/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Начнем с идеи. Помните, я демонстрировал небольшой очерк на тему парсинга сайтов в контексте аудита? Не помните – вот ссылка: https://newtechaudit.ru/parsing-i-audit/. Представьте теперь, что данные с сайта получены и готовы к обработке. К примеру, у вас есть желание выявить негативные комментарии со страницы отзывов и предложений, собрать статистические показатели успехов рекламных кампаний, кластеризовать по темам тексты заявлений или просто подготовить контент сайта к более детальной машинной или ручной аналитике. Но что может произойти? Люди любят писать с ошибками в орфографии или пунктуации, баловаться со склонениями или злоупотреблять служебными частями речи даже в официальных документах. Это серьезная подножка работе классификаторов, кластеризаторов, аналитиков и любителей чистого русского языка. Что же делать? Приведем далее некоторые базовые методы преображения текста и его подготовки к анализу. Как это делать? Воспользуемся Python и добавим немного математики!
Импортируем, конечно, нужные библиотеки (системные и внешние). При этом будем использовать новый модный проект natasha в качестве помощника:
import numpy as np
import os
import pandas as pd
import string
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from pymorphy2 import MorphAnalyzer
from natasha import NamesExtractor, MorphVocab, DatesExtractor, MoneyExtractor, AddrExtractor
Для начала самый простой этап предобработки, то есть нормализация текста. Чтобы при дальнейшем исследовании слова «аудитор» и «аудиторы» не были восприняты алгоритмом как разные по смыслу, воспользуемся этой парой строк:
morph = MorphAnalyzer()
def pymorphy_preproc(line):
return [morph.parse(word)[0].normal_form for word in line]
Следующая базовая вещь – это удаление знаков препинания, приведение слов к нижнему регистру и, конечно, удаление цифр:
line = ''.join(i for i in line if not i.isdigit())
line = line.translate(str.maketrans('', '', string.punctuation))
line = line.lower()
Теперь небольшой, но важный фокус: удаление «стоп-слов». Этим термином мы назовем часто встречающиеся служебные части речи, общеупотребимые слова, просторечия. В общем, все, что может загрязнить исследуемый текст. К сожалению, четко определенного набора «стоп-слов» в мире не существует, так что мы принесем свой собранный заранее words_pack и очистим от его контента текст:
def del_stopwords(line, words_pack):
filtered_line = []
for word in line.split(' '):
if word not in words_pack:
filtered_line.append(word)
return filtered_line
Или же можно взять чужой, уже готовый набор стоп-слов, всего лишь сделав нужный импорт:
from nltk.corpus import stopwords
words_pack = stopwords.words("russian")
Теперь усложним задачу. Выделим при помощи natasha «именованные сущности», то есть синтаксические конструкции, которые могут, напротив, помочь с задачей анализа. Согласитесь, алгоритму гораздо понятнее будет тэг «географическое наименование», чем один из многочисленных сложных «г. Саров, Нижегородская обл.». Рассмотрим выделение имен, дат, финансов и адресов:
morph_vocab = MorphVocab()
def sub_names(line):
line = str(line)
extractor = NamesExtractor(morph_vocab)
matches = extractor(line)
if len([_.fact.as_json for _ in matches]) == 3:
return line + ' NAME_FOUNDED'
return line
def sub_dates(line):
extractor = DatesExtractor(morph_vocab)
matches = extractor(line)
if len([_.fact.as_json for _ in matches]):
return line + ' DATE_FOUNDED'
return line
def sub_money(line):
extractor = MoneyExtractor(morph_vocab)
matches = extractor(line)
if len([_.fact.as_json for _ in matches]):
return line + ' MONEY_FOUNDED'
return line
def sub_addr(line):
extractor = AddrExtractor(morph_vocab)
matches = extractor(line)
if len([_.fact.as_json for _ in matches]):
return line + ' ADDR_FOUNDED'
return line
Результат работы алгоритмов по извлечению сущностей таков, к примеру:
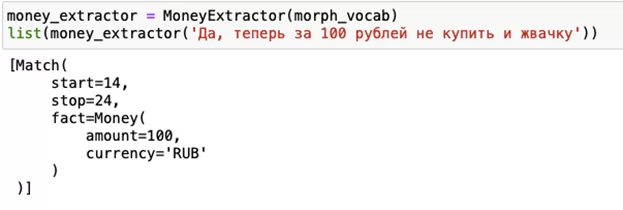
А если мы захотим кастомный extractor? Легко с помощью MorphVocab и yargy. Нужно просто создать нужную сущность:
from yargy.interpretation import fact
dog_breed = fact(
'dog_breed',
['name']
)
class dog_breed(dog_breed):
type = 'Порода песика'
value = value('name')
Итак. При решении задачи классификации, ради которой все это и делается, масса различных уникальных адресов, имен и т.д. будет отброшена, так что мы будем диагностировать присутствие сущностей в предложении. Соберем наши способы обработки в одну функцию.
def preproc_line(line, stop_words):
line = ''.join(i for i in line if not i.isdigit())
line = line.translate(str.maketrans('', '', string.punctuation))
line = line.lower()
if len(stop_words):
line = del_stopwords(line, stop_words)
line = pymorphy_preproc(line)
line = ' '.join(line)
line = sub_names(line)
line = sub_dates(line)
line = sub_addr(line)
line = sub_money(line)
return line
Посмотрим, как это работает:

Видно, что наш алгоритм, во-первых, нормализовал, почистил и исправил контент текста, а, во-вторых, обнаружил в нем адрес!
Или попробуем найти в тексте имя:
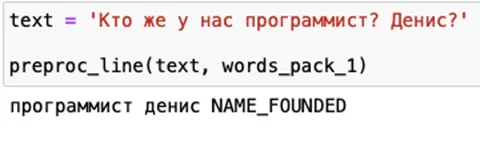
И, наконец, самое сложное. Векторизуем наш текстовый корпус и выделим в нем биграммы! Биграммы – это интересные помощники в анализе, любимые структуры лингвистов, а именно –
конструкции из неразделимых по смыслу комбинаций слов. К примеру, биграммой будем считать словосочетание «внутренний аудит». Представим код:
vectorizer = TfidfVectorizer(ngram_range = (1, 2))
X_train = vectorizer.fit_transform(X_train)
Итак, мы использовали почти все классические способы предобработки текста для лингвистических и статистических исследований. Что еще можно? Выделение эмоций, исправление синтаксических ошибок, игры с токенизаторами. Что же дальше? Тематическое моделирование, задачи классификации, сбор и анализ данных, LDA, ARTM, TopicNet. Ценно ли это? Безусловно! Подобрать врчную бесчисленное множество регулярных выражений и костылей для фиксации всех факторов при анализе текстовых копусов не получится никогда.