/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Постановка задачи.
В современном мире большинство компаний заинтересовано в предложении своих услуг как можно большему числу клиентов и пользователей их сервисов. И этим компаниям важно знать как оценивать эффект от коммуникации со своими пользователями. Помочь оценить данный эффект и выбрать интересующую группу пользователей могут модели Uplift моделирования.
Типы пользователей.
Целевым результатом применения Uplift модели является определение клиентов, взаимодействие с которыми принесет компании наиболее интересуемый эффект. Всех адресатов различных рассылок можно разделить на 4 группы:
- Человек, который отреагирует негативно, если отправить ему предложение (отпишется от рассылок, откажется от услуг сервиса и т.д.)
- Человек, который никогда не совершит действие, неважно отправить ему предложение или нет.
- Человек, который в любом случае совершит действие, даже если не отправлять ему предложение.
- Человек, который совершит действие, если отправить ему предложение.
Первые три типа не приносят дохода компании, но могут нести убытки из-за особенности реакции пользователей или затраты на способы взаимодействия с ними. Из всех пользователей, нас больше всего интересуют пользователи четвертого типа, которые ответят на предложение если напрямую отправить им его. Найти данную категорию пользователей можно при помощи Uplift-моделирования. Uplift модель оценивает разницу в поведении адресата при наличии воздействия (или предложения) и при его отсутствии.
Перед созданием модели необходимо провести эксперимент, который заключается в следующем: нужно разбить часть базы пользователей на целевую и контрольную выборку и запустить пилотную версию взаимодействия на целевой выборке пользователей. В данном случае, для взаимодействия мы должны выбирать случайных пользователей. Собранные данные позволят в дальнейшем построить модель uplift прогнозирования на контрольной группе. Также стоит рассмотреть возможность настройки разработки uplift модели итеративно: на каждой итерации будут собираться новые обучающие данные о результатах взаимодействия, которые состоят из комбинированной случайной подвыборки пользователей и пользователей, выбранных моделью.
Метрики.
При использовании uplift-моделирования наблюдается некоторая проблема с выбором метрики оценки качества. Она заключается в том, что мы не можем одновременно оправить и не отправить пользователю наше предложение и оценить его реакцию. Из-за этого мы не можем определить истинное значение целевой переменной и не сможем сравнить его с прогнозом нашей модели. Для решения этой проблемы в библиотеке sklift реализованы специальные метрики. Они схожи с привычными метриками, применяемыми в моделях машинного обучения. Одной из таких метрик является метрика Uplift curve (или Uplift кривая). Uplift кривая строится как функция от количества объектов. В каждой точке кривой можно увидеть накопленный к этому моменту uplift. Еще одной применяемой метрикой является uplift@k – размер uplift на топ k процентах выборки. Допустим, мы хотим получить какое-то количество пользователей, которым хотим отправить предложение. Для того, чтобы рассчитать uplift@k необходимо отсортировать выборку по величине предсказанного uplift и посмотреть разницы средних значений таргета в выборке пользователей, с которой было взаимодействие и с которой взаимодействия не было.
Построение модели.
Для работы с uplift-моделированием в Python есть библиотека scikit-uplift (или сокращенно sklift). В ней также есть несколько наборов данных, на которых можно протестировать реализованную модель.
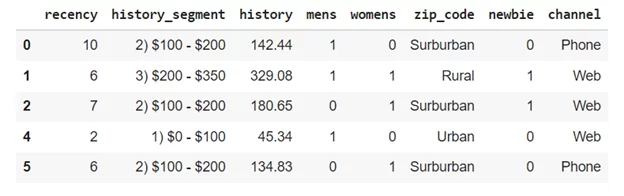
Одним из наборов данных является Hillstrom Dataset. Этот набор данных содержит информацию о 64000 покупателей, совершивших покупку в течение 12 месяцев. В нём содержатся следующие признаки:
Recency: количество месяцев с момента последней покупки.
History_Segment: категоризация денежных средств, потраченных в прошлом году.
History: Фактическая стоимость, израсходованная за последний год.
Mens: показатель 1/0, 1 = покупатель приобрел мужские товары в прошлом году.
Womens: показатель 1/0, 1 = покупатель приобрел женские товары в прошлом году.
Zip_Code: классифицирует почтовый индекс как городской, пригородный или сельский.
Newbie: индикатор 1/0, 1 = новый клиент за последние двенадцать месяцев.
Channel: описывает каналы, через которые клиент совершил покупку в прошлом году.
Перед применением Uplift-моделирования также необходимо провести разведочный анализ данных, который обычно состоит из следующих основных шагов:
- Проанализировать все виды признаков, которые имеются в нашем наборе данных (категориальные, вещественные и т.д.).
- Проверить коллинеарность признаков с помощью матрицы корреляции (оценить возможность исключения признака, в случае выявления коллинеарности с другим признаком).
- Проверить сбалансированность классов целевой переменной
Далее требуется разделить выборку данных на тренировочную и валидационную (на которой мы будем подбирать гиперпараметры). Это можно сделать с помощью функции train_test_split из библиотеки sklearn.
X_train, X_val, y_train, y_val, treat_train, treat_val = train_test_split(
dataset, target, treatment, test_size=0.3, random_state=42)
Далее нужно выбрать один из подходов к определению модели. Все базовые подходы можно разделить на два класса: походы с применением одной модели и подходы с применением двух моделей. К реализованным в библиотеке sklift подходам с применением одной модели относятся SoloModel и ClassTransformation. С помощью модели TwoModels можно реализовать как две зависимые, так и две независимые модели. Все перечисленные модели можно протестировать на имеющемся наборе данных, оценить их качество с помощью метрики uplift@k и выбрать наиболее результативную из них.
Обучение модели можно провести с помощью CatBoostClassifier из библиотеки градиентного бустинга Catboost. Суть бустинга, как и других ансамблей алгоритмов состоит в том, чтобы из нескольких слабых моделей собрать одну сильную. Общая идея алгоритмов бустинга – последовательно применять предикторы так, чтобы каждая последующая модель минимизировала ошибку предыдущей модели. К преимуществам использования библиотеки Catboost относится возможность проводить обучение на нескольких GPU; обеспечение высокой точности за счёт уменьшения переобучения; возможность предварительно не обрабатывать категориальные признаки (нет необходимости использовать one-hot кодирование); возможность использования как для задач регрессии, так и для задач классификации.
estimator = CatBoostClassifier(cat_features=cat_columns,
random_state=42,
thread_count=1
)
model = ClassTransformation(estimator=estimator)
Обучить модель можно с помощью метода fit.
model.fit(
X=X_train,
y=y_train,
treatment=treat_train
)
Далее следует вызвать метрику для оценки качества модели. Вызвать Uplit кривую можно при помощи.
auc_coef = uplift_auc_score(y_true=y_val, uplift=uplift_predictions,
treatment=treat_val)
Визуализировать полученную кривую можно использовав методы
uplift_disp = plot_uplift_curve(
y_val, uplift_predictions, treat_val,
perfect=True, name='Model name'
)
uplift_disp.figure_.suptitle("Uplift curve")
Пример графика Uplift кривой.
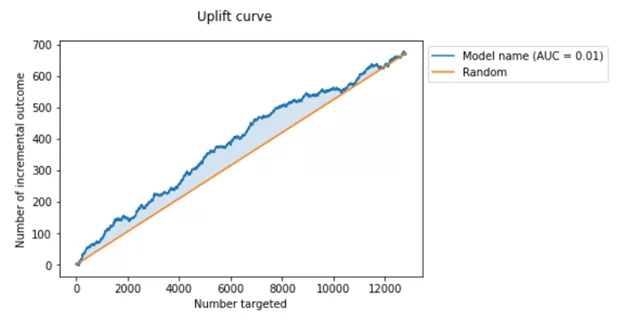
По графику Uplift кривой видно, что получившаяся модель имеет более высокую точность, чем случайная модель. Для повышения точности модели можно расширить набор данных, собрав больше информации или, например, комбинировать информацию о взаимодействии, ранжировать пользователей сначала в целевой, затем в контрольной группе.