/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Существует несколько способов преобразовать категории в числа, каждый из них имеет свои плюсы и минусы. Выбор метода зависит от типа и смысла ваших данных, мощности множества категорий, алгоритма машинного обучения.
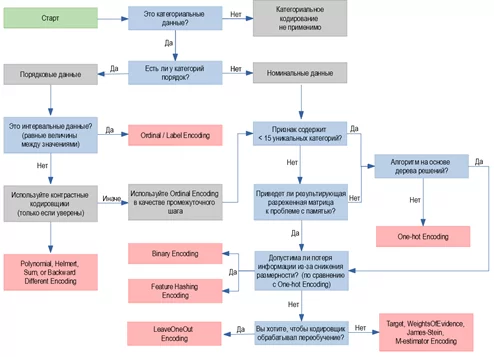
Ниже приведена схема, как выбрать подходящий метод кодирования.
Рассмотрим наиболее популярные методы преобразования категорий в числа.
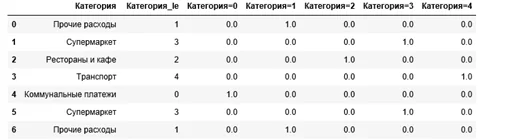
Самый простой способ – обычная нумерация значений (0, 1, 2, …). У данного подхода есть существенный недостаток. Обычно он ведет к плохому результату так как, алгоритмы начинают учитывать бессмысленную упорядоченность значений признаков. Однако данный метод имеет преимущество с точки зрения памяти.
Метод реализован в классе sklearn.preprocessing.LabelEncoder.
import pandas
from sklearn.preprocessing import LabelEncoder
df = pandas.read_excel('Пример данных.xls')
le = LabelEncoder()
le.fit(df['Категория'])
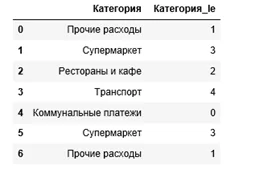
df['Категория_le']=le.transform(df['Категория'])
df
Следующий способ – dummy-кодирование, также называемое — one-hot. Суть заключается в создании дополнительных N признаков (столбцов), где N – количество уникальных категорий. Новые признаки принимают значения 0 или 1 в зависимости от принадлежности к категории. One-hot encoder значительно увеличивает объем данных, что делает его неэффективным с точки зрения памяти, частично эту проблему решает применение разреженных матриц. Метод реализован в классе sklearn.preprocessing.OneHotEncoder.
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
ohe_ftrs = ohe.fit_transform(df['Категория_le'].values.reshape(-1,1))
tmp = pandas.DataFrame(ohe_ftrs, columns = ['Категория=' + str(i) for i in range(ohe_ftrs.shape[1])])
df = pandas.concat([df, tmp], axis=1)
df
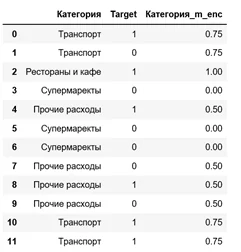
Далее рассмотрим метод среднего кодирования (Mean/Target Encoding). Метод предполагает кодирование категорий средним арифметическим от суммы целевых меток (Target). Вариация этого метода рассматривалась нами ранее в задаче предсказания спроса, вместо целевых меток, мы брали другой признак — цену на товар, таким образом категории товаров упорядочивались их дороговизной. Однако, при кодировании средним по Target велика вероятность переобучения модели, эту проблему поможет решить регуляризация.
Простейший вариант Mean Encoding представлен ниже.
def mean_target_encoding(df, target, column):
mean_enc = df.groupby(column)[target].mean()
df[column+'_m_enc'] = df[column].map(mean_enc)
return (df)
target = 'Target'
column = 'Категория'
mean_target_encoding(df, target, column)
df
Подводя итоги, напомню, что методов кодирования существует гораздо больше, и среди них нет универсальных. Выбирая метод, стоит отталкиваться от ваших данных, мощности множества категорий и алгоритма машинного обучения.