/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Наверняка у каждого хотя бы раз было такое желание, чтоб написать комментарий и получить массу лайков за него. Как никак, человек существо социальное и одобрение этого самого социума порой очень хочется. Но тут возникает вопрос: а что нужно написать, чтобы получить максимальное количество лайков? И для этого можно использовать машинное обучение! В любой непонятной ситуации применяй машинное обучение.
На самом деле, это довольно непростая задача, требующая не только обработки комментариев, но и определения контекста, в котором он размещён. Но никто же не заставляет нас собирать квантовый суперкомпьютер, верно? Для простого обзора можно обойтись и более простыми инструментами.
Итак, для начала нужно собрать данные для обучения. В качестве источника таковых возьмём площадку YouTube. Уж где где, а на YouTube полно самых различных комментариев. К тому же в сообществах популярных каналов очень распространены локальные мемы, то есть некоторые слова и словосочетания, имеющие некий знаковый символ в этом сообществе. Употребление таких локальных мемов при написании комментариев, теоретически, должно увеличивать количество лайков, а значит несколько упрощать нам задачу.
Ключевым параметром будет выступать, естественно, количество лайков комментария, а признаками будут, во-первых, сам текст комментария, а во-вторых, разница между датой публикацией видео и комментария, так как очевидно, что чем позже от даты выхода видео размещён комментарий, то тем меньше лайков он соберёт. По второму признаку могут быть исключения в виде видео годовалой или более давности, которые по какой-то причине YouTube начал выдавать в рекомендациях у пользователей, после чего в комментариях к оным видео начинается активность, но мы подобные брать не будем.
Для извлечения данных воспользуемся YouTube Data API v3. Первым делом надо получить API ключ. Это сделать просто, однако весьма заковыристо и сходу непонятно, поэтому быстро пробегусь по шагам:
- Перейти на сайт Console Google Cloud Platform (console.cloud.google.com)
- Зайти под аккаунтом Google
- Создать проект
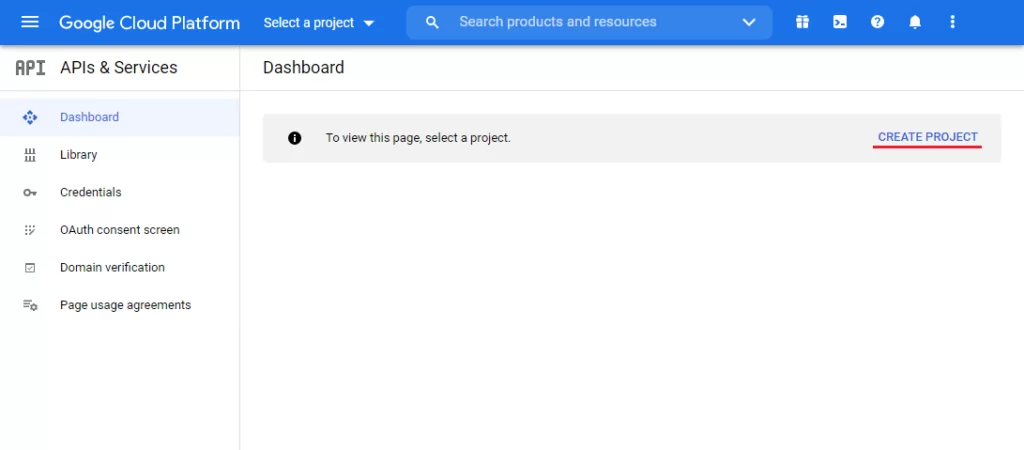
4. Создать новый API
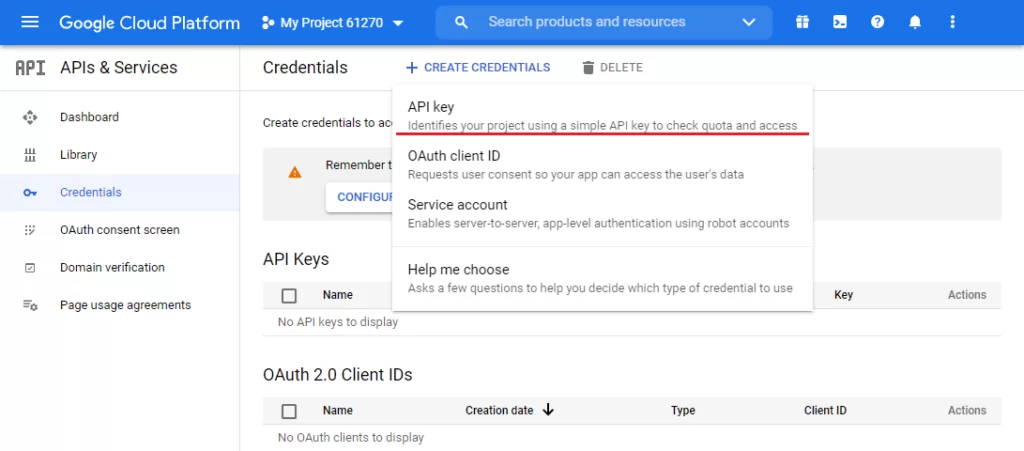
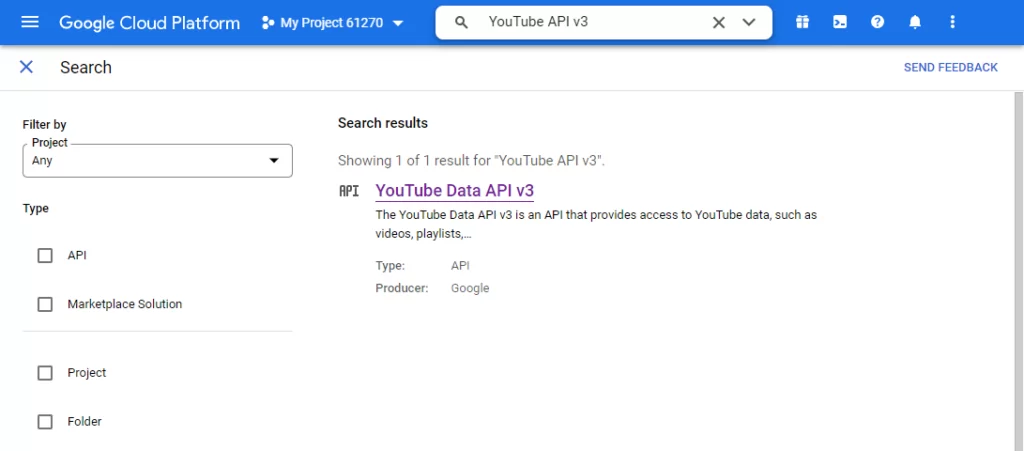
5. Найти YouTube API v3
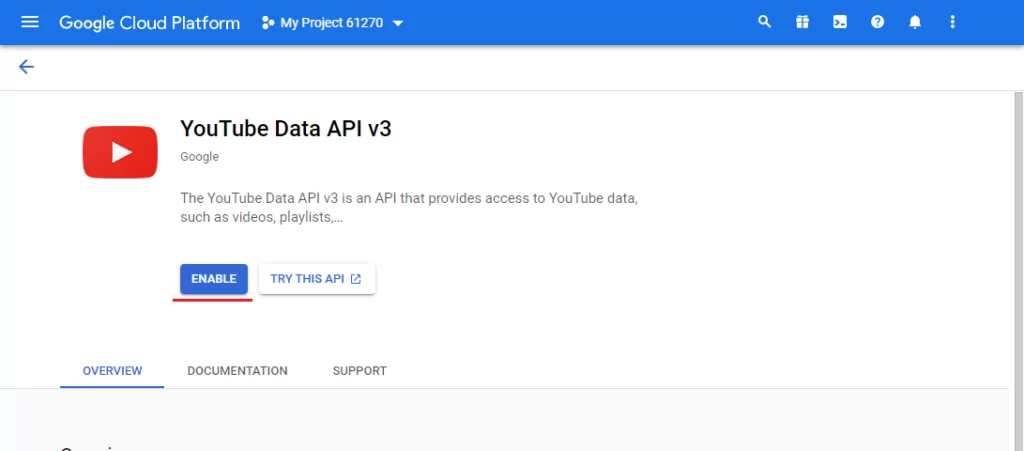
6. И включить его
Также, чтобы пользоваться этим API, необходимо скачать библиотеку google-api-python-client:
pip install google-api-python-clientПосле получения ключа API можно начинать парсить комментарии. В качестве цели возьмем ролики популярного в ру сегмент канала “Utopia Show”. Вначале загрузим нужные библиотеки и определим необходимые переменные:
import os
import googleapiclient.discovery
import csv
import tqdm
API_KEY = "your_API_key"
VIDEO_IDS = ["Ywpd8M6wfHc", "sskg_JguH28", "JDKqXmOX52Q", "k8FIVugHGSg"]
COMMENT_COUNT = 1000
MAX_RESULT = 100
Теперь напишем функцию для парсинга комментариев по id видео, под которыми они размещены:
# Функция для скачивания комментариев по id видео
def get_comments(video_id, nextPageToken=None):
# Disable OAuthlib's HTTPS verification when running locally.
# *DO NOT* leave this option enabled in production.
os.environ["OAUTHLIB_INSECURE_TRANSPORT"] = "1"
api_service_name = "youtube"
api_version = "v3"
youtube = googleapiclient.discovery.build(
api_service_name, api_version, developerKey = API_KEY)
request = youtube.commentThreads().list(
part="id,snippet",
maxResults=MAX_RESULT,
pageToken=nextPageToken,
videoId=video_id,
order="relevance"
)
response = request.execute()
return response
Ещё одну функцию для получения даты публикации видео по её id:
# Функция для скачивания даты выхода видео по id
def get_video_date_published(video_id):
# Disable OAuthlib's HTTPS verification when running locally.
# *DO NOT* leave this option enabled in production.
os.environ["OAUTHLIB_INSECURE_TRANSPORT"] = "1"
api_service_name = "youtube"
api_version = "v3"
youtube = googleapiclient.discovery.build(
api_service_name, api_version, developerKey = API_KEY)
request = youtube.videos().list(
part="snippet,contentDetails,statistics",
id=video_id
)
response = request.execute()
return response.get("items")[0].get("snippet").get("publishedAt")
Ну и наконец, основную функцию, которая использует две предыдущие для парсинга данных и записи их в csv файл:
def youtube_comment_parser():
with open('comments.csv', 'w', encoding="utf-8") as csv_file:
writer = csv.writer(csv_file, quoting=csv.QUOTE_ALL, lineterminator='\r')
# Заголовки столбцов
names = ['textOriginal',
'authorDisplayName',
'likeCount',
'publishedAt',
'videoPublishedAt']
writer.writerow(names)
iteration_count = int(COMMENT_COUNT/MAX_RESULT)
for video_id in tqdm.tqdm(VIDEO_IDS):
# Скачиваем комментарии
items = []
nextPageToken = None
for _ in range(iteration_count):
response = get_comments(video_id, nextPageToken)
nextPageToken = response.get("nextPageToken")
items = items + response.get("items")
# Дата публикации видео
videoPublishedAt = get_video_date_published(video_id)
# Сохраняем комментарии и дату публикации видео в файл csv
for item in items:
topLevelComment = item.get("snippet").get("topLevelComment").get('snippet')
row = [topLevelComment.get('textOriginal'),
topLevelComment.get('authorDisplayName'),
topLevelComment.get('likeCount'),
topLevelComment.get('publishedAt'),
videoPublishedAt]
writer.writerow(row)
После того, как получили данные начинаем их обрабатывать. Поместим данные из ранее полученного файла в дата фрейм:
import pandas as pd
df = pd.read_csv('comments.csv')
Сначала посмотрим на гистограмму количества лайков:
df['likeCount'].hist(bins=50)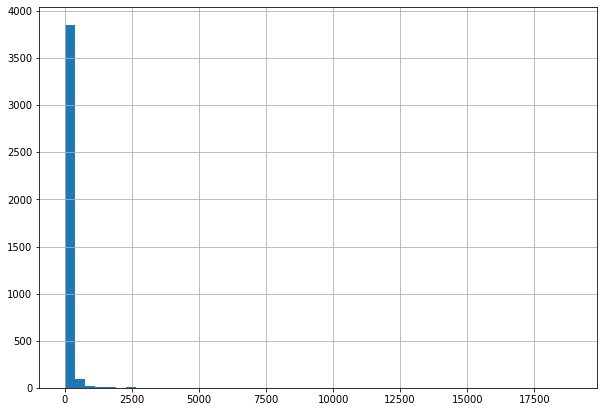
Как видно, число комментариев с нулевым или близким количеством лайков зашкаливает, а это плохо для модели, так как модель будет стараться выдать нулевое значение, угадывая чуть ли не в половине случаев. Поэтому, чтобы исправить это, применим к значениям количества лайков функцию log(x + 1). Прибавление единицы здесь нужно, чтобы не было проблем с нулевыми значениями. Эта функция уже реализована в библиотеке numpy, ею и воспользуемся:
import numpy as np
df['logLikeCount'] = np.log1p(df['likeCount'])
В дальнейшем, чтобы привести подобные значения обратно к числу лайков, нужно использовать функцию np.expm1.
Далее, обрабатываем даты публикаций комментария и видео и находим разницу между ними в секундах, здесь всё просто:
# Приведение даты к типу datetime
df['publishedAt'] = pd.to_datetime(df['publishedAt'], format="%Y-%m-%dT%H:%M:%SZ")
df['videoPublishedAt'] = pd.to_datetime(df['videoPublishedAt'], format="%Y-%m-%dT%H:%M:%SZ")
# Разница между датами публикацией комментария и видео
df['publishedDifference'] = (df['publishedAt'] - df['videoPublishedAt']).apply(lambda x: x.total_seconds()).astype(int)
Теперь необходимо обработать текст — в нём нужно убрать знаки препинания, стоп-слова, выделить слова с одной основой и привести всё это в пригодный для машины вид. Чтобы убрать знаки препинания, а заодно и любые другие символы кроме русских букв, можно воспользоваться регулярными выражениями:
import re
regex = re.compile('[^а-я А-Я]')
text = regex.sub(' ', text)
Для отбора стоп-слов есть специальная библиотека nltk:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('stopwords')
nltk.download('punkt')
word_tokens = word_tokenize(text)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
А для приведения слов к своей основной форме можно пропустить их через стемминг:
from nltk.tokenize import word_tokenize
from nltk.stem.snowball import SnowballStemmer
word_tokens = word_tokenize(text)
filtered_sentence = [stemmer.stem(w) for w in word_tokens]
Объединяя всё вышеуказанное, получаем функцию, обрабатывающая все тексты поступающие ей на вход:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.snowball import SnowballStemmer
import re
import tqdm
nltk.download('stopwords')
nltk.download('punkt')
# Функция обрабатывает тексты для дальнейшего использования
def process_text(texts):
stemmer = SnowballStemmer(language='russian')
stop_words = set(stopwords.words('russian'))
regex = re.compile('[^а-я А-Я]')
process_texts = []
for text in tqdm.tqdm(texts):
text = text.lower()
# Удаляет любые символы, кроме русских букв
text = regex.sub(' ', text)
# Разбивает текст на отдельные слова
word_tokens = word_tokenize(text)
# Убирает стоп слова и пропускаем через стемминг оставшиеся
filtered_sentence = [stemmer.stem(w) for w in word_tokens if not w in stop_words]
process_texts.append(' '.join(filtered_sentence))
return process_texts
df['textProcessed'] = process_text(df['textOriginal'])
Осталось только привести слова в удобоваримый для компьютера вид. С этим нам поможет векторизация, однако здесь есть один нюанс — векторизатор нужно тренировать только на обучающей выборке, поэтому его применим, когда будем делить данные на обучающие и валидационные. Кстати о них:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
X = df[['textProcessed', 'publishedDifference']]
y = df['logLikeCount']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Векторизация обработанных слов
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train['textProcessed'])
X_test_vec = vectorizer.transform(X_test['textProcessed'])
# Изменяет размерность массива разности дат публикаций, чтобы соединить с векторизированит текстами
X_train_pub = np.array(X_train['publishedDifference']).reshape((-1,1))
X_test_pub = np.array(X_test['publishedDifference']).reshape((-1,1))
# Объединяет вектора слов и разности дат публикаций
X_train = np.append(X_train_vec.toarray(), X_train_pub, axis=1)
X_test = np.append(X_test_vec.toarray(), X_test_pub, axis=1)
Ну и наконец, ради чего всё это затевалось, обучение модели. Обучать будем на модели градиентного бустинга из библиотеки CatBoost. Модель возьмём без дополнительных параметров, укажем лишь случайное зерно и функцию потерь в виде MAE:
from catboost import CatBoostRegressor
catboost = CatBoostRegressor(loss_function='MAE', random_seed=0, silent=True)
catboost.fit(X_train, y_train)
pred = catboost.predict(X_test)
Для оценки качества модели используем MAE. Как мы помним, ключевой параметр — количество лайков — был преобразован с помощью функции np.log1p, поэтому применение MAE сразу к предсказанным данным нам почти ничего не даст. Для наглядности сначала преобразуем данные, а уже потом применем MAE:
from sklearn.metrics import mean_absolute_error
pred_int = np.expm1(pred).astype(int)
y_test_int = np.array(np.expm1(y_test).astype(int))
mae = mean_absolute_error(pred_int, y_test_int)
print('MAE =', mae)
output:
MAE = 56.221666666666664
Ещё для полноты картины выведем первые 30 предсказанных значений и реальных:
print("pred - true")
for i in range(30):
print(f"{pred_int[i]:4} - {y_test_int[i]}")
output:
pred - true
0 - 5
0 - 0
0 - 0
0 - 0
0 - 0
0 - 0
69 - 10
0 - 0
0 - 1
0 - 20
0 - 1
0 - 0
0 - 0
0 - 1
0 - 0
0 - 0
0 - 0
56 - 104
0 - 0
0 - 23
0 - 0
0 - 0
0 - 0
52 - 5737
0 - 0
0 - 1
0 - 3
0 - 0
0 - 0
0 - 0
Как видно, данная модель хорошо предсказывает те комментарии, которые в принципе не наберут лайки или наберут очень мало. В дальнейшем, чтобы нарастить точность модели на остальных комментариях, можно учитывать контекст, в котором они размещены.