/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Введение
При формировании запросов с составным индексом нужно обращать внимание на логику выстраивания технической схемы поиска так же, как и в случае работы с обычными полями. Забегая вперёд, нужно сразу отметить, что полноценное и корректное использование составного индекса будет реализовано только в случае запроса по стартовым позициям таблицы, т.е. самым верхним/левым столбцам индекса.
Для того чтобы лучше разобраться в логике работы запросов, предлагаю рассмотреть несколько вариантов поиска на примерах.
Таблицу создадим заранее, со стандартным наполнением данных, часто встречающихся в сфере продаж:
Сам скрипт будет выглядеть следующим образом:
USE TB70_SANDBOX
GO
--Создаём тестовую таблицу
CREATE TABLE dvb.CompositIndex_TEST ( --"dvb" - схема, "CompositIndex_TEST" - Название таблицы
Id INT IDENTITY(1,1) NOT NULL,
NAME0 VARCHAR(50), --столбец с именем "NAME" лучше не использовать =) !По тексту буду называть полем "NAME"
SURNAME VARCHAR(50),
Mobile VARCHAR(10),
Email VARCHAR(50),
DateUpdate DATETIME
)
GO
--Заливаем в таблицу 1млн. рандомных записей.
--Они нужны нам только для реалистичности поиска, не более
INSERT INTO dvb.CompositIndex_TEST (NAME0, SURNAME, Mobile, Email, DateUpdate)
SELECT TOP 1000000 REPLACE(NEWID(),'-',''), REPLACE(NEWID(),'-',''),
CAST( CAST(ROUND(RAND(CHECKSUM(NEWID()))*1000000000+4000000000,0) AS BIGINT) AS VARCHAR(10)),
REPLACE(NEWID(),'-','') + '@gmail.com',
DATEADD(HOUR,CAST(RAND(CHECKSUM(NEWID())) * 19999 as INT) + 1 ,'2006-01-01')
FROM sys.all_columns c1
CROSS JOIN sys.all_columns c2
GO
--Добавляем ещё одну запись, которую мы и будем использовать для эксперимента
UPDATE dvb.CompositIndex_TEST
SET NAME0 = 'Ivan',
SURNAME = 'Petrov',
Mobile = '9246402424',
Email = 'ivan_petrov@gmail.com'
WHERE Id = 100000
GO
--Создаём Первичный ключ (Primary Key/PK) и Кластерный индекс (Clustered Index/CI) для столбца "Id"
ALTER TABLE dvb.CompositIndex_TEST
ADD CONSTRAINT PK_Customers_Id
PRIMARY KEY CLUSTERED (Id)
GO
Реализация составного некластеризованного индекса для столбцов NAME и SURNAME
Для изучения подходов поиска, создадим некластеризованный индекс в столбцах NAME и SURNAME, по скрипту ниже:
--Создадим некластеризованный индекс для столбцов NAME0 и SURNAME
CREATE NONCLUSTERED INDEX IX_Customers_NAME0_SURNAME
ON dvb.CompositIndex_TEST (NAME0, SURNAME)
GO
Заранее включаем в Sql Server Management Studio план выполнения, либо на панели инструментов, либо сочетанием Ctrl + L.
Настало время заняться экспериментом и узнать, как порядок столбцов в приведенном выше составном индексе влияет на его использование для запросов к этой таблице.
Пример №1: Порядок столбцов NAME и SURNAME как в таблице
Выполняем запрос
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST WITH (nolock)
WHERE NAME0 = 'Ivan' AND SURNAME = 'Petrov'
И смотрим план выполнения запроса

В этом примере видим, что поиск прошёл полностью по составному индексу. Для большинства задач этот результат можно признать эталонным.
Пример №2: Обратный порядок столбцов. Сначала SURNAME, затем NAME
Выполняем запрос
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST
WHERE SURNAME = 'Petrov' AND NAME0 = 'Ivan'
Сверяемся с планом выполнения

Результат ничем не отличается от 1-ого примера. Хорошо, двигаемся дальше…
Пример №3: Запрос только по столбцу NAME
Выполняем запрос
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST WITH (nolock)
WHERE NAME0 = 'Ivan'
И что же получилось?

Запрос по одному из столбцов составного индекса тоже не повлиял на производительность запроса. Теперь попробуем выполнить запрос по второму столбцу составного индекса и будем подводить итоги.
Пример №4: Запрос только по столбцу SURNAME
Выполняем запрос
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST WITH (nolock)
WHERE SURNAME = 'Petrov'
Уже по привычке смотрим, что получилось в плане выполнения:
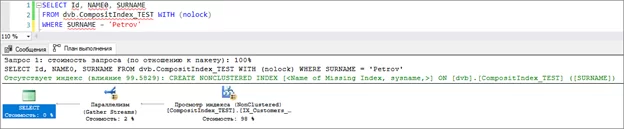
А вот это уже интересно! Видно, что запросу не хватило данных, чтобы пройти только по индексному полю и было предложено сделать его индексным отдельно.
ИТОГИ: Проверяем стоимости всех запросов
Для наглядности выполним все 4 запроса из примеров в одном
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST WITH (nolock)
WHERE NAME0 = 'Ivan' AND SURNAME = 'Petrov'
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST
WHERE SURNAME = 'Petrov' AND NAME0 = 'Ivan'
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST WITH (nolock)
WHERE NAME0 = 'Ivan'
SELECT Id, NAME0, SURNAME
FROM dvb.CompositIndex_TEST WITH (nolock)
WHERE SURNAME = 'Petrov'
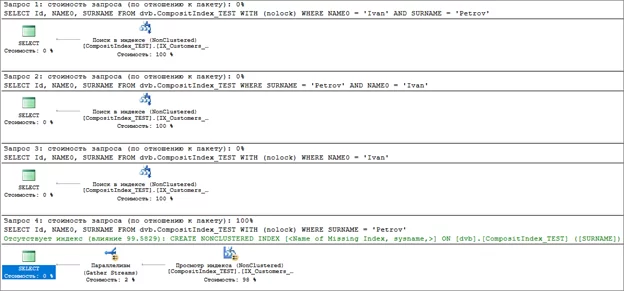
Казалось бы, какая разница!? Но она есть и достаточно ощутимая. Время сделать простой вывод.
Вывод:
Опытным путём удалось разобраться, как Sql Server интерпретирует запрос в составном индексе. Эталонная отработка запроса будет возможна только в том случае, если при сокращении количества индексов в запросе будут присутствовать ведущие столбцы, а именно стоящие в левом положении по отношению к остальным. Это важно учитывать, когда столбцы содержат не Имя и Фамилию (как в нашем примере) и изначально занимают стартовую позицию, а участвуют, как ключ, после объединения нескольких СУБД или, ввиду других исторических особенностей используются столбцы, «раскиданные» по таблице.
В примере отлично видно, что в случае использования столбца, не стоящего в авангарде составного индекса, цена запроса увеличивается кратно, а во многих проектах, это может быть критической проблемой, которую многие могут проигнорировать.