/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 2 мин.
Рассмотрим sentence tokenizer’ы с точки зрения корректности работы: насколько правильно детектирует предложения конкретный анализатор в сравнении с эталонным разбиением. Также немаловажным критерием при оценке работы таких модулей является скорость работы алгоритма выделения токенов, поэтому этот параметр также будет собираться для дальнейшего анализа.
Для оценки показателей был собран корпус из русских текстов разных по стилистике. Собранный корпус предварительно промаркирован разделителем предложения, и написан код на python для трех sentence tokenizer’ов: RAZDEL, NLTK и rusenttokenize из пакета DeepPavlov.
Код для анализа библиотек представлен ниже.
import razdel
import nltk
from corus import load_ud_syntag
from rusenttokenize import ru_sent_tokenize
import time
path = r'PATH_TO_COPUS.txt'
records = load_ud_syntag(path)
texts = [i.text for i in records]
razdel_time =0
nltk_time = 0
deeppavlov_time = 0
for i in range(10000):
start_time = time.time()
razdel_sentences = list(razdel.sentenize(' '.join(texts)))
razdel_time += time.time() - start_time
start_time = time.time()
nltk_sentences = list(nltk.sent_tokenize(' '.join(texts),language='russian'))
nltk_time += time.time() - start_time
start_time = time.time()
deeppavlov_sentences = list(ru_sent_tokenize(' '.join(texts)))
deeppavlov_time += time.time() - start_time
avg_razdel_time = razdel_time/100000
avg_nltk_time = nltk_time/100000
avg_deeppavlov_time = deeppavlov_time/100000
print('-'*80)
print('{:15} | {:15} | {:17} | {:26}'.format('БИБЛИОТЕКА','КОЛ-ВО ОШИБОК','ПРОЦЕНТ ОШИБОК','ВРЕМЯ ВЫПОЛНЕНИЯ (С)'))
print('-'*80)
print('{:15} | {:15} | {:15.2%} | {:20.6f}'.format('RAZDEL',len(texts)-len(razdel_sentences),(1-len(razdel_sentences)/len(texts)),avg_razdel_time))
print('-'*80)
print('{:15} | {:15} | {:15.2%} | {:20.6f}'.format('NLTK',len(texts)-len(nltk_sentences),(1-len(nltk_sentences)/len(texts)),avg_nltk_time))
print('-'*80)
print('{:15} | {:15} | {:15.2%} | {:20.6f}'.format('DEEPPAVLOV',len(texts)-len(deeppavlov_sentences),(1-len(deeppavlov_sentences)/len(texts)),avg_deeppavlov_time))
print('-'*80)
Результаты работы кода можно увидеть в представленной ниже таблице.
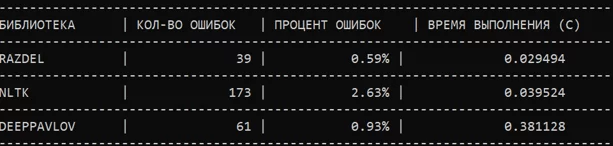
Таким образом, составленная таблица, позволяет сделать однозначный вывод, что наилучшей практикой на данный момент является использование лексического анализатора из библиотеки RAZDEL, поскольку этот tokenizer показывает наименьший процент ошибок в определении предложений, а также показывает наибольшую скорость работы. Ведь именно эти показатели очень важны для решения NLP задач, особенно на данных гораздо большего объема.