/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В своей работе недавно мне пришлось столкнуться со сравнением двух небольших абзацев текста. Предлагается выяснить насколько они похожи друг на друга. В Tensorflow для этого существует библиотека Tensorflow_text. С ее помощью можно сравнивать тексты на соответствие по различным метрикам: f-metrics, p-metrics, r-metrics. Раньше в задачах классификации я сталкивался с F-метрикой и R-метрикой. Не буду вдаваться в детали, скажу лишь, что они включают в себя 2 параметра: точность и полноту. В tensorflow_text порог регулируется аргументом alpha.
Итак, для сравнения двух наборов текста для начала нужно импортировать библиотеки.
import tensorflow as tf
import tensorflow_text as text
Дальше создаем текстовые переменные и добавляем в них текст, который хотим сравнить. Я буду сравнивать кошек и собак. Создам по 2 переменных, в каждую из которых передам определения собаки и кошки, которые взяты с разных сайтов с небольшими отличиями.
dog = 'собака домашнее животное одно из наиболее популярных животных компаньонов.'
dog = dog.split()
hound = 'собакой называют домашнее животное семейства псовых'
hound = hound.split()
cat = 'домашняя кошка домашнее животное из рода кошек млекопитающее семейства кошачьих'
cat = cat.split()
kis = 'кошка домашняя самый мелкий представитель хищных млекопитающих семейства кошачьих'
kis = kis.split()
Метод split() разделяет переменные по словам и возвращает список, где каждый элемент – отдельное слово. Я специально сохранял переменные без знаков препинания, потому что так получается выше точность при сравнении.
Далее используем tf.ragged.constant, который создает константу RaggedTensor из вложенного списка Python. Для начала сравним на сколько похожи собаки.
hypotheses = tf.ragged.constant([dog])
references = tf.ragged.constant([hound])
Далее сравниваем два подготовленных тензора, используя метрику Rouge-L. Которая показывает от 0 до 1 на сколько похожи два входных тензора. Где 0 – это совсем разные, а 1 – одинаковые.
result = text.metrics.rouge_l(hypotheses, references, alpha=0.5)
print('F-Measure: %s' % result.f_measure)
print('P-Measure: %s' % result.p_measure)
print('R-Measure: %s' % result.r_measure)
Он вернул значения.
F-Measure: tf.Tensor([0.26666665], shape=(1,), dtype=float32)
P-Measure: tf.Tensor([0.22222222], shape=(1,), dtype=float32)
R-Measure: tf.Tensor([0.33333334], shape=(1,), dtype=float32)
Получается, что определения собак совпадают примерно на 0.25. Пока что сложно сказать много это или мало. Давайте сравним насколько похожи определения кошек.
hypotheses = tf.ragged.constant([cat])
references = tf.ragged.constant([kis])
result = text.metrics.rouge_l(hypotheses, references, alpha=0.5)
print('F-Measure: %s' % result.f_measure)
print('P-Measure: %s' % result.p_measure)
print('R-Measure: %s' % result.r_measure)
F-Measure: tf.Tensor([0.31578952], shape=(1,), dtype=float32)
P-Measure: tf.Tensor([0.3], shape=(1,), dtype=float32)
R-Measure: tf.Tensor([0.33333334], shape=(1,), dtype=float32)
Здесь получается уже чуть больше, примерно 0.32. Но все равно меньше половины. Посмотрим, как влияет параметр альфа. По умолчания он равен 0.5, что соответствует балансу между точностью и упоминанием. Значения, близкие к 0, рассматривают упоминание как более важное, а значения, близкие к 1, рассматривают точность как более важную. Поставим 0.1, а затем 0.9.
F-Measure: tf.Tensor([0.32967034], shape=(1,), dtype=float32)
P-Measure: tf.Tensor([0.3], shape=(1,), dtype=float32)
R-Measure: tf.Tensor([0.33333334], shape=(1,), dtype=float32)
При 0.1 только метрика F слегка увеличилась.
F-Measure: tf.Tensor([0.3030303], shape=(1,), dtype=float32)
P-Measure: tf.Tensor([0.3], shape=(1,), dtype=float32)
R-Measure: tf.Tensor([0.33333334], shape=(1,), dtype=float32)
При 0.9 F слегка уменьшилась. Метрика зависит от точности и упоминания по формуле.
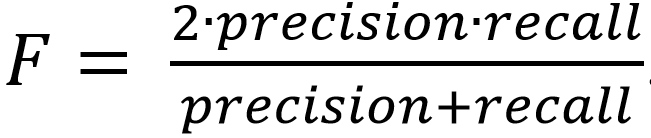
И исходя от конкретной задачи стоит выбирать альфа и тем самым регулировать значения F-метрики.
Для демонстрации работы данного способа предлагаю провести еще 3 вычисления. В первом я передам абсолютно одинаковые переменные для сравнения. Предполагается точность равная 1. Во втором сравним собаку и кошку. Определения их немного совпадают, ведь они оба являются домашними животными. А в третьем случае передам абсолютно другой текст, и соответственно предположу сходство равное 0.
hypotheses = tf.ragged.constant([cat])
references = tf.ragged.constant([cat])
F-Measure: tf.Tensor([1.], shape=(1,), dtype=float32)
P-Measure: tf.Tensor([1.], shape=(1,), dtype=float32)
R-Measure: tf.Tensor([1.], shape=(1,), dtype=float32)
Как я и предполагал, для абсолютно одинаковых текстов соответствие равно 1.
hypotheses = tf.ragged.constant([kis])
references = tf.ragged.constant([hound])
F-Measure: tf.Tensor([0.15151514], shape=(1,), dtype=float32)
P-Measure: tf.Tensor([0.11111111], shape=(1,), dtype=float32)
R-Measure: tf.Tensor([0.16666667], shape=(1,), dtype=float32)
Собака и кошка немного, но похожи по определениям.
elephant = "слон живет в африке и никогда не поместится в доме"
elephant = elephant.split()
hypotheses = tf.ragged.constant([kis])
references = tf.ragged.constant([elephant])
F-Measure: tf.Tensor([0.], shape=(1,), dtype=float32)
P-Measure: tf.Tensor([0.], shape=(1,), dtype=float32)
R-Measure: tf.Tensor([0.], shape=(1,), dtype=float32)
Как и ожидалось, кошка и слон совсем разные по определениям.
Подведем итог. С помощью tensorflow_text можно сравнивать два абзаца текста, регулируя параметр, можно настраивать сравнение для конкретных задач. Этот метод может найти широкое применение в сферах, где подразумевается работа с большим количеством текстовых документов, например, в банковских делопроизводствах. Когда необходимо в короткое время найти нужное поручение или упоминание, при этом не придется открывать вручную тысячи документов.