv, txt и т.д.) во время создания. Таблицы необходимы для взаимодействия с данными, которые необходимо сохранить в неизменном виде, расположенные вне пространства Hive, к которым также может обращаться стороннее ПО и т.д.
Для доступа к определенным данным Hive-таблицы обычно происходит полное сканирование данных, что существенно замедляет процесс получения необходимого результата. Для избежания полного сканирования и ускорения работы по получению нужных данных, на помощь приходит партиционирование (partitioning) таблицы, то есть становится возможным обращаться к конкретным данным напрямую без необходимости перебора остальных данных.Partitioning в Hive означает разделение таблицы на несколько частей на основе значений определенного столбца, например даты, города или страны. Преимущество разделения заключается в сокращении времени ответа на запрос за счет хранения данных (партиций) в отдельных директориях. Для создания партиций необходимо включить настройки:

Партиции могут быть созданы как по выбранным значениям, так и по значениям всего столбца:
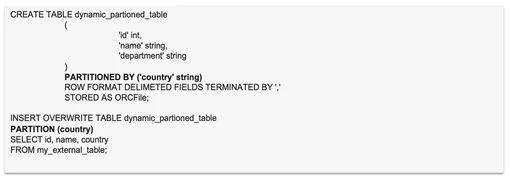
Число партиций следует ограничивать. Не рекомендуется использовать более 1000.
Bucketing в Hive подразумевает разделение данных на диапазоны, которые известны как buckets (сегментов или бакетов), чтобы придать данным дополнительную структуру для более эффективных запросов. Диапазон для bucket определяется хеш-значением одного или нескольких столбцов в наборе данных. Особенно полезен при использовании Joins.

Возможность создания buckets необходимо явно отображать в настройках:

SkewedTables в Hive позволяет явно указать значения с перекосом в данных. Hive разделит значения с перекосом и все остальные в разные файлы физически:

Для достижения наилучших c Partitioning и Bucketing можно использовать совместно. Следует использовать одинаковые подходы Partition / Bucket для соединяемых таблиц.

Таким образом, Hive позволяет довольно быстро обрабатывать большие массивы данных, что делает его весьма полезным средством для работы с Big Data.
2. Стратегии Join Hive
Оптимизация операций JOIN в Hive одна из приоритетных задач, также является главной составляющей некоторых алгоритмов оптимизации, например Cost Based Optimization. Оптимизация операций JOIN в Hive одна из приоритетных задач, также является главной составляющей некоторых алгоритмов оптимизации, например Cost Based Optimization. Поэтому понимание стратегий JOIN является важнейшим элементом управления производительностью HiveQL. Рассмотрим различные типы JOIN подробнее:
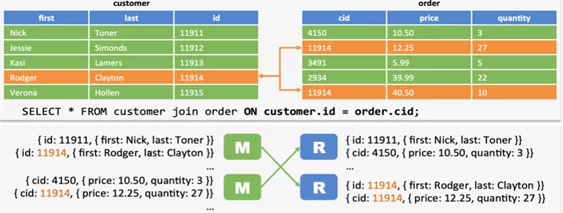
- Shuffled join используется по умолчанию. В этой стратегии JOIN включает в себя этапы map и reduce. Mapper считывает таблицы, и выводит пары ключ-значение соединения в промежуточный файл. После этого пары сортируются. Reducer получает отсортированные данные и выполняет JOIN.
BroadcastJoin (или Map Side Join) применяется, если одна или несколько таблиц малы настолько, чтобы поместиться в памяти. Тогда mapper сканирует большую таблицу и выполняет объединение. Для использования необходимо установить:
hive.auto.convert.join = true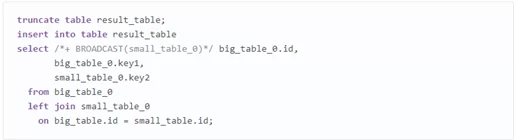
В Sort-Merge-Bucket Join объединение выполняется на этапе map. К таблицам применяется Bucketing. Mapper обработки первого сегмента для таблицы customer будет получать только первый сегмент из order. Таблицы отсортированы.

Описанные выше способы обращения к таблицам и применение нужного сценария JOIN для решения конкретных задач позволят существенно повысить производительность запросов в Hive. Помимо этого существуют утилиты для оптимизации, которые мы рассмотрим в следующем пункте. Однако их применение не заменяет необходимости написания «хороших» запросов.
3. Оптимизация Hive
Рассмотрим основные алгоритмы оптимизации, которые Hive предлагает использовать.
Tez – это расширяемая open-source платформа создания высокопроизводительных приложений пакетной и интерактивной обработки данных. Tez развивает парадигму MapReduce, увеличивая ее скорость и сохраняя способность масштабироваться до огромных размеров. Для использования включаем настройки Tez:
set hive.optimize.index.filter=true;
set hive.fetch.task.conversion=more;
set hive.compute.query.using.stats=true;
Векторизация (Vectorization) запросов существенно увеличивает скорость выполнения операторов scans, joins др., выполняя их сегментами по 1024 строки. Для использования векторизации подключаем настройки:
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
Построение выполнения запроса «по умолчанию» не применяет оптимизацию по стоимости запроса. CostBasedOptimization (CBO) позволяет выполнять последующую оптимизацию на основе стоимости запроса, которая влечет за собой определенные решения, например, изменение порядка JOIN, степень параллелизма и другие. Для использования CBO включаем настройки:
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
Далее необходимо подготовить данные, собрав различные параметры статистики по тем таблицам, где хотим применить CBO.
analyze table table_name compute statistics;
-- or as example:
analyze table tweets compute statistics for columns sender, topic;
-- or after Hive 0.14:
analyze table tweets compute statistics for columns;
Выполнение запроса с использованием данной таблицы должно привести к другому, более быстрому, плану выполнения. Кроме того, посмотрев его с помощью оператора EXPLAIN, добавленного перед запросом, можно сократить время выполнения, и уменьшить использование ресурсов.
Поскольку Hive хранит данные в виде файлов HDFS, то знание форматов, поддерживаемых указанной файловой системой, поможет оптимизировать работу по их обработке. ORCFile – колоночно-ориентированный формат хранения Big Data в экосистеме Hadoop. Этот формат обладает высокой скоростью работы с файлами и высокой степенью сжатия. Данные в ORC хранятся в виде колонок. Для обеспечения скорости потокового чтения файл разбит на так называемые «страйпы» (stripes), каждый страйп является самодостаточным, т.е. может быть прочитан отдельно (а, следовательно, параллельно).
Live Long And Process (LLAP) является механизмом выполнения под управлением Hive. LLAP использует одни и те же ресурсы для кэширования и обработки. Этот механизм в результате дает ответ с очень низким временем задержки, так как не тратится время на запуск запрашиваемых ресурсов. Hive LLAP используется для работы с Big Data, в частности, для выполнения долгих или тяжелых запросов с множеством JOIN.
4. Типовые ошибки при использовании Hive
Рассмотрим типичные ошибки при работе с Hive, которые снижают производительность:
- Запуск HiveQL-запросов и spark-приложений с параметрами по умолчанию приводит к резервированию всех доступных ресурсов кластера. Для ограничения используемых ресурсов следует установить параметр максимального количества запущенных mapper и reducer, например:
set mapreduce.job.running.map.limit=6;
set mapreduce.job.running.reduce.limit=6;
- Одновременный запуск пользователем более одного приложения;
- Принудительное завершение процессов не всегда очищает временные файлы в домашних директориях пользователей (~/.staging, ~/.sparkStaging);
- Удаление файлов из HDFS без параметра –skipTrash переносит данные в каталог ~/.Trash, фактически не освобождая место;
- Некорректное завершение spark-приложений без вызова sc.stop() не освобождает ресурсы кластера;
- Некорректное завершение работы в JupyterHub путем закрытия вкладки в браузере не останавливает процесс Jupyter, занимая RAM на ноде.
Используя представленные методы оптимизации запросов мы можем увеличить производительность в несколько раз, что при работе с большими объёмами данных весьма существенно. Для получения наилучших результатов необходимо варьировать методы оптимизации в зависимости от исходной задачи. Например, партиционирование таблиц и использование ORC-файлов в значительной степени повысит производительность даже простого SELECT.
В заключении отметим, что помимо применения алгоритмов оптимизации запросов, немаловажную роль в повышении производительности играют подготовка данных, «хороший» код запросов и отсутствие типовых ошибок при работе с Hive.