/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 2 мин.
При исполнении DML запросов (update, insert, delete) СУБД ограничивает доступность данных для других процессов, блокируя строки, до завершения транзакции. Эта особенность приводит к снижению производительности при большом количестве запросов и одним и тем же данным. Из-за этого происходит «тупиковая ситуация» БД, а именно 2 запроса обращаются к идентичным таблицам.
Hint nolock:
- позволяет SQL считывать строки таблиц, исключая блокирование остальными запросами;
- может повысить производительность и вводит возможность «Грязного чтения» (Dirty read). Dirty read позволяет считывать данные без учета действующих запросов и наложенных блокировок на таблицы.
Однако при использовании «грязного чтения» присутствуют как позитивные, так и негативные моменты.
Из положительных сторон можно отметить повышение производительности (пример ниже).
Мы имеем таблицу [TB54_SANDBOX].[dbo].[test] в которой ровно 10 000 000 записей.
Запускаем запрос на выборку количества записей в таблице:
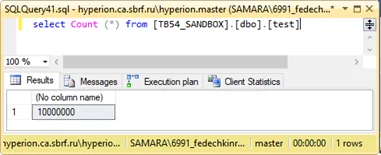
Получаем время отработки запроса в 1 сек.
А теперь, перед запуском запроса, в параллельной вкладке, запускаем update:
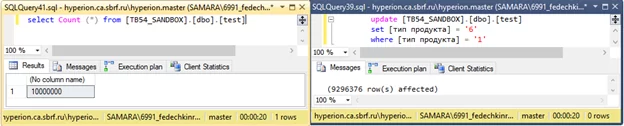
В результате видим, что ко времени исполнения запроса на выбор строк (select) прибавилось время на update таблицы.
Пишем «nolock» и видим совершенно другое время на отработку:
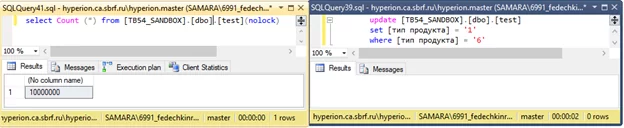
Из минусов использования nolock при параллельном обновлении таблицы запрос может возвращать неверные результаты, а именно:
- видеть строки дважды;
- пропустить строки;
- видеть данные, которые не были зафиксированы;
- запрос может быть завершен с ошибкой (невозможно продолжить сканирование без блокировки из-за перемещения данных).
Исправить данные недостатки довольно просто:
- создать индекс на таблице;
- использовать другой уровень изоляции.