/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Начнём с Broadcast Hash Join. Допустим, нам необходимо объединить два датасета разной величины. Меньший по объему содержит выборку из штата сотрудников appdf, другой – всю клиентскую базу организации clientdf.
appdf=spark.createDataFrame([(1,'a')],['id','name'])
clientdf=spark.createDataFrame([(1,'a')],['id','name'])Необходимо оставить всех старших продавцов и добавить к каждому обслуженных им клиентов.
Почему нам предпочтительнее использовать Broadcast Hash Join? Этот оператор необходим при неравномерной статистике распределения данных, например, при присоединении входных датасетов разной величины.
Для начала нам нужно собрать статистику по имеющимся датасетам. Для этого используем команду analyze table. После проверим её в Hive командой show create table.
analyze table our_scheme.appdf compute statistics;
analyze table our_scheme.clientdf compute statistics;
show create table our_scheme.appdf;
show create table our_scheme.clientdf;
В конце описания появятся следующие свойства:
‘spark.sql.statistics.numRows’
‘spark.sql.statistics.totalSize’
Зная размеры используемых датасетов, можем применить Broadcast Hash Join. В нашем случае необходимо указать хинт (подсказку) /*+BROADCAST(s)*/ (s – псевдоним меньшего датасета).
select /*+BROADCAST(s)*/ *
from our_scheme.clientdf as b
left join our_scheme.appdf as s
on b.id = s.id
Однако подсказка не требуется, если левый датасет является широковещательным и тип соединения – Right Outer, Right Semi или Inner, и наоборот правый датасет является широковещательным и тип соединения – Left Outer, Left Semi, Inner.
Для использования Broadcast Hash Join необходимо наличие достаточного объёма памяти для размещения данных. В случае, если оба датасета большие и превышают выставленный лимит, Spark попытается избежать данного сценария.
Рассмотрим сценарий работы Broadcast Hash Join. Чтобы присоединить маленький набор данных к большому он транслирует меньший датасет не порционально каждому ноду по ключу, а целиком на все ноды в кластере.
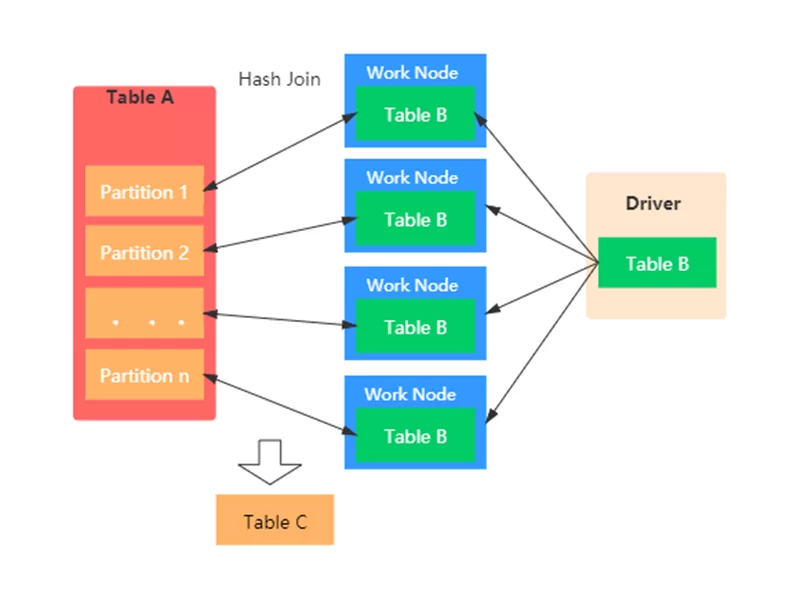
К условиям использования Broadcast Hash Join также можно отнести:
- Эквивалентные условия (эквивалентное условие должны выполняться одновременно, а неэквивалентное нет);
- Не применимо к типу соединения Full Outer Join;
- Использование хинта /*+BROADCAST(s)*/.
Также стоит упомянуть, что Broadcast Hash Join будет по умолчанию применяться Spark, если соблюдены условия его использования. Поэтому, если вам потребуется иной Join, будет необходимо изменить параметр spark.sql.autoBroadcastJoinThreshold, который используется для корректировки максимального размера (в байтах) широковещательного набора, на значение 0 или любое отрицательное.
Далее поговорим о Sort Merge Join. Например, нам необходимо объединить два датасета с сотрудниками и их рабочими местами, а затем отсортировать по определенному идентификатору, который и будет являться ключом их соединения.
select /*+MERGE(fr)*/ *
from our_scheme.appdf as fr
join our_scheme.placedf as sc
on fr.id = sc.idРабота Sort Merge Join начинается с операции перемешивания для соответствия обоих датасетов сценарию партицирования (то есть разделения). Затем происходит сортировка, а далее – слияние отсортированных данных.
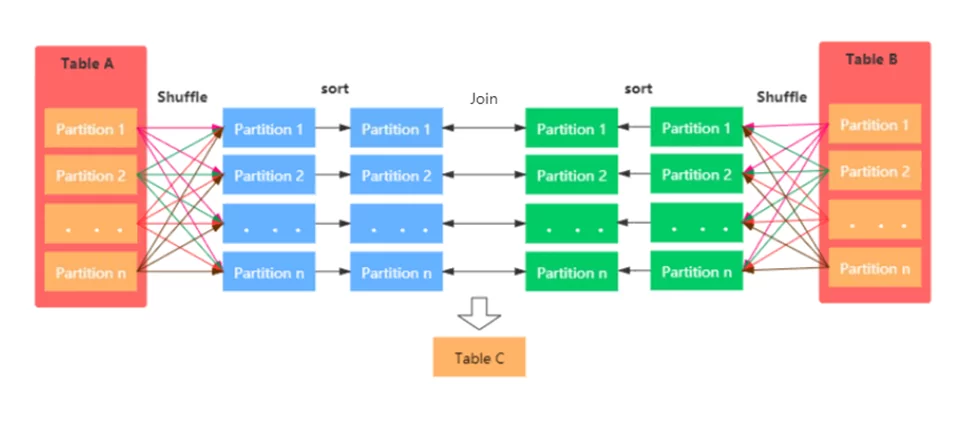
Условиями использования Sort Merge Join являются:
- Эквивалентные условия;
- Возможность отсортировать ключ объединения;
- Значение ‘spark.sql.join.prefersortmergeJoin’ должно быть равно true;
- Использование хинта /*+MERGE(fr)*/.
Перейдём к механизму Shuffle Hash Join. Он применяется, если настойка выбора Sort Merge Join отключена, а ключ не отсортировывается. К примеру, нам необходимо объединить списки клиентов и их документов.
select /*+SHUFFLE_HASH(с)*/ *
from our_scheme.clientdf as c
join our_scheme.docdf as d
on c.id = d.id
Первым шагом работы Shuffle Hash Join является перемешивание. Далее из транслируемого набора данных строится хеш-таблица меньшего датасета, а затем соответствующая часть большого набора данных присоединяется к сформированной ранее хеш-таблице.
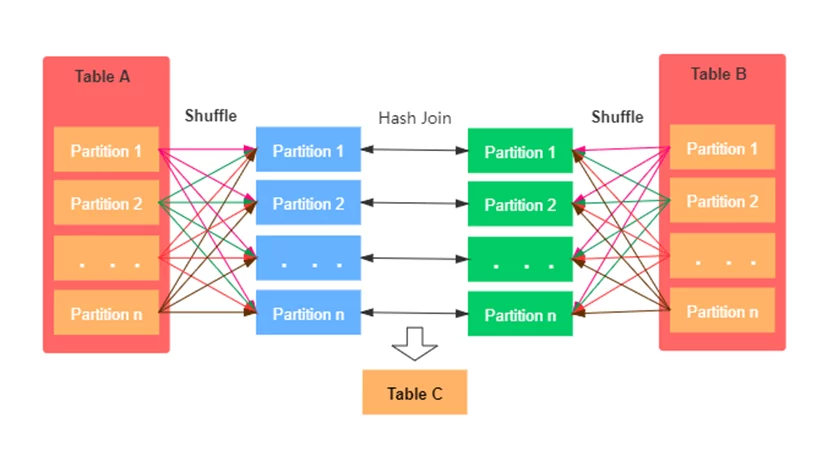
К условиям использования Shuffle Hash Join относятся:
- Эквивалентные условия;
- Не применимо к типу соединения Full Outer Join;
- Значение ‘spark.sql.join.prefersortmergeJoin’ должно быть равно false;
- Использование хинта /*+SHUFFLE_HASH(fr)*/.
Подсказка не требуется, если левый датасет меньше и тип соединения – Right Outer, Right Semi или Inner, и наоборот правый датасет меньше и тип соединения – Left Outer, Left Semi, Inner. А также в случае, когда оба набора довольно малы, можно использовать любой из перечисленных выше типов соединения.
Рассмотрим преимущества и недостатки каждого из трёх рассмотренных нами видов:
| Вид | Преимущество | Недостаток |
| Broadcast Hash Join | Работает быстро, операция перемешивания не требуется | Необходимо наличие достаточного объёма памяти |
| Sort Merge Join | Работает быстро для наборов данных любых размеров | Данные должны быть отсортированы |
| Shuffle Hash Join | Работает независимо от размера входных данных | Самый ресурсоемкий и медленный вид |
Подведем итог нашей статьи. Для того, чтобы эффективно применять операции соединения в Spark, необходимо знать основные аспекты их использования:
- Размер используемых датасетов;
- Условие соединения: эквивалентное и неэквивалентное;
- Тип соединения (Inner Join, Outer Join и т.д.).
Знание подсказок Join и условий использования того или иного сценария соединения полезно для оптимизации сложных операций, для поиска первопричин некоторых ошибок нехватки памяти и для повышения производительности поисковых запросов.