/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Постановка проблемы
Большинство ML-алгоритмов предназначены только для количественных переменных, то есть переменных, которые имеют числовое выражение и отражают размеры или масштабы объекта. К примеру, возраст, размеры объекта, площадь и прочее аналогичное. Однако, многие признаки, участвующие в предсказании таргета, будь то регрессия или классификация, являются категориальными, то есть выражаются нечисловыми значениями — например, группа крови, пол или политическая партия.
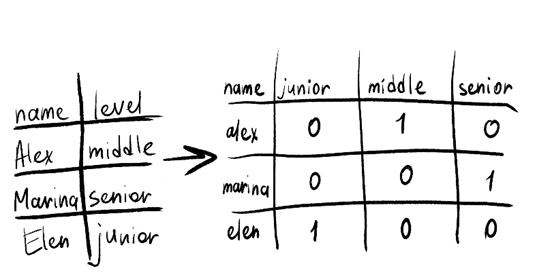
Важным этапом предобработки данных для построения модели в этом случае будет кодирование категориальных переменных, и оказывается, что не все методы одинаково хороши для всех случаев. Попробую разобраться почему. Классический подход — это one-hot кодирование (далее – ohe), когда для каждого уникального значения в категориальном столбце создается новый столбец. Затем эти фиктивные переменные заполняются нулями и единицами — 1 означает ИСТИНА, 0 означает ЛОЖЬ — то есть категории моделируются как взаимоисключающие.
Об этом приеме на практике рассказывали вот здесь, а о том как ohe может повлиять на модель, здесь. Рассмотрю те минусы ohe, которые напрямую связаны с кодированием категориальных переменных.
Минусы one—hot кодирования. Кардинальность и разреженность.
Введу два важных понятия для дальнейших рассуждений: кардинальность и разреженность.
Кардинальность — это характеристика данных, описывающая уникальные значения. Кардинальность высокая при большом количестве уникальных данных, и низкая — при малом. Разреженность — это характеристика данных, которые в большинстве своем имеют нулевые значения.
Во многих наборах данных категориальные столбцы не имеют заданный стандартный вид для небольшого числа категорий. Это создает проблему родственности слов: категории часто несут некоторые морфологические или смысловые связи.
Для переменных с высокой кардинальностью ohe кодирование приводит к векторам признаков высокой размерности. Категориальные переменные высокой кардинальности могут возникать из-за вариативности их строковых представлений – аббревиатуры, специальные символы или опечатки. Такие данные часто содержат очень редкие категории. Тем не менее, эти категории, как правило, имеют общую морфологическую информацию. Это создает вычислительные и статистические проблемы.
Уменьшение размерности матрицы с ohe кодированием может помочь в решении этой проблемы, но риск потери информации при этом остается велик.
Перейду к разреженности. Предположим, что необходимо предсказать зарплату для аналитиков в каждом регионе страны. Это 91 субъект, а если допустить, что, например, город «Санкт-Петербург» может быть представлен как «Питер», «Петербург» и другие вариации, то матрица кодирования кажется пугающе разреженной, это также создает проблемы для обработки и анализа.
Таким образом, рассмотрены две важные проблемы, которые ohe не учитывает при кодировании.
А какие есть альтернативы, и причем тут грязная кошка
Dirty_cat – это библиотека для облегчения предобработки данных категориальных переменных для машинного обучения. Основное достоинство и удобство библиотеки – это устойчивость к морфологическим вариантам (опечатки, падежи и прочее).
Теперь попробую построить небольшой пайплайн и посмотреть, как работает dirty_cat со схожестью слов и как решает проблему разреженных данных.
#Подгрузка библиотек и чтение данных
import dirty_cat
import pandas as pd
from sklearn.manifold import MDS
Кодировать переменные буду на наборе данных, который содержит отзывы на курсы Университета Ватерлоо. Целью создания набора данных было обучение классификатора, способного делать выводы на основе отзывов о курсе, понравился ли курс. Отзывы получены с uwflow.com, а код классификатора находится здесь. Сам датасет размещен на kaggle.
df = pd.read_csv(‘course_data_clean.csv’)
df.head(5) 
Несмотря на то что данные предназначены для NLP модели, некоторые переменные являются хорошим примером того, как может работать dirty_cat. И вот почему: рассмотрю переменную course_title которая описывает название курсов, по которым были собраны отзывы.
df[‘course_title]
len(df[‘course_title’].unique())
Итого: 14838 отзывов по 1730 курсам университета. Для быстроты, удобства и наглядности ограничу выборку данных до первых 2000 отзывов.
df = df.head(2000)
len(df[‘course_title’].unqiue())

len(df[‘course_title’].unqiue())
Теперь в датасете 2000 отзывов по 17 уникальным курсам. Если бы кодировался ohe, то было бы добавлено 16 новых столбцов c нулями – вероятно, для модели это не будет так критично. Но если представить, что в изначальном датасете 1730 курсов, то кодировать пришлось бы все 1730 и добавлять 1729 новых столбцов с нулями. Прогноз становится не таким оптимистичным.
Внимательнее посмотрю на то, как именно dirty_cat ищет схожие значения
from dirty_cat import SimilarityEncoder
srt_courses = df[‘courses_title’].sort_values().unique()
similarity_encoder = SimilarityEncoder()
transformed_values = similarity_encoder.fit_transform(
srt_courses.reshape(-1, 1))
Нанесу пару случайных точек, используя многомерное масштабирование (MDS) для понижения размерности, чтобы понять, что делает similarity encoder:
from sklearn.manifold import MDS
mds = MDS(diddimilarity=’precomputed’, n_init=10, random_state = 42)
dim_df = mds.fit_transform(1 – transformed_values)
print(dim_df.shape)
print(srt_courses)

import numpy as np
from sklearn.neighbors import NearestNeighbors
n_points = 5
random_points = np.random.choice(len(similarity_encoder.categories_[0]),
n_points, replace=False)
nn = NearestNeighbours(n_neighbours=2).fit(transformed_values)
indices_ = nn.kneighbours(transformed_values[random_points])
indices = np.unique(indices_.squeeze())
import matplotlib.pyplot as plt
f, ax = plt.subplots()
ax.scatter(x=dim_data[x, 0], y=dim_data[indices, 1])
for x in indices:
ax.test(x=dim_data[x, 0], y=dim_data[x, 1], s=srt_courses[x],
fontsize=8)

Теперь посмотрю на схожесть названий с помощью 2D матрицы:
f2, ax2 = plt.subplots(figsize(6, 6))
cax2 = ax2.matshow(transformed_value[indices, :][:, indices])
ax2.set_yticks(np.arange(len(indices))
ax2.set_xticks(np.arange(len(indices))
ax2.set_yticklabels(srt_courses[indices], rotation=’30’)
ax2.set_xticklabels(srt_courses[indices], rotation=’60’, ha=’right’)
ax2.xaxis.tick_bottom()
ax2.set_title(‘Similarities’)
f2.colorbar(cax2)
f2.tight_layout()

Первый (рис. 1) и второй (рис. 2) графики показывают, что названия предметов сгруппированы аналогичным образом: микроэкономика имеет связь с макроэкономикой, а линейная алгебра для математиков схожа с линейной алгеброй для математиков-1. При этом интересно, что линейная алгебра для инженеров имеет бОльшую схожесть с химией для инженеров, чем с линейной алгеброй для математиков.
Теперь посмотрю на разреженность данных, которая может быть при использовании ohe, на всем датасете с 14838 отзывами. Перед этим выберу случайную выборку из 20 строк, поскольку в данных первые 20 строк заполнены одним и тем же названием курса.
df = df.sample(20)
from sklearn.preprocessing import OneHotEncoder
n_obs = 20
course_titles = df[‘title’].head(n_obs).to_frame()
categorical_encoder = OneHotEncoder(sparse=False)
one_hoe_encoded = categorical_encoder.fit_transform(course_titles)
f3, ax3 = plt.subplots(figsize(6,6))
ax3.set_title(‘Course titles values, one-hot encoded’)
ax3.axis(‘off’)
f3.tight_layout()
f4, ax4 = plt.subplots(figsize=(6,6))
similarity_encoded = similarity_encoder.fit_transform(course_title)
ax4.matshow(similarity_encoded)
ax4.set_title(‘Course title values, similarity encoded)
ax4.axis(‘off’)
f4.tight_layout()
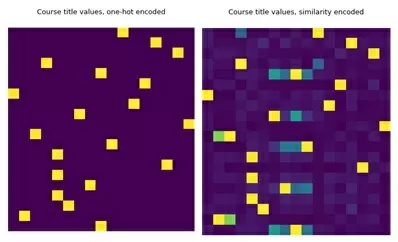
Слева – кодирование ohe, видна сильно разреженная матрица, где желтым указаны заполненные данные, а фиолетовым – незаполненные. Справа – кодирование dirty cat. Теперь матрица имеет более двух цветов – разреженность не такая сильная.
Теперь вернусь к выборке по 17 курсам и применю ohe:
one_hot_encoded = pd.DataFrame(one_hot_encoded)
one_hot_encoded

А вот как выглядят данные с применением similarity encoder:
similarity_encoded = pd.DataFrame(similarity_encoded)
similarity_encoded
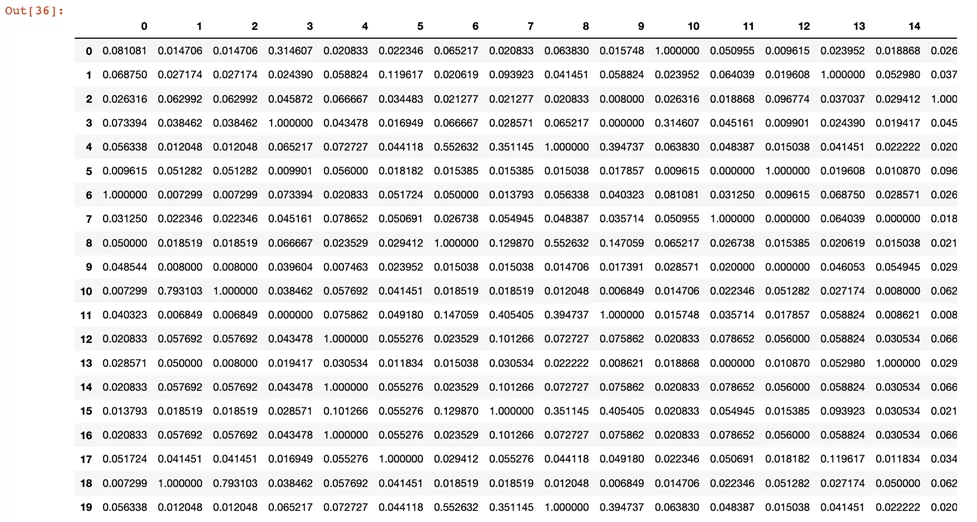
Теперь видно, что кодирование учитывает морфологические и смысловые связи, а также уменьшает разреженность матрицы.
Чтобы точно оценить эффективность предложенного метода, сравню ohe и similarity_encoder. Определю с помощью регрессии количество отзывов, которое будет оставлено на каждый курс. Таргетом будет являться столбец ‘num_reviews’. Эффект от кодировщиков будем определять с помощью коэффициента детерминации, или R2 метрики.
from dirty_cat import SimilarityEncoder
y = df["num_reviews"].values
При этом, остальные столбцы, оставленные для предсказания целевой переменной и в том, и в другом случае закодируем с помощью ohe:
clean = {
"useful": "one-hot",
"easy": "one-hot",
"liked": "one-hot",
}
encode_methods = ["one-hot", "similarity"]
encoders_dict = {
"one-hot": OneHotEncoder(handle_unknown="ignore", sparse=False),
"similarity": SimilarityEncoder(similarity="ngram")
}
Применяю ColumnTransformer для кодирования.
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import RidgeCV
def n_pipeline(encode_method):
transformers = [
(enc + "_" + col, encoders_dict[enc], [col])
for col, enc in clean.items()
]
transformers += [(encode_method, encoders_dict[encode_method], [dirty_column])]
pipeline = Pipeline(
[
("union", ColumnTransformer(transformers=transformers, remainder="drop"))
("clf", RidgeCV()),
]
)
return pipeline
Создаю два пайплайна с использованием ohe и similarity для кодирования ‘course_title’, и с помощью cross_val_score оценю эффективность каждого.
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
dirty = "course_title"
all_scores = dict()
cv = KFold(n_splits=5, random_state=12, shuffle=True)
scoring = "r2"
for method in encode_methods:
pipeline = n_pipeline(method)
scores = cross_val_score(pipeline, df, y, cv=cv, scoring=scoring)
print(f"{scoring} score: mean: {np.mean(scores):.2f}")
all_scores[method] = scores


Теперь видно, что в действительности кодирование с помощью dirty_cat приносит лучшие значения при оценке производительности модели регрессии.
Таким образом, рассмотрен метод кодирования категориальных переменных, который позволяет работать с «грязными» категориальными данными с высокой кардинальностью. Использовать ли dirty cat в своей модели зависит от того, какую задачу решает алгоритм – библиотека может быть очень полезной для больших объемов категориальных данных, предобработка которых может быть проблематичной из-за постоянного их обновления. При этом важно помнить, что далеко не всегда матрица отличается высокой кардинальностью и усложнение кодирования может привести к бесполезному усложнению модели.
Если возможность описанного мной опыта поможет решить вашу текущую задачу, то с дополнительными материалами можно ознакомиться по ссылкам:
1. Документация dirty_cat
2. Формализованная математически задача dirty_cat в оригинальной статье создателей библиотеки
3. Сравнение различных стратегий кодирования категориальных переменных вместе с пятью алгоритмами машинного обучения (лассо, случайный лес, повышение градиента, k-ближайших соседей, метод опорных векторов).
4. Узконаправленное изучение лучших методов кодирования для нейронок.