/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 10 мин.
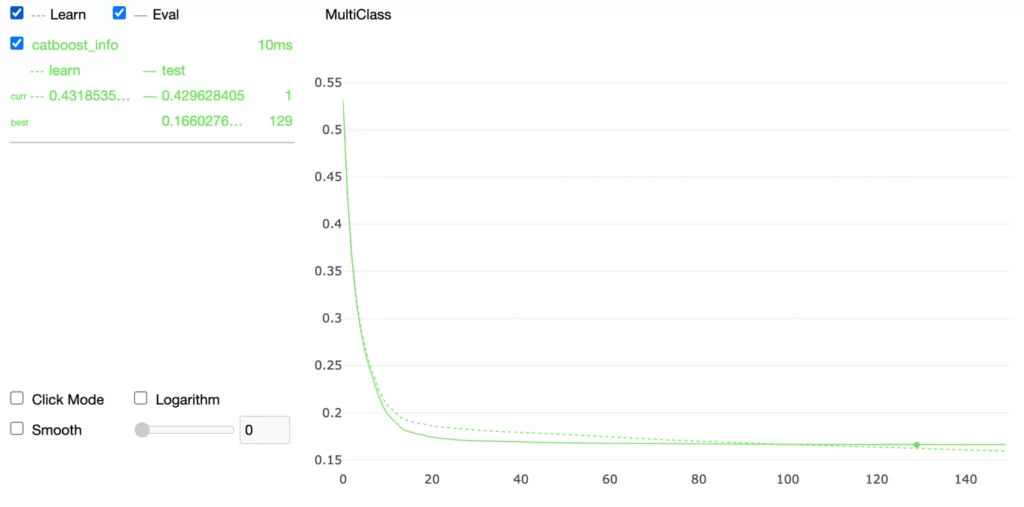
В предыдущих частях мы рассматривали задачу бинарной классификации. Если классов более чем два, то используется MultiClassification, параметру loss_function будет присвоено значение MultiClass. Мы можем запустить обучение на нашем наборе данных, но мы получим те же самые результаты, а обучение будет идти несколько дольше:
from catboost import CatBoostClassifier
model = CatBoostClassifier(
iterations=150,
random_seed=43,
loss_function='MultiClass'
)
model.fit(
X_train, y_train,
cat_features=cat_features,
eval_set=(X_test, y_test),
verbose=False,
plot=True
)
Далее речь пойдет об Metric Evaluation. Давайте сначала обучим модель:
model = CatBoostClassifier(
random_seed=63,
iterations=200,
learning_rate=0.05
)
model.fit(
X_train, y_train,
cat_features=cat_features,
verbose=50
)
0: learn: 0.6353678 total: 5.08ms remaining: 1.01s
50: learn: 0.1851225 total: 480ms remaining: 1.4s
100: learn: 0.1688818 total: 1.07s remaining: 1.05s
150: learn: 0.1637798 total: 1.66s remaining: 539ms
199: learn: 0.1598385 total: 2.22s remaining: 0us
Часто так бывает, что забыли указать какие-то метрики при обучении модели, или после обучения хотим посчитать значения метрик на наборе данных, который не использовался ранее, в этом случае на помощь нам приходит eval_metrics:
metrics = model.eval_metrics(
data= pool1,
metrics= ['Logloss', 'AUC'],
ntree_start= 0,
ntree_end= 0,
eval_period= 1,
plot=True
)
Здесь у нас передается модель, которую хотим использовать, затем датасет, на котором будем обучать, следующим параметром передадим список метрик, по которым будем считать, параметры из ранее рассказанного Stage Prediction и в eval_metrics так же можно передать параметр встроенного визуализатора Catboost’a:
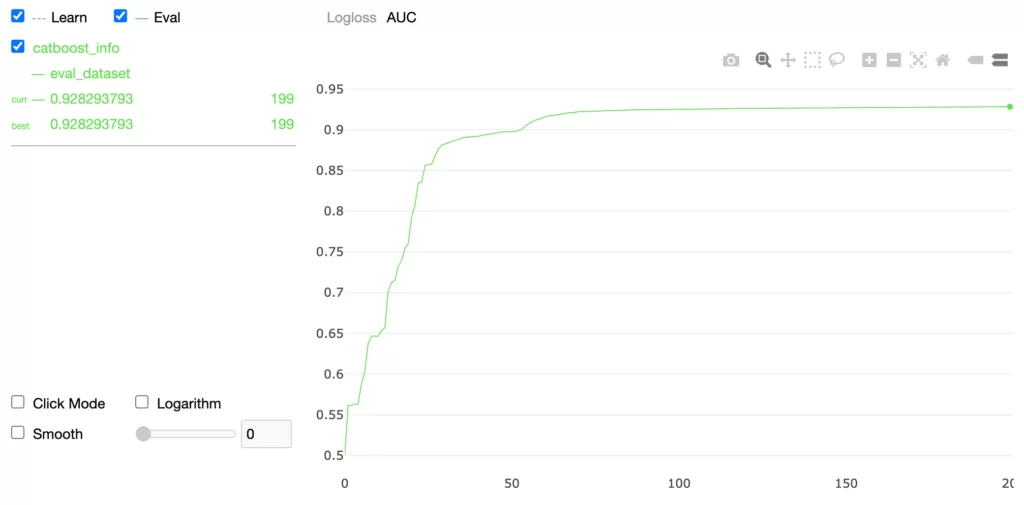
Посмотрим значения AUC:
print(f'AUC values: \n {np.array(metrics["AUC"])}')
AUC values:
[0.5007 0.5615 0.5615 0.563 0.563 0.5881 0.6033 0.6377 0.6468 0.6469
0.6464 0.6533 0.6569 0.7017 0.7122 0.7152 0.7322 0.7396 0.7542 0.7603
0.7927 0.8075 0.8346 0.8355 0.856 0.8576 0.8576 0.868 0.876 0.8812
0.8826 0.8848 0.886 0.8868 0.8885 0.8897 0.8907 0.8909 0.8913 0.8919
0.8921 0.8929 0.8941 0.8942 0.8953 0.8959 0.8968 0.8973 0.8974 0.8975
0.8975 0.8978 0.899 0.9009 0.9047 0.9074 0.9098 0.9116 0.9132 0.9144
0.916 0.9167 0.9174 0.9187 0.9195 0.92 0.9201 0.9209 0.9208 0.9218
0.9222 0.9222 0.9224 0.9226 0.9227 0.923 0.9231 0.9233 0.9234 0.9236
0.9239 0.924 0.924 0.924 0.9243 0.9243 0.9246 0.9246 0.9244 0.9245
0.9245 0.9248 0.9249 0.9249 0.925 0.9251 0.9251 0.9251 0.9251 0.9251
0.9251 0.9251 0.925 0.9253 0.9252 0.9253 0.9254 0.9255 0.9255 0.9258
0.9258 0.9258 0.9258 0.9259 0.9259 0.9259 0.9259 0.9261 0.9261 0.9262
0.9261 0.9264 0.9264 0.9265 0.9265 0.9265 0.9266 0.9267 0.9267 0.9266
0.9266 0.9266 0.9266 0.9267 0.9267 0.9268 0.9267 0.9267 0.9267 0.9267
0.9267 0.9267 0.9268 0.9269 0.9269 0.9269 0.9269 0.927 0.927 0.927
0.927 0.9271 0.9272 0.9271 0.9271 0.9271 0.9272 0.9272 0.9272 0.9272
0.9272 0.9272 0.9272 0.9273 0.9273 0.9273 0.9274 0.9274 0.9275 0.9275
0.9276 0.9276 0.9277 0.9277 0.9277 0.9277 0.9278 0.9278 0.9278 0.9278
0.9278 0.9278 0.9279 0.928 0.9281 0.9281 0.9282 0.9282 0.9282 0.9282
0.9282 0.9281 0.9281 0.9282 0.9281 0.9282 0.9282 0.9282 0.9282 0.9283]
Теперь про анализ модели. Вот мы обучили модель, получили некоторые предсказания и нам надо понять, а какие фичи у нас важные в нашем обучении? Для этого мы воспользуемся методом get_feature_importance(), он возвращается pandas DataFrame с фичами, которые важны в нашем обучении:
model.get_feature_importance(prettified=True)
Глядя на данную таблицу мы видим, что самой важной фичей является RESOURCE, к которому запросил доступ пользователь, так же важно к какому ресурсу дается доступ, какому пользователю и в каком департаменте он работает.
Иногда хочется посмотреть важность фичей не по всей выборке, а по конкретному объекту, для этого необходимо воспользоваться shap_values, в этом случае мы получим матрицу, где число строк будет такое же как число объектов, а число столбцов будет число фичей + 1:
shap_values=model.get_feature_importance(pool1, fstr_type='ShapValues')
print(shap_values.shape)
(32769, 10)
Теперь воспользуемся библиотекой shap, чтобы визуализировать наши фичи:
import shap
explainer = shap.TreeExplainer(model)
shap_values=explainer.shap_values(Pool(X, y, cat_features=cat_features))
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[3,:], X.iloc[3,:])

Эта картинка означает, что для третьего объекта фичи MGR_ID, ROLE_FAMILY_DESC, ROLE_FAMILY и т. д., двигают наше предсказание в положительную сторону, они увеличивают вероятность того, что объекту выдадут права доступа, а RESOURCE, ROLE_TITLE наоборот, уменьшают данную вероятность.
Посмотрим еще один пример для другого объекта:
import shap
shap.initjs()
shap.force_plot(explainer.expected_value,shap_values[91, :], X.iloc[91, :])

Здесь ситуация иная, вероятность того, что пользователю не дадут доступ намного больше, нежели он его получит, слишком много фичей склоняют предсказание к отрицательному исходу.
Сделаем то же самое не для одного объекта, как это было в предыдущих двух случаях, а сразу, допустим, для двухсот объектов из нашей выборки:
X_small = X.iloc[0:200]
shap_small = shap_values[:200]
shap.force_plot(explainer.expected_value, shap_small, X_small)
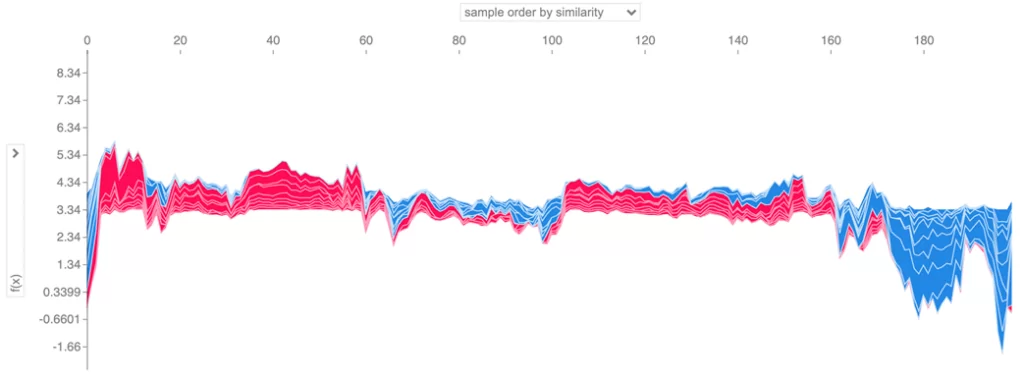
По оси X у нас расположена шкала вклада значения фичи, по оси Y — количество объектов.
Так же в Catboost есть shap.summary_plot(), который рисует по всей выборке такую же информацию, как и в предыдущих трех случаях:
shap.summary_plot(shap_values, X)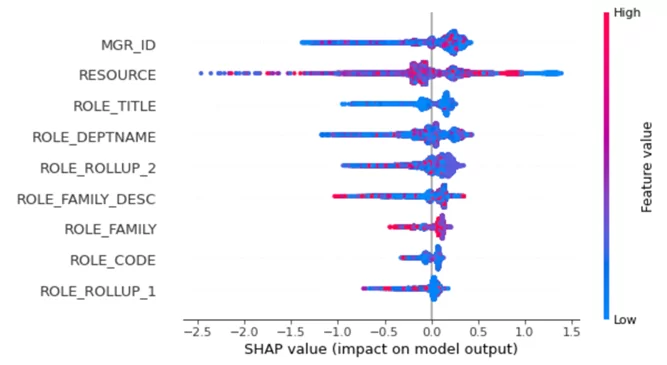
Цветом показано значение фичи, чем краснее цвет – тем выше значение фичи, чем цвет более синий – тем меньше. Так же для каждой фичи набросаны точки, каждая точка соответствует одному объекту обучающей выборки, те точки, которые находятся правее серой черты – для них вклад от этой фичи положительный, но он не совсем большой, а которые левее, вклад большой, но не каждого из объектов обучающей выборки.
Далее рассмотрим Feature Evaluation. Часто так бывает, что мы имеем какую-то фичу и надо проверить, а хороша ли или нет, проверить можно все с помощью того же CatBoost’a. Мы обучаем модель на нескольких кусках выборки с использованием этой фичи и без нее, смотрим как изменяется Logloss.
from catboost.eval.catboost_evaluation import *
learn_params= {
'iterations': 250,
'learning_rate': 0.5,
'random_seed':0,
'verbose': False,
'loss_function': 'Logloss',
'boosting_type': 'Plain'
}
evaluator = CatboostEvaluation(
'amazon/train.tsv',
fold_size=10000,
fold_count=20,
column_description='amazon/train.cd',
partition_random_seed=0
)
result=evaluator.eval_features(learn_config=learn_params,
eval_metrics=['Logloss', 'Accuracy'],
features_to_eval=[1, 3, 8])
В learn_params мы передаем параметры обучения модели, в evaluator мы передаем путь до выборки, размер fold’a и количество параллельных обучений с фичей и без нее, так же путь до column description. Далее мы в eval_features, в нее передаем параметры обучения, метрики, которые хотим посмотреть и фичи, которые хотим «проэвалить».
Данный кусок кода вернет pandas DataFrame, где мы увидим строки по каждой фиче, которые передавали в список:
from catboost.eval.evaluation_result import *
logloss_result=result.get_metric_results('Logloss')
logloss_result.get_baseline_comparison(
ScoreConfig(ScoreType.Rel, overfit_iterations_info=False)
)
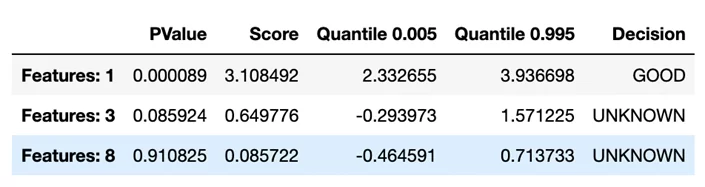
Decision показывает нам хорошая фича или нет, но в данном случае, одна фича хорошая, а по двум другим неизвестно, какие эти фичи. Чем меньше Pvalue, тем больше вероятность, что эта фича хорошая, в таблице это наглядно видно. Score показывает нам насколько уменьшился Logloss.
Так же в Catboost’e присутствует возможность сохранения модели, вдруг вы захотите ее скинуть другу или же вы захотите лично ей воспользоваться в будущем, происходит это следующим образом:
best_model = CatBoostClassifier(iterations=100)
best_model = model.fit(
X_train, y_train,
eval_set=(X_test, y_test),
cat_features=cat_features,
verbose=False
)
best_model.save_model('catboost_model.json')
best_model.save_model('catboost_model.bin')
Давайте теперь загрузим нашу модель:
best_model.load_model('catboost_model.bin')
print(best_model.get_params())
print(best_model.random_seed_)
{'iterations': 200, 'learning_rate': 0.05, 'random_seed': 63, 'loss_function': 'Logloss', 'verbose': 0}
63
Финишная прямая. Займемся подбором гиперпараметров.
from catboost import CatBoost
fast_model = CatBoostClassifier(
random_seed=63,
iterations=150,
learning_rate=0.01,
boosting_type='Plain',
bootstrap_type='Bernoulli',
subsample=0.5,
one_hot_max_size=20,
rsm=0.5,
leaf_estimation_iterations=5,
max_ctr_complexity=1
)
fast_model.fit(
X_train, y_train,
cat_features=cat_features,
verbose=False,
plot=True
)
Многие знают, что такое random_seed, learning_rate, iterations, но расскажу о других параметрах, boosting_type – это тип бустинга, который мы будем использовать при обучении, Plain дает качество хуже, но работает быстрее, есть другой параметр — Ordered, он более затратный, но дает лучшее качество. Дальше идут в связке два параметра bootstrap_type & subsample, bootstrap_type – это тип сэмплирования, когда мы строим дерево, построение идет не по всем объектам обучающей выборки, а по нескольким объектам, subsample – это вероятность, по которой будет выбираться каждый объект для построения дерева. One_hot_max_size – это горячее кодирование определенных переменных выборки (мы конвертируем каждое категориальное значение в новый категориальный столбец и присваиваем этим столбцам двоичное значение 1 или 0). RSM, он аналогичен subsample, только используется для фичей. Leaf_estimation_iterations – это количество итераций подсчета значений в листьях. Max_ctr_complexity – это длина перебора комбинаций фичей нашей выборки.
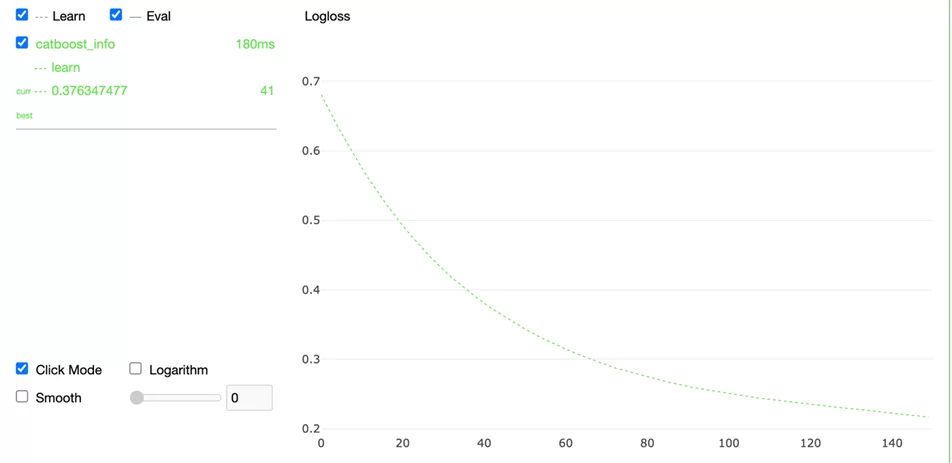
Такую вот кривую мы получили после запуска данного куска кода.
Далее идет Accuracy или же точность.
tunned_model = CatBoostClassifier(
random_seed=63,
iterations=1000,
learning_rate=0.03,
l2_leaf_reg=3,
bagging_temperature=1,
random_strength=1,
one_hot_max_size=2,
leaf_estimation_method='Newton'
)
tunned_model.fit(
X_train, y_train,
cat_features=cat_features,
verbose=False,
eval_set=(X_test, y_test),
plot=True
)
Leaf_estimation_method – это метод по которому будем подбирать значения в листьях, он более затратный, но мы получим наилучший результат. L2_leaf_reg – регуляризация L2, она делает так, чтобы листья в дереве не становились бесконечностью, этот параметр необходимо подбирать, чтобы получить наилучшие результаты при обучении. Random_strength – когда мы строим дерево, мы должны посчитать Score для каждой фичи/сплита, когда мы посчитаем кучу score, нам надо будет выбрать максимальный и по этой вот фиче и сплиту с максимальным score будет происходить разбиение:
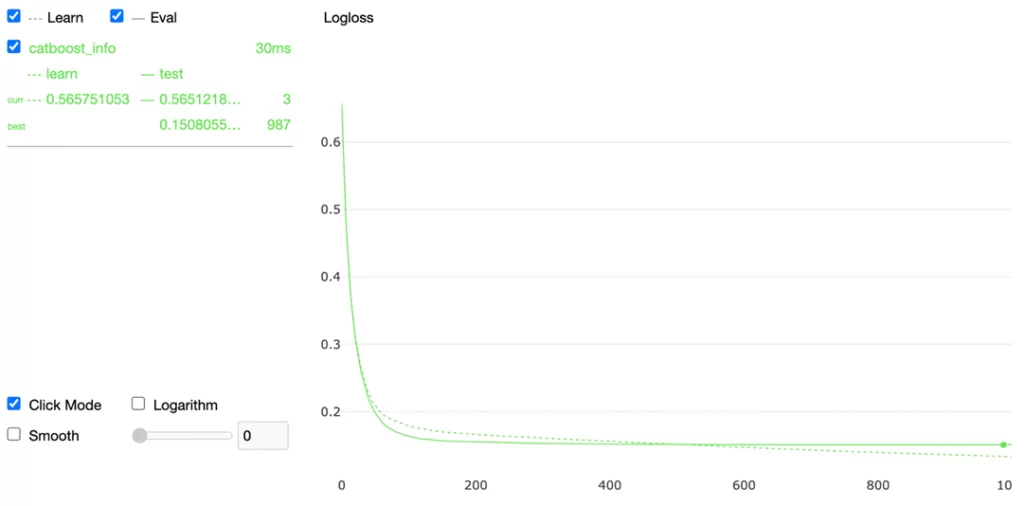
После предыдущих манипуляций мы строим новую модель:
best_model = CatBoostClassifier(
random_seed=63,
iterations=int(tunned_model.tree_count_ * 1.2)
)
best_model.fit(
X, y,
cat_features=cat_features,
verbose=100
)
Здесь количество итераций будет количество деревьев из «тюненной» модели и увеличенное на 20%, на всякий случай.
Learning rate set to 0.039123
0: learn: 0.6470380 total: 6.99ms remaining: 8.27s
100: learn: 0.1553510 total: 1.53s remaining: 16.4s
200: learn: 0.1472314 total: 3.52s remaining: 17.2s
300: learn: 0.1436190 total: 5.45s remaining: 16s
400: learn: 0.1405905 total: 7.34s remaining: 14.4s
500: learn: 0.1376786 total: 9.3s remaining: 12.7s
600: learn: 0.1349698 total: 11.3s remaining: 11s
700: learn: 0.1321758 total: 13.2s remaining: 9.1s
800: learn: 0.1296262 total: 15.1s remaining: 7.22s
900: learn: 0.1271447 total: 16.9s remaining: 5.34s
1000: learn: 0.1250894 total: 18.8s remaining: 3.46s
1100: learn: 0.1226409 total: 20.7s remaining: 1.58s
1184: learn: 0.1206717 total: 22.3s remaining: 0us
Делаем предсказания, здесь мы выкидываем колонку с id, мы ее не использовали никак при обучении. Далее в Pool мы закидываем фичи, таргет не передаем, мы их не знаем, далее закидываем индексы фичей, предсказываем вероятности и в последней ячейке мы записываем и сохраняем результаты предсказаний в csv файл:
X_test = test_df.drop('id', axis=1)
test_pool = Pool(X_test, cat_features=cat_features)
predictions=best_model.predict_proba(test_pool)
print(f"Predictions: {predictions}")
Predictions: [[0.3923 0.6077]
[0.0155 0.9845]
[0.0098 0.9902]
...
[0.0053 0.9947]
[0.0492 0.9508]
[0.0143 0.9857]]
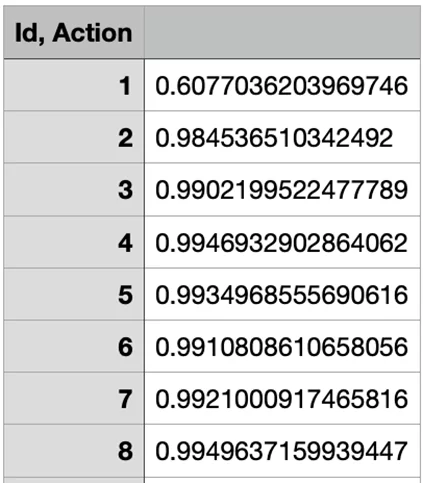
Сохранение результатов предсказаний модели:
file = open('outro.csv', 'w')
file.write('Id, Action\n')
for index in range(len(predictions)):
line = str(test_df['id'][index])+';'+str(predictions[index][1])+'\n'
file.write(line)
file.close()
В заключение хочется отметить плюсы данной библиотеки:
- Обучение моделей на CPU/GPU.
- Библиотека имеет открытую документацию.
- Multilable Classification.
- Распределенное обучение.
- Поддержка языка R (возможно, что кто-то это сочтет за незначительный плюс).