/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Мы все знаем, насколько проблематичным может быть отслеживание результатов машинного обучения (ML).
Если вы обучаете множество моделей с помощью библиотек ML: TensorFlow, PyTorch, XGBoost и т.д., для каждой модели исследуете ряд гипер-параметров и вычисляете показатели производительности изменяя данные, добавляя или удаляя функции, переобучая свои модели снова и снова, при этом, вы работаете в команде и есть потребность сравнивать результаты с коллегами, изучающими данные, то MLflow идеально подходит для этих задач.
«MLflow» — это платформа[1], позволяющая оптимизировать процесс машинного обучения, включая отслеживание результатов ML, упаковку кода в воспроизводимые модели на любых платформах, а также обмен моделями и их развертывание — mlflow.org[2]. MLflow пакет можно установить в среде Python. Одной из компонент[3] MLflow является Tracking, который позволяет записывать и отслеживать результаты ML сравнений с помощью интерактивного пользовательского интерфейса.
Для начала использования MLflow наша команда осуществила установку платформы с помощью pip:
pip install mlflowДалее, мы импортировали MLflow и использовали метод set_tracking_uri, для указания пути к месту хранения MLflow результатов каждого запуска. После, вызвали метод create_experiment с соответствующим именем.
#создаем локальный сервер mlflow
mlflow.set_tracking_uri(r"file///C:/Users/папка назначения локального сервера")
#после инициализации mlflow можно в командной строке командой "mlflow ui" запустить user interface локально. Далее по адресу http://127.0.0.1:5000 открыть интерфейс
# данные одного эксперимента
experiment_id = 1
n_estimators = 100
max_depth = 3
max_features = 7
Для записи в журнал пользовательских параметров, метрик, а так же сохранения модели при каждом запуске, мы дополнили код внутри mlflow.start_runcontext, указав в качестве аргумента переменную experiment_id.
Внутри этого контекста MLflow создает запуск модели с уникальным id (run_id), который отслеживает пользовательские метрики и параметры:
— сохранение параметра с помощью метода mlflow.log_param;
— сохранение метрики с помощью метода mlflow.log_metric;
— сохранение модели в качестве артефакта можно сделать простым способом, вызвав mlflow.sklearn.log_model.
# запускаем эксперимент
experiment_id = mlflow.create_experiment("training experiment_1")
with mlflow.start_run(experiment_id=experiment_id):
model = RandomForestClassifier (n_estimators=n_estimators,
max_depth=max_depth,
max_features=max_features, n_jobs=-1,)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_pred)
mlflow.log_param("n_estimators",n_estimators)
mlflow.log_param("n_estimators",n_estimators)
mlflow.log_param("max_depth",max_depth)
mlflow.log_param("max_features",max_features)
mlflow.log_metric("accuracy",accuracy)
mlflow.log_metric("precision",precision )
mlflow.log_metric("recall",recall )
mlflow.log_metric("f1",f1 )
mlflow.log_metric("auc",auc )
mlflow.sklearn.log_model(model,"model")
mlflow.end_run()
После отработки эксперимента 1, обновляем http://127.0.0.1:5000 и изучаем метрики нашей модели, далее аналогично запускаем эксперименты 2, 3, и т.д. с различными гиперпараметрами. Находим модель с наилучшими результатами.
В итоговой таблице мы получили запуски моделей и отслеживаемые метрики. Интерактивная таблица позволяет сортировать результаты и просматривать более подробную информацию (метрики, параметры, продолжительность, статус, git-commit и тд.).
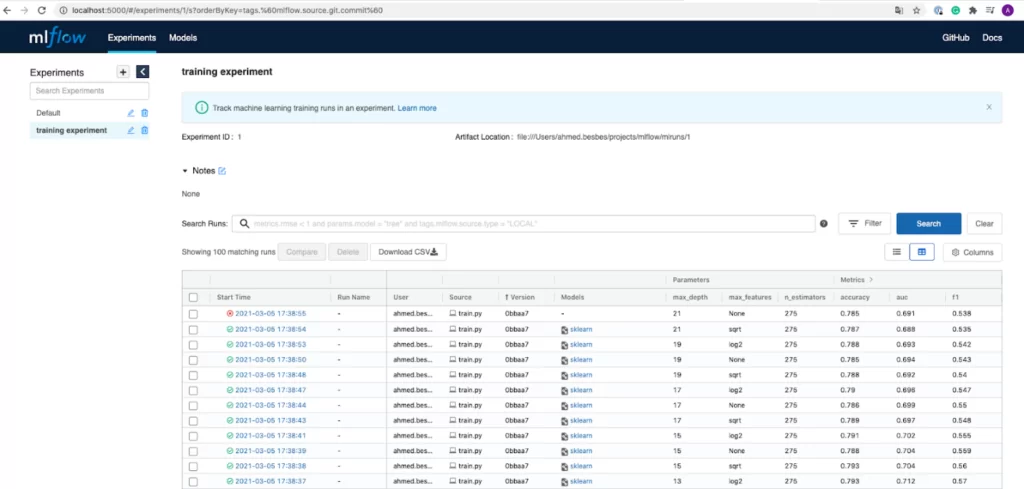
Теперь мы используем в работе MLflow. Это отличный пользовательский интерфейс для визуализации разных результатов запуска моделей и сравнения их между собой.
Попробуйте и вы!
*Тестовый пример использования MLflow размещен:
ноутбук для воспроизведения: https://github.com/0708pasha/ML_SKILLS/tree/main/mlflow
данные из ноутбука брал тут: https://www.kaggle.com/blastchar/telco-customer-churn
[1] Платформа с открытым исходным кодом для цикла машинного обучения.
[2] https://mlflow.org/docs/latest/index.html
[3] — Projects: преобразование/упаковка ML кода в многократно используемую, воспроизводимую форму для обмена данными с другими коллегами или для передачи в production;
— Models: Управление и развертывание моделей от различных ML библиотек до различных платформ обслуживания (Docker, Apache Spark, Azure ML и AWS SageMaker);
— Model Registry: Централизованное хранилище моделей, набор API и пользовательский интерфейс для совместного управления полным жизненным циклом моделей MLflow.