/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Задачи, которые сегодня решает машинное обучение, зачастую являются комплексными и включают в себя большое количество признаков (фичей). Из-за сложности и многообразия исходных данных применение простых моделей машинного обучения часто не позволяет достигнуть необходимых результатов, поэтому в реальных бизнес-кейсах применяют сложные, нелинейные модели. У таких моделей есть существенный недостаток: из-за их сложности практически невозможно увидеть логику, по которой модель присвоила именно этот класс операции по счету. Особенно большое значение интерпретируемость модели играет, когда результаты ее работы необходимо представить заказчику — он скорее всего захочет узнать, на основе каких критериев принимаются решения для его бизнеса.
В стандартных пакетах для машинного обучения, таких как sklearn, xgboost, lightGBM существуют методы для оценки важности влияния на конечный результат той или иной фичи (параметра). Однако эти метрики важности не дают представление о том, как именно эти признаки влияют на предсказания модели. Например, как время проведенной операции указывает на то, была ли сделка мошеннической? Или как сильно адрес прописки владельца карты смещает предсказание модели? Для ответа на эти вопросы необходимо найти комплексное решение, которое помогло бы повысить интерпретируемость нелинейных моделей. Таким инструментом является библиотека SHAP. В библиотеке SHAP для оценки вклада фичей в итоговое предсказание моделей рассчитываются значения Шэпли. Для оценки важности фичи происходит оценка предсказаний модели, которая была обучена на основе датасета с и без данной фичи.
Рассмотрим работу данной библиотеки на примере определения мошеннических операций. Рассмотрим поля, которые есть в нашей таблице. В таблице содержится 213 столбцов, что довольно много для ручного перебора с помощью метода обучения модели без каждого признака поочередно для выявления важности каждой из фич.
Приведенный ниже код взят с kaggle и доработан для демонстрации функций рассматриваемого инструмента.
Загрузим наши датасеты:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()
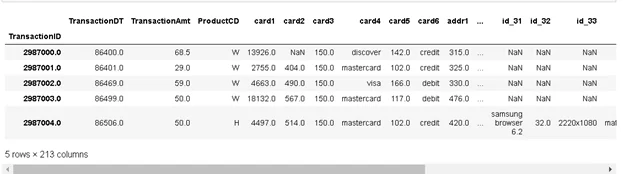
В данном датасете представлена информация о времени транзакции, времени последней транзакции, домены электронных почт продавца и покупателя, временной промежуток между последней и предыдущей транзакцией и другие параметры, смысл некоторых был скрыт из соображений конфиденциальности.
Для решения поставленной задачи, которая заключается в обнаружении подозрительных (мошеннических) банковских транзакций, необходимо провести предобработку данных, так как данные весьма разнородны. Необходимо заменить категориальные переменные, нормализовать числовые значения, заполнить пропуски, а также создать новые признаки для модели.
После обучения модели на обработанных данных была получена следующая картина важности признаков.
Сделаем график важности фичей:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()
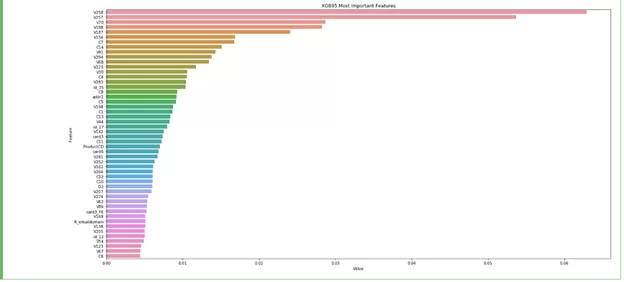
Исходя из этого видно, что большую значимость на определение мошеннических действий влияют дополнительные признаки, которые не имеют детального описания. Возникает вопрос: каким образом влияют эти признаки на работу классификатора? В таком формате информативность таблицы оценки важности признаков очень мала. Мы точно не знаем, что это за признак и мы абсолютно не знаем, как он влияет на конечный результат. Для того, чтобы получить интерпретируемый результат, применим библиотеку SHAP. В результате получим график, который показывает влияние признаков на то, какой вердикт сделает модель: была ли транзакция мошеннической или вы действительно покупаете моющие средства на сумму 20 тыс. рублей или 50 арбузов.
Сделаем график важности признаков для нашей нелинейной функции:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
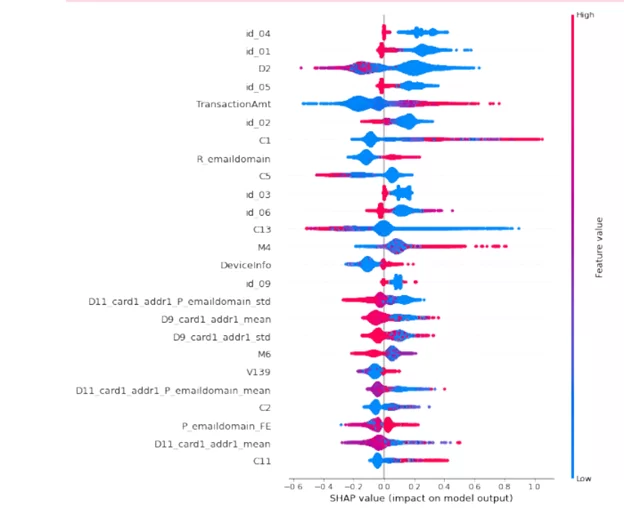
На графике присутствует информация о том, как сильно каждый параметр влияет на результат предсказания модели. Сам график разделен на 2 части вертикальной чертой. Слева от него находится класс «0», а справа класс «1». Толщина линии на графике напротив параметра показывает нам, как много элементов присутствует в выборке с данным значением конкретного параметра. Чем краснее точки на графике, тем большее значение имеет фича в ней. Исходя из легенды, которую предоставляют нам разработчики, библиотеки и получившегося графика, можно сделать вывод: чем выше была сумма транзакции, тем выше вероятность, что она была мошеннической. Также на предсказание модели сильно влияет адрес владельца карты, а также его домен email.
На основе полученных данных можно облегчать модель, то есть оставлять только параметры, которые оказывают значимое влияние на результаты предсказания нашей модели. Кроме того, появляется возможность оценить важность фичей для отдельных подгрупп данных, например, клиенты из разных регионов, транзакции в разное время суток и т. д. Кроме того, данный инструмент можно применять для анализа отдельных случаев, например, для анализа «выбросов» и экстремальных значений. Также SHAP может помочь в поиске западающих зон при классификации негативных явлений. Данный инструмент в комплексе с другими подходами позволит сделать модели более легкими, качественными, а результаты интерпретируемыми.