/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Дана классическая задача по тональности текста – поиск в тексте негатива. Для размеченных данных задача сводится к простой бинарной классификации, но данные не всегда могут быть размечены изначально.
Рассмотрим пример. Дан датасет c 568454 строками с отзывами на товары интернет-магазина (исходные данные взяты с kaggle – Amazon Fine Food Reviews). В исходной информации имеется 10 колонок информации.
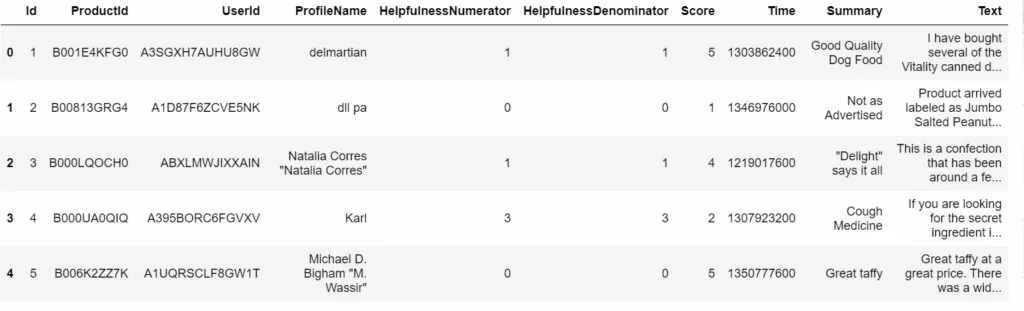
Нас интересует текст отзыва (представлен на английском языке) и оценка покупателя (от 1 до 5). Создадим датафрейм с двумя этими колонками:
import pandas as pd
df = pd.read_csv('Reviews.csv')
df = df[['Text', 'Score']]
В упрощенном случае для обучения можно использовать оценку покупателя для поиска негатива – логично, что к товарам с низкими оценками чаще оставляют негативные отзывы. Но мы попробуем определить тональность комментария исходя из лексики. Для этого воспользуемся словарем эмотивной лексики. Он представляет собой размеченный по эмоциональной окраске набор слов. Используем словарь библиотеки nltk и создаем два списка – с позитивными и негативными словами.
import nltk
from nltk.corpus import opinion_lexicon
nltk.download('opinion_lexicon')
pos_list = set(opinion_lexicon.positive())
neg_list = set(opinion_lexicon.negative())
Для определения негативного комментария воспользуемся простой логикой и будем считать, что комментарий негативный если число слов с негативной лексикой в нем больше, чем число слов с положительной лексикой. На основании этой логики напишем функцию:
def negative_score(row):
pos = 0
neg = 0
for word in row['list_lemm']:
if word in pos_list:
pos+=1
if word in neg_list:
neg+=1
if neg>pos:
return 1
else:
return 0
Данная функция будет проходить по словам в комментарии датафрейма и возвращать метку 1, если комментарий негативен или 0, если негатива в комментарии нет. Но для того что бы применить функцию к датафрейму необходимо привести комментарий из строкового вида в список лемм. Для этого так же напишем функцию:
import re
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def lemmatize(text):
pattern = r'[^a-zA-Z]
clear_text = re.sub(pattern, " ", text)
words = clear_text.split()
lemms = list()
for word in words:
lemm = lemmatizer.lemmatize(word)
lemms.append(lemm)
return(lemms)
Данная функция очищает текст от нежелательных знаков с помощью регулярного выражения c помощью библиотеки re, затем разбивает строку на отдельные слова и приводит каждое слово к начальной форме с помощью инструмента WordNetLemmatizer() библиотеки nltk и возвращает список лемм. Применим данную функцию к корпусу имеющегося у нас текста и затем применим функцию оценки:
corpus = df['Text']
df['lemmatized_text'] = corpus.apply(lambda x: lemmatize(x))
df['neg'] = df.apply(negative_score, axis = 1)
Таким образом получаем оценку комментария. Теперь попробуем провести небольшую проверку. Сравним полученную оценку с оценкой покупателя. Для этого добавим еще один столбец в датафрейм:
import numpy as np
df['negat'] = np.where(df['Score'] <=2, 1, 0)
Оценка покупателя по пятибалльной шкале нас больше не интересует. Конечный датафрейм имеет следующий вид:
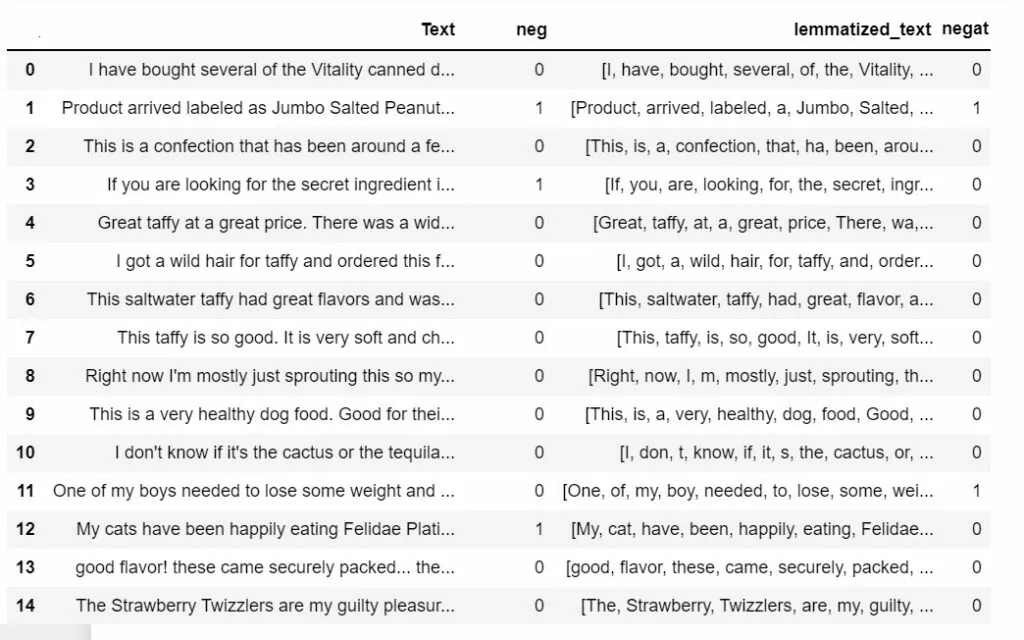
Теперь сравним эти оценки. Например, условно, так:
from sklearn.model_selection import accuracy_score
accuracy_score(df['neg'], df['negat'])
В данном примере значение точности = 0.8461. Можно сделать вывод, что словарь окрашенных слов довольно неплохо справляется с задачей поиска негатива. Также значение можно улучшить, есть использовать специальные тематические словари, учитывающие контекст и тематику комментария.