/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Бывают данные, содержащие сотни, а иногда и тысячи признаков. При этом количество информативных из них оказываются меньше общего числа признаков.
Если работать с такими данными, не производя предварительную обработку, то модели, работающие с такими данными, становятся сложными, и, как следствие, требуют большего количества времени для работы и теряют качество. Проблема быстродействия может быть критичной для рекомендательных систем, а проблема качества свойственна, в принципе, для всех моделей.
Вследствие чего возникает задача снижения размерности. Она заключается в уменьшении общего числа признаков для анализируемого набора данных.
Данную задачу можно разделить на две подзадачи:
- Отбор признаков
- Выделение признаков
Отбор признаков – удаление не информативных признаков из общего набора признаков. Вследствие чего достигается уменьшение времени обучения моделей, повышение точности, а также уменьшение вероятности переобучения.
Выделение признаков – генерация новых признаков на основе имеющихся. Новые признаки полностью описывают исходный набор данных и при этом уменьшают его размерность.
Я подробно расскажу о задаче отбора признаков. Существует множество методов для решения данной задачи.
Одними из самых простых решений являются одномерные методы. В их основе лежит проверка наличия связи между каждым признаком и целевой переменной. В качестве примеров таких методов может быть коэффициент корреляции, визуальные методы (например Partial dependence plots / Individual conditional expectation plot) и другие.
Данные методы достаточно просты. Однако они не учитывают сложные связи. Может оказаться так, что признаки могут влиять на целевую переменную в совокупности, а по отдельности не влиять вовсе.
Достичь приемлемого решения данной задачи можно при помощи моделей машинного обучения. Например, это можно сделать при помощи следующих алгоритмов:
- Линейная регрессия, использующая L1 регуляризацию (или регрессия по методу Лассо)
- Случайный лес
Решается классическая задача машинного обучения – бинарная классификация / регрессия.
Для удобства и наглядности сгенерируем синтетические данные. Создадим два набора данных: в одном целевая переменная находится в линейной зависимости от независимых факторов, в другом зависимость между целевой переменной и факторами сильно нелинейная.
Создаю данные при помощи метода make_regression из библиотеки sklearn, который генерирует выходные данные путем применения случайной линейной регрессионной модели. Данный метод позволяет задать количество информативных признаков. В результате сформированные признаки линейно зависят от целевой переменной.
import numpy as np
from sklearn.datasets import make_regression
# генерирую данные
X, y = make_regression(
# количество объектов
n_samples=500,
# количество признаков
n_features=1_000,
# количество информативных признаков
n_informative=50,
random_state=13,
# не перемешиваем признаки,
# чтобы информативные были первыми по счёту
# в списке признаков X
shuffle=False
)
Отберём признаки при помощи регрессии по методу Лассо. Данная модель использует L1 регуляризацию для назначения штрафов незначащим весам. В результате обучения коэффициенты незначащих признаков становятся равны нулю, что позволяет проводить отбор признаков (в отличии от L2 регуляризации, в которой коэффициенты признаков могут иметь значение, близкое к нулю, но не равное). Гиперпараметром для модели с данной регуляризацией выступает вещественный коэффициент α. Чем больше данный коэффициент, тем больше признаков будет отсеяно.
Обучаем модель линейной регрессии по методу Лассо на созданных данных:
from sklearn import linear_model
# создаю объект линейной регрессии
clf = linear_model.Lasso(alpha=0.1)
# обучаю модель на созданных данных
clf.fit(X, y)
Проверяем, сколько и какие признаки модель посчитала информативными:
count = 0
for i in clf.coef_:
if i != 0:
count += 1
# Модель посчитала информативными 56 признаков
print(f'Модель отобрала {count} признаков; настоящее количество информативных признаков: 50')
# Посмотрим те ли коэффициенты модель посчитала информативными
# Выведем первые 55 значений коэффициентов
print(clf.coef_[:55])
Первые 55 коэффициентов обученной модели:
[77.16829205, 11.13130606, 83.74007306, 84.92163633, 88.3070247 ,
43.85128833, 75.10452571, 72.24055137, 7.26734715, 37.76154505,
79.34083734, 93.15009795, 70.124309 , 84.10226918, 76.74902582,
49.13668897, 84.19688431, 8.01864363, 88.01572553, 63.22459662,
40.52552127, 40.08958411, 10.29463689, 80.31732905, 32.78441928,
38.05168357, 79.38531453, 90.66634756, 55.26937866, 76.96427204,
3.28150743 , 41.95600616, 17.74070539, 48.00396155, 95.05091598,
19.7545652 , 4.02660438, 70.83870363, 45.44972253, 0.30418389,
39.4490068 , 24.68096413, 33.62103829, 14.00417406, 1.2900499 ,
76.9976594 , 79.8189025 , 33.72997483, 7.97815334, 79.20097346,
-0. , -0. , -0. , -0. , -0. ]
В результате модель посчитала информативными 56 признаков. На выводе первых 55 коэффициентов видно, что модель отобрала первые 50 признаков, так как их коэффициенты ненулевые. При этом они, действительно, являются значимыми (т.к. мы указали, что первые 50 будут значимые при генерации набора данных). Также модель посчитала значимыми 6 шумовых признаков.
Помимо отбора признаков, данная модель позволяет сравнивать значимость признаков между собой. Но для этого данные необходимо стандартизировать, так как изначально они могут быть измерены в разных шкалах.
Стандартизируем данные и обучаем данную модель для сравнения признаков между собой:
from sklearn import linear_model
from sklearn.preprocessing import StandardScaler
# создаю объект стандартизатора
scaler = StandardScaler()
# стандартизую данные
X = scaler.fit_transform(X)
# создаю объект линейной регрессии c параметром alpha=0.1
clf = linear_model.Lasso(alpha=0.1)
# обучаю модель на созданных данных
clf.fit(X, y)
# вывод коэффициентов для сравнения
# [78.74062673 11.16037783 82.68098786 ... -0. -0. 0.]
print(clf.coef_)
Таким образом, модель линейной регрессии позволяет отобрать признаки, находящиеся в линейной зависимости от целевой переменной.
Стоит отметить, что данные, в которых присутствует нелинейная зависимость между целевой переменной и независимыми факторами, чаще встречаются на практике, чем рассмотренный ранее набор данных.
С нахождением таких зависимостей хорошо справляется алгоритм случайного леса.
Воспользуемся методом make_classification из библиотеки sklearn. Данный метод генерирует кластеры нормально распределенных точек в вершинах гиперкуба. Количество вершин куба совпадает с количеством информативных признаков. Это вводит взаимозависимость между этими признаками и добавляет к данным различные виды дополнительного шума.
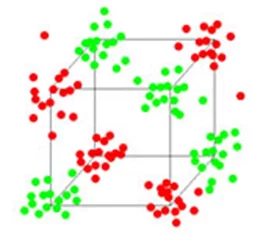
Таким образом сгенерированные данные имеют сильную нелинейную зависимость.
from sklearn.datasets import make_classification
X, y = make_classification(
n_samples=1000,
n_features=100,
n_informative=5,
n_classes=2,
# 2 * class_sep = длина стороны гиперкуба
class_sep=1.0,
hypercube=True,
shuffle=False,
random_state=13
)
Приступим к обучению моделей. Для начала разобьем выборку на обучающую и тестовую:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.33,
random_state=42
)
Обучим модель случайного леса на наших данных:
from sklearn.ensemble import RandomForestClassifier
# Создаем экземпляр классификатора
# с количеством деревьев равным 2023
clf = RandomForestClassifier(n_estimators=2023)
# Замеряю среднее время обучения модели
%timeit clf.fit(X_train, y_train)
Среднее время работы обучения = 9.52 s ± 310 ms.
Проверим, насколько хорошо модель описывает данные:
accuracy_score(y_test, clf.predict(X_test))Результат: accuracy = 0.78. Модель правильно описывает 78% тестовых данных. Попробуем улучшить значение метрики при помощи отбора признаков.
Алгоритм случайного леса использует коэффициенты Джини для того, чтобы измерить, как снижается метрика accuracy модели при исключении определенного признака. Чем больше значение коэффициента Джини, тем признак более значимый.
Посмотрим на 10 наиболее важных признаков, которые посчитал случайный лес:
plt.figure(num=None, figsize=(20,8), dpi=80, facecolor='w', edgecolor='k')
feat_importances = pd.Series(clf.feature_importances_)
feat_importances.nlargest(10).plot(kind='barh')
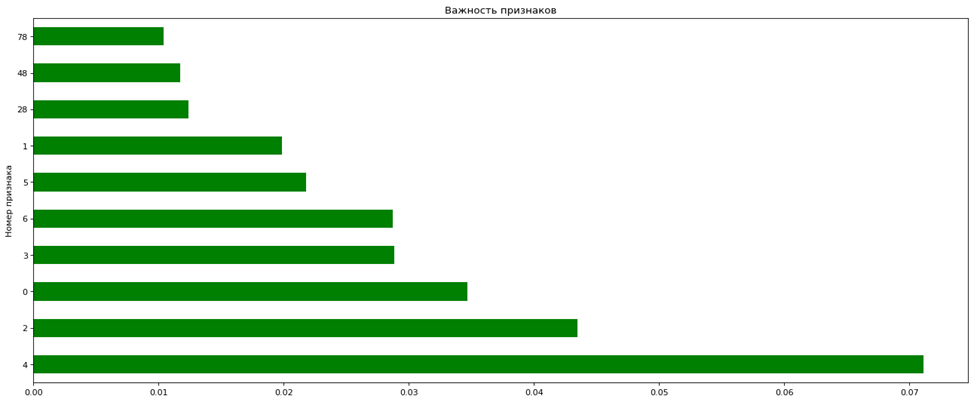
Теперь мы можем установить порог для отбора признаков. Это может быть вещественное число. Признаки, значимость которых меньше данного порога, будут отсеяны. Или же мы можем выбрать конкретное число нужных нам признаков.
Отберем 10 наиболее важных признаков:
# получим индексы нужных признаков
imp_features_idx = feat_importances.sort_values()[-10:].index
Снова обучим модель случайного леса на данных с отобранными признаками:
clf = RandomForestClassifier(n_estimators=2023)
%timeit clf.fit(X_train[:, imp_features_idx], y_train)
Среднее время работы обучения = 4.26 s ± 20.5 ms.
Проверим метрику accuracy:
accuracy_score(y_test, clf.predict(X_test[:, imp_features_idx]))Результат: accuracy = 0.88. Что уже является хорошим результатом. Модель правильно предсказывает класс для 88% тестовой выборки.
В результате отбор признаков позволил уменьшить время обучения модели более чем в два раза и повысить значение метрики на 10%. Из чего можно сделать вывод о практической пользе отбора признаков.
Резюмирую основные моменты данного подхода. Так как изначально неизвестно, какая зависимость присутствует в наборе данных между целевой переменной и независимыми факторами, я бы рекомендовал отбирать признаки при помощи алгоритма случайного леса. Однако, если у вас есть основания считать, что в анализируемых данных присутствует линейная зависимость, то лучше с отбором признаков справится модель линейной регрессии по методу Лассо.
А какие методы для отбора признаков используете вы?