/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
При формировании витрин данных и датасетов в экосистеме Hadoop одним из важных вопросов является выбор оптимального способа хранения данных в hdfs. В частности, в рамках данной публикации будет рассматриваться один из важных вопросов при создании витрины – выбор соответствующего формата файла для хранения.
Решением данной задачи я занимался при формировании датасета по транзакциям клиентов за последние полгода. Попробую, с точки зрения теории, определить наилучший формат для хранения данных нашей задачи. Первоначально опишем существующие форматы файлов. Hdfs поддерживает несколько основных типов форматов файлов для хранения, которые принято разделять на 2 группы:
Строковые форматы: csv, json, avro.
Колоночные форматы: rc, orc, parquet.
Строковые типы данных, такие как csv, json, avro, сохраняют данные в строки. Данный тип позволяет достаточно быстро записывать данные в витрину, а такой формат как avro позволяет также динамически изменять схему данных. Однако, задачи по чтению и фильтрации данных строковых форматов требуют большего времени, чем в колоночных форматах, из-за самого алгоритма чтения и фильтрации данных. Данный алгоритм можно описать в 3 этапа:
- выбирается одна отдельная строка;
- производится разделение этой строки на столбцы;
- производится фильтрация данных и применение функций к соответствующим строкам.
Кроме того, строковые форматы зачастую занимают значительно большее место в хранилище, чем колоночные форматы, ввиду их плохой сжимаемости. Кратко опишем вышеперечисленные строковые форматы.
CSV – распространенный формат данных, используемый зачастую для передачи информации между различными хранилищами. Схема данных в таком формате статична и не подлежит изменению.
JSON – хранение данных на hdfs в формате json несколько отличается от привычного json-файла тем, что каждая строка представляет собой отдельный json-файл.
Примером данного формата файла может послужить следующий набор данных:
{id: 1, name: ‘Иван’, surname: ‘Иванов’, second_name: ‘Иванович’}
{id: 2, name: ‘Петр’, surname: ‘Петров’, second_name: ‘Петрович’}
Как видно из примера, основным отличием данного формата от формата CSV является его разделимость и то, что он содержит метаданные вместе с данными, что позволяет изменять исходную схему данных. Также данный формат файлов позволяет хранить сложные структуры данных в колонках, что является еще одним отличием данного формата от CSV формата. К недостаткам данного формата можно отнести также плохую сжимаемость в блоках данных и значительные затраты на хранение данного типа файлов (даже по сравнению с форматом CSV из-за необходимости дублирования метаданных для каждой строки).
Наибольшую же популярность среди строковых форматов хранения данных занимает формат AVRO. Данный формат представляет собой контейнер, содержащий в себе заголовок и один или несколько блоков с данными:
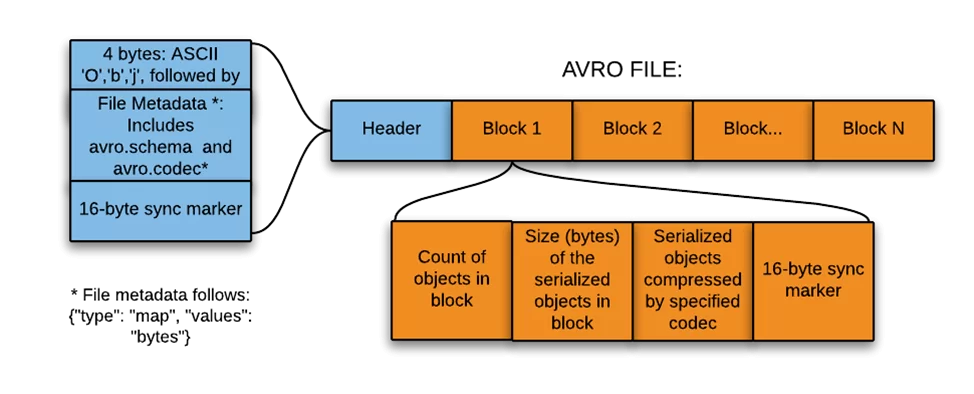
Заголовок состоит из:
- ASCII слова ‘Obj1’;
- Метаданных файла, включая определение схемы;
- 16-байтного случайного слова (маркера синхронизации).
Блоки данных в свою очередь состоят из:
- Числа объектов в блоке;
- Размера серриализованных объектов в блоке;
- Сами данные, представленные в двоичном виде, с определенным типом сжатия;
- 16-байтного случайного слова (маркера синхронизации).
Основным преимуществом данного формата являются его сжимаемость, возможность изменения схемы данных. К минусам можно отнести то, что этот формат отсутствует из коробки, и для возможности чтения и записи необходимо устанавливать внешний компонент Avro.
Колоночные же форматы напротив занимают значительно большее время для записи данных, однако же они значительно быстрее решают задачи чтения и фильтрации данных, занимая при этом значительно меньшее пространство на дисках, по сравнению со строковыми форматами. Наиболее распространенными колоночными форматами являются форматы orc и parquet.
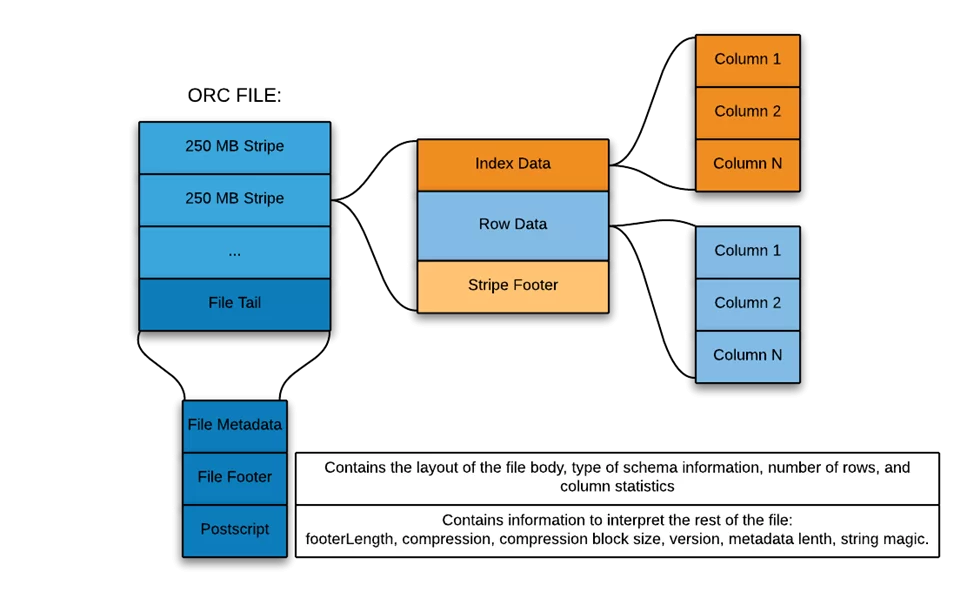
ORC (Optimized Record Columnar File) – колоночный формат данных, разделяющий исходный набор данных на полосы, размером в 250M каждая. Колонки в таких полосках разделены друг от друга, обеспечивая избирательное чтение, что увеличивает скорость обработки такой полоски. Кроме того, данные полоски хранят в себе индексы и предикаты, что в свою очередь обеспечивает еще большую скорость чтения и фильтрации данных. Ниже приведена схема структуры ORC файла.
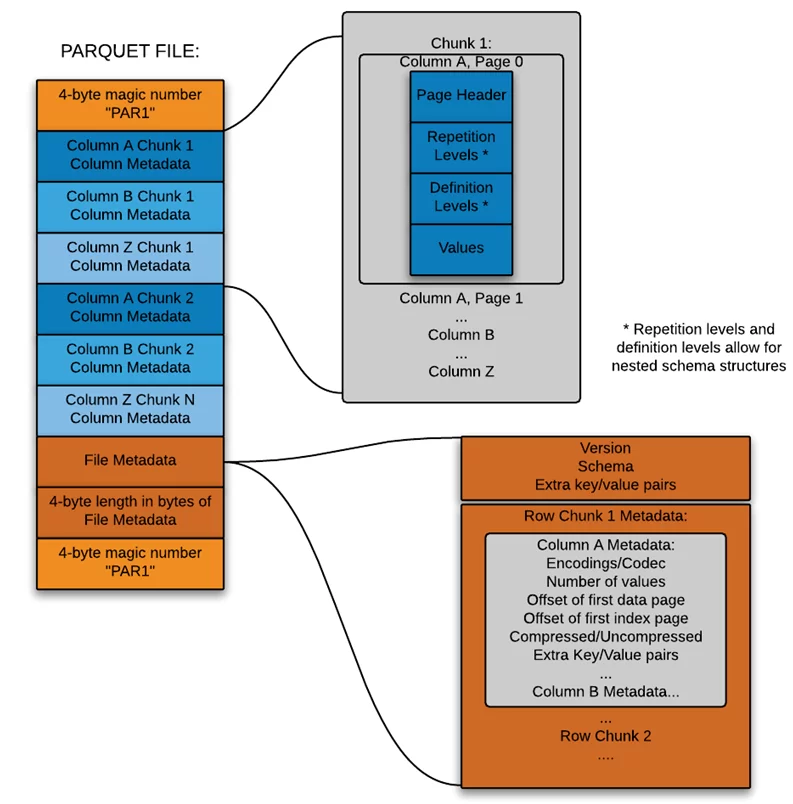
Parquet – это бинарный колоночно-ориентированный формат данных. Данный формат имеет сложную структуру данных, которая разделяется на 3 уровня:
- Row-group – логическое горизонтальное разбиение данных на строки, состоящие из фрагментов каждого столбца в наборе данных;
- Column chunk – фрагмент конкретного столбца;
- Page – содержит в себе наборы row-group. Данные страницы разграничиваются между собой с помощью header и footer. Header содержит волшебное число PAR1, определяющее начало страницы. Footer содержит стартовые координаты каждого из столбцов, версию формата, схему данных, длину метаданных (4 байта), и волшебное число PAR1 как флаг окончания.
Более подробно структура файла parquet представлена на следующей схеме:
Выбор определенного типа и группы форматов файлов во многом зависит от решаемой задачи.
Мой датасет состоит в основном из простейших типов данных, таких как числа, дата со временем и небольших строковых данных, в связи с чем каких-либо ограничений на выбор формата для хранения у нас нет. Основным критерием будет обеспечение наилучшего быстродействия для операций чтения и фильтрации данных, при этом обеспечивая минимальный занимаемый размер данных. В связи с этим я построил краткую матрицу, описывающую качественные характеристики вышеизложенных форматов на основе заданных критериев:
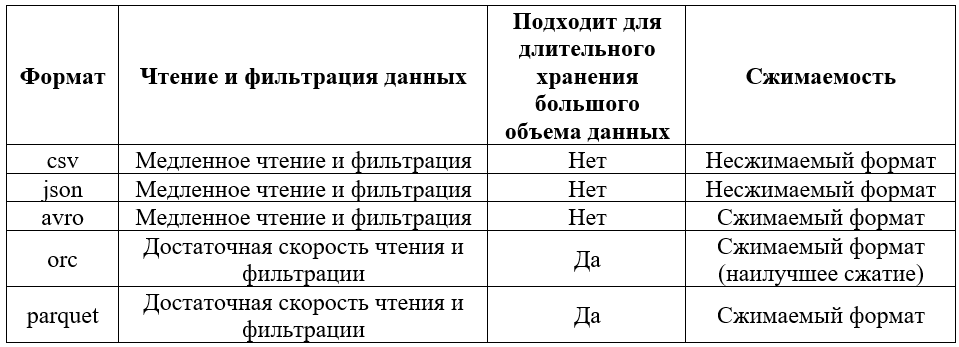
Формат AVRO далее не будет рассматриваться, так как не поддерживается на нашем кластере. Ниже приведена матрица сопоставления количественных характеристик данных форматов файлов на реализованном датасете, который содержит около 100 млн. строк различных простых форматов:
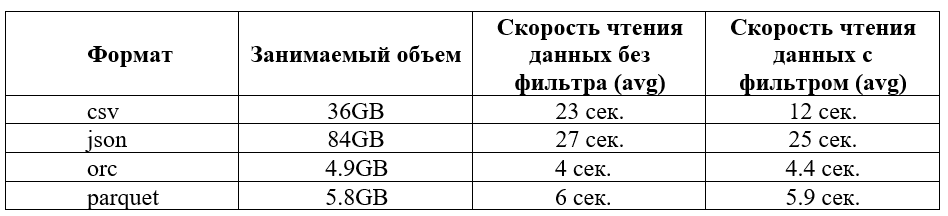
Для большей достоверности результатов расчета были применены следующие условия:
- Запуск задач производился с одинаковой конфигурацией для каждой из job-ов.
- Количество запусков тестового запроса было равно 20.
- Одинаковые запросы для каждого формата.
- Задачи отрабатывали на свободном кластере.
- Время чтения данных учитывалось без времени, затрачиваемом на запуск и остановку job-а.
Как видно из приведенных таблиц, для решения нашей задачи наиболее подходящим форматом является ORC, так как он предоставлял наилучшее сжатие данных, при этом давая оптимальную производительность выполнения запросов на чтение данных.
Ниже приведу простой код создания таблиц с определенным форматом посредством hiveQL запроса:
CREATE TABLE tbl_name (id int, ….)
STORED AS [ORC|JSON|CSV|PARQUET|AVRO]
Или:
CREATE TABLE tbl_name
STORED AS [ORC|JSON|CSV|PARQUET|AVRO]
As select * from another_table
И запрос на языке Spark на примере создания таблицы формата parquet:
Spark_df.write.format(‘parquet’).mode(‘overwrite’).saveAsTable(‘tablename’)В результате были рассмотрены различные форматы данных, кратко описаны их плюсы и минусы и приведен код для создания таблиц с выбором соответствующего формата. Надеюсь, эта публикация была для вас полезна.