/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В этой статье мы будем рассматривать 2 различных запроса, в которых индексы не используются оптимизатором, но могут быть использованы, если изменить запрос. Далее будет описание механизма работы TSQL, и почему небольшое изменение кода даст положительный эффект. Наконец, мы выполним настройку запросов в SQL Server, чтобы увидеть, насколько можно улучшить производительность.
В статье будут использованы термины, которые могут быть новыми для читателей.
Аргумент – иначе говоря это логическое выражение, которое может быть в предикате join, выражений WHERE или выражений HAVING. Каждое из этих выражений может иметь множество аргументов в сочетании с AND и OR. Аргумент может быть «OrderDate = GETDATE()» или «ExtendedPrice > 100».
Просмотр индекса (Index Scan) – оператор получает все записи некластеризованного индекса, указанного в столбце Аргумента и читает весь индекс в поисках совпадений. Время исполнения пропорционально размеру индекса.
Поиск индекса (Index Seek) – оператор использует возможности поиска по индексам для строк из некластеризованного индекса и использует структуру дерева индекса для прямого поиска подходящих записей. Время исполнения пропорционально количеству совпадающих записей. Столбец Аргумента содержит имя используемого некластеризованного индекса.
Иногда запросы MS SQL выполняется медленно. Несмотря на то что фильтрация (выражение WHERE) производится по индексированным столбцам, в плане запроса производится «просмотр индекса» (Index Scan), а не «поиск индекса» (Index Seek). Почему так происходит?
Вызов функций в аргументах — это наиболее распространенная причина, по которой аргументы не доступны для поиска индекса. Рассмотрим запрос по выбору счетов-фактур, датированных в течение 5 дней с 1 июня 2016 года.
SELECT InvoiceDate FROM Sales.Invoices WHERE DATEDIFF(dd, InvoiceDate, '6/1/2016') <= 5;Посмотрим на план запроса, чтобы убедиться, что SQL Server выполняет «просмотр индекса» (Index Scan), т.е. не видит индекс, который ускорит запрос. Перед выполнением скрипта включаем план выполнения — Ctrl+M.
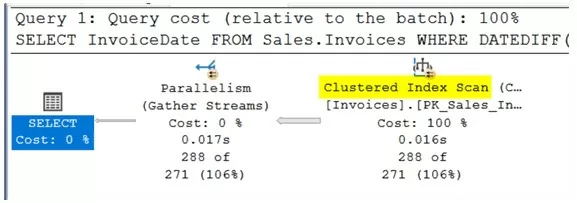
Действительно, колонка InvoiceDate из выражения WHERE не ищет индекс. Давайте посмотрим на индексы в этой таблице.
exec sp_helpindex[Sales.Invoices]Ниже приведены индексы продаж. Таблица счетов-фактур.
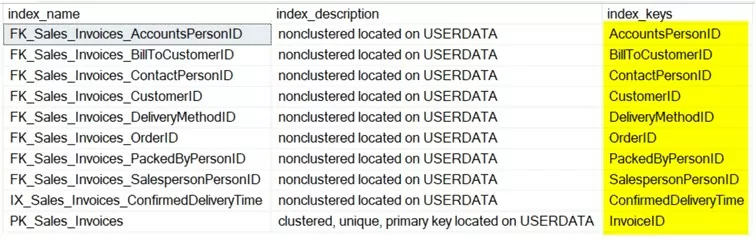
В InvoiceDate нет индекса, поэтому создадим индекс и выполним запрос снова.
CREATE INDEX mssqltips on Sales.Invoices(InvoiceDate)В результате, оптимизатор действительно использовал индекс, но сканировал его, а не выполнял предпочтительную операцию «поиск в индексе» (Index Seek).
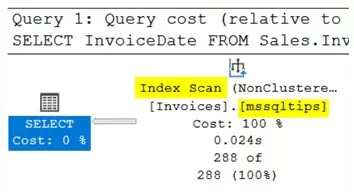
Чтобы понять, почему так происходит, запрос будет выполнен еще раз с дополнительным столбцом в операторе SELECT.
SELECT InvoiceDate, DATEDIFF(dd, InvoiceDate, '6/1/2016')
FROM Sales.Invoices
WHERE DATEDIFF(dd, InvoiceDate, '6/1/2016') <= 5;
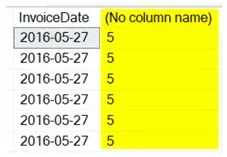
Обратите внимание, что аргумент в предложении WHERE сравнивает число 5 с результатом операции DATEDIFF. Когда операция DATEDIFF помещается в SELECT запроса, он создает новый столбец, который не имеет имени. В то время как столбец InvoiceDate индексируется, новый безымянный столбец, образованный во время выполнения запроса, не индексируется. Кроме того, новый столбец не может быть проиндексирован, так как он вычисляется во время выполнения запроса. Вот почему аргумент не доступен для поиска и поэтому происходит «просмотр индекса» (Index Scan).
Путь решения данной проблемы заключается в том, чтобы удалить функции из столбца, в котором выполняется поиск.
Альтернативная версия запроса должна выводить тот же результат, но сравнивает InvoiceDate со значением, которое ядро SQL Server может вычислить только один раз в начале запроса, а не один раз для каждой строки таблицы.
SELECT InvoiceDate FROM Sales.Invoices WHERE InvoiceDate >= DATEADD(dd, -5, '6/1/2016');При выполнении этого запроса выполняется операция поиска в новом индексе.
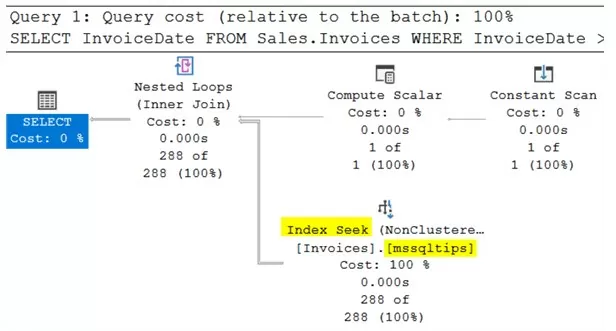
Для сравнения производительности двух запросов, включим статистические опции:
SET STATISTICS IO ON
SET STATISTICS TIME ON
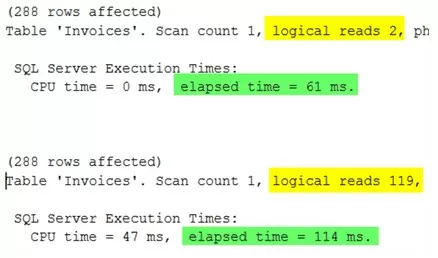
После выполнения, во вкладке «Сообщения» появится информация. Запрос сверху — это новая версия с доступным для поиска аргументом, а запрос снизу — не исправленный запрос, который в 60 раз больше считывает и 2 раза дольше исполняется.
Рассмотрим еще один запрос, ищущий человека, имя которого начинается с букв «IVA». Обычный способ написать подобный запрос — сопоставить первые 3 символа значений колонки с «IVA», как показано ниже.
SELECT PersonID, FullName
FROM [WideWorldImporters].[Application].[People]
WHERE LEFT(FullName, 3) = 'Iva'
Точно так же, как и в приведенном выше запросе, новообразованный столбец, основанный на функции LEFT, не индексируется. SQL Server так же будет сканировать и не видеть индекс.
Лучший способ написать этот запрос — использовать оператор LIKE. Хотя идея использования оператора LIKE для повышения производительности может показаться противоречивой, LIKE все равно позволит искать до тех пор, пока поиск значений, удовлетворяющих LIKE может быть оптимизирован с помощью сортировки.
В следующем запросе это изменение реализовано.
SELECT PersonID, FullName
FROM [WideWorldImporters].[Application].[People]
WHERE FullName LIKE 'Iva%'
В случае поиска символов следующим образом: WHERE FullName LIKE ‘%Iva%’ сортировка уже будет не возможна.
Выполнение двух запросов в непосредственной последовательности с включенными планами запросов покажет следующий результат.
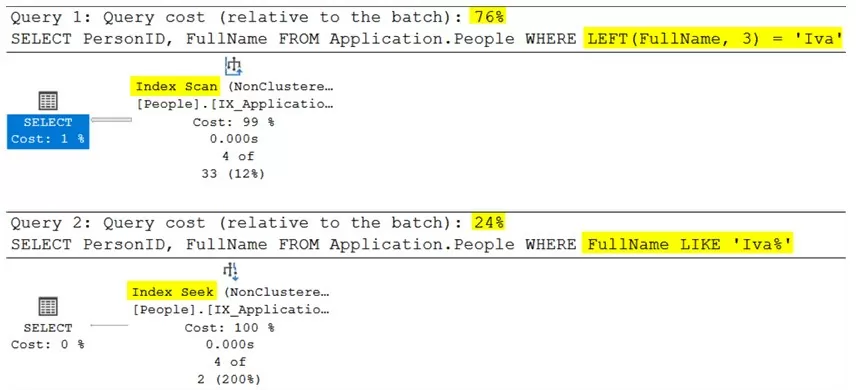
Обратите внимание, как первый запрос с функцией LEFT в предложении WHERE выполняет сканирование, в то время как второй запрос с LIKE выполняет поиск. Оптимизатор полагает, что подобная версия запроса примерно в 3 раза быстрее, чем версия c LEFT.
Вывод
При написании кода TSQL необходимо учитывать, доступны ли для поиска (Index Seek) аргументы в предикатах join, WHERE и HAVING. Наиболее распространенной причиной является использование функций, требующих ввода столбца.
Пользовательские функции также являются проблемными и часто гораздо хуже, поскольку они редко компилируются изначально и работают даже медленнее, чем встроенные функции, которые были показаны в этих демонстрационных запросах. Это означает, что наряду с невозможностью использовать индекс запрос будет еще больше замедляться самой функцией!